lion pytorch
0.2.3
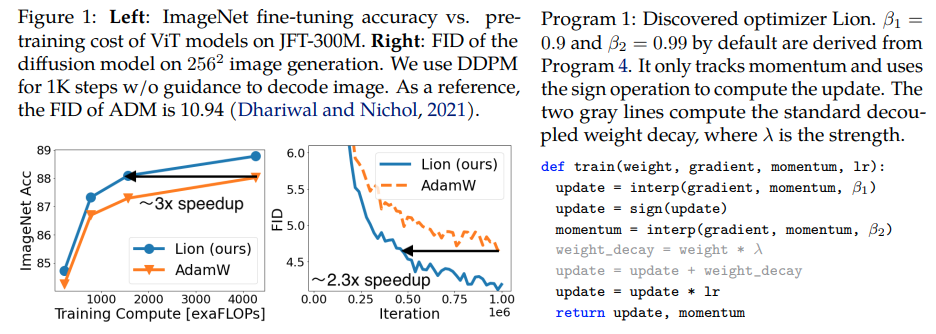
Lion, Evo L ved S i gn M o me n tum, nuevo optimizador descubierto por Google Brain que supuestamente es mejor que Adam(w), en Pytorch. Esta es casi una copia directa de aquí, con algunas modificaciones menores.
Es tan simple que también podemos hacerlo accesible y utilizado por todos lo antes posible para entrenar algunos modelos geniales, si realmente funciona.
Tasa de aprendizaje y disminución del peso: los autores escriben en la Sección 5. Based on our experience, a suitable learning rate for Lion is typically 3-10x smaller than that for AdamW. Since the effective weight decay is lr * λ, the value of decoupled weight decay λ used for Lion is 3-10x larger than that for AdamW in order to maintain a similar strength. El valor inicial, el valor máximo y el valor final en el programa de tasa de aprendizaje deben cambiarse simultáneamente con la misma proporción en comparación con AdamW, como lo demuestra un investigador.
Programa de tasa de aprendizaje: los autores utilizan el mismo programa de tasa de aprendizaje para Lion que AdamW en el artículo. Sin embargo, observan una ganancia mayor cuando se utiliza un programa de desintegración del coseno para entrenar ViT, en comparación con un programa recíproco de raíz cuadrada.
β1 y β2: los autores escriben en la Sección 5 - The default values for β1 and β2 in AdamW are set as 0.9 and 0.999, respectively, with an ε of 1e−8, while in Lion, the default values for β1 and β2 are discovered through the program search process and set as 0.9 and 0.99, respectively. De manera similar a cómo las personas reducen β2 a 0,99 o menos y aumentan ε a 1e-6 en AdamW para mejorar la estabilidad, usar β1=0.95, β2=0.98 en Lion también puede ser útil para mitigar la inestabilidad durante el entrenamiento, sugerido por los autores. Esto fue corroborado por un investigador.
Actualización: parece funcionar para mi modelado de lenguaje autorregresivo enwik8 local.
Actualización 2: experimentos, parece mucho peor que Adam si la tasa de aprendizaje se mantiene constante.
Actualización 3: Al dividir la tasa de aprendizaje por 3, se obtienen mejores resultados iniciales que Adam. Quizás Adam haya sido destronado, después de casi una década.
Actualización 4: el uso de la regla general de tasa de aprendizaje 10 veces menor del artículo resultó en la peor ejecución. Así que supongo que todavía hace falta un poco de ajuste.
Un resumen de actualizaciones anteriores: como se muestra en los experimentos, Lion con una tasa de aprendizaje 3 veces menor vence a Adam. Todavía es necesario un poco de ajuste, ya que una tasa de aprendizaje 10 veces menor conduce a un peor resultado.
Actualización 5: hasta ahora hemos escuchado todos los resultados positivos del modelado del lenguaje, cuando se hace correctamente. También escuché resultados positivos para una capacitación significativa de texto a imagen, aunque requiere un poco de ajuste. Los resultados negativos parecen deberse a problemas y arquitecturas fuera de lo que se evaluó en el artículo: RL, redes de avance, arquitecturas híbridas extrañas con LSTM + convoluciones, etc. Los datos anecdóticos negativos también confirman que esta técnica es sensible al tamaño del lote, la cantidad de datos/aumento. . Por determinar, cuál es el programa de tasa de aprendizaje óptimo y si el tiempo de reutilización afecta los resultados. Curiosamente, también tiene un resultado positivo en el clip abierto, que se volvió negativo a medida que se amplió el tamaño del modelo (pero puede resolverse).
Actualización 6: problema de clip abierto resuelto por el autor estableciendo una temperatura inicial más alta.
Actualización 7: solo recomendaría este optimizador en configuraciones de tamaños de lote altos (64 o más)
$ pip instalar león-pytorch
Alternativamente, usando conda:
$ conda instalar lion-pytorch
# modelo de jugueteimportar antorchadesde antorcha importar nnmodel = nn.Linear(10, 1)# importar León y crear una instancia con parámetros de lion_pytorch importar Lionopt = Lion(model.parameters(), lr=1e-4, Weight_decay=1e-2)# adelante y pérdida hacia atrás = modelo (torch.randn (10)) pérdida. hacia atrás () # optimizador pasoopt.paso()opt.zero_grad()
Para utilizar un kernel fusionado para actualizar los parámetros, primero pip install triton -U --pre , luego
opt = Lion(model.parameters(),lr=1e-4,weight_decay=1e-2,use_triton=True # establezca esto en True para usar cuda kernel con Triton lang (Tillet et al))
Stability.ai por el generoso patrocinio para trabajar y abrir la investigación de vanguardia en inteligencia artificial
@misc{https://doi.org/10.48550/arxiv.2302.06675,url = {https://arxiv.org/abs/2302.06675},autor = {Chen, Xiangning y Liang, Chen y Huang, Da y Real, Esteban y Wang, Kaiyuan y Liu, Yao y Pham, Hieu y Dong, Xuanyi y Luong, Thang y Hsieh, Cho-Jui y Lu, Yifeng y Le, Quoc V.}, título = {Descubrimiento simbólico de algoritmos de optimización}, editor = {arXiv}, año = {2023}} @article{Tillet2019TritonAI,title = {Triton: un lenguaje intermedio y compilador para cálculos de redes neuronales en mosaico},autor = {Philippe Tillet y H. Kung y D. Cox},journal = {Actas del 3er taller internacional sobre máquinas ACM SIGPLAN Aprendizaje y Lenguajes de Programación},año = {2019}} @misc{Schaipp2024,autor = {Fabian Schaipp},url = {https://fabian-sp.github.io/posts/2024/02/decoupling/}} @inproceedings{Liang2024CautiousOI,title = {Optimizadores cautelosos: mejorar la capacitación con una línea de código},autor = {Kaizhao Liang y Lizhang Chen y Bo Liu y Qiang Liu},año = {2024},url = {https://api .semanticscholar.org/CorpusID:274234738}} 

