RoboFlamingo
1.0.0
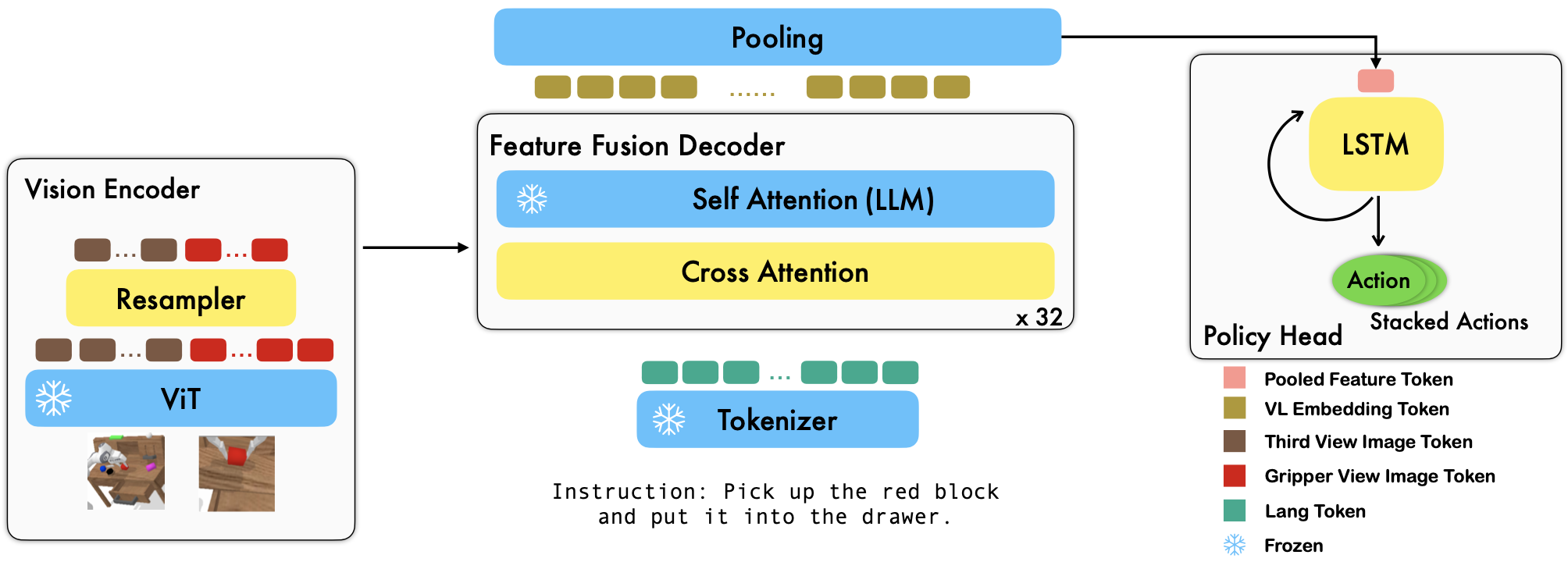
RoboFlamingo es un marco de aprendizaje de robótica basado en VLM previamente entrenado que aprende una amplia variedad de habilidades robóticas condicionadas por el lenguaje mediante el ajuste de conjuntos de datos de imitación de formato libre fuera de línea. Al superar el rendimiento de última generación con un amplio margen en el benchmark CALVIN, demostramos que RoboFlamingo puede ser una alternativa eficaz y competitiva para adaptar los VLM al control de robots. Nuestros extensos resultados experimentales también revelan varias conclusiones interesantes sobre el comportamiento de diferentes VLM previamente entrenados en tareas de manipulación. RoboFlamingo se puede entrenar o evaluar en un único servidor GPU (los requisitos de la memoria GPU dependen del tamaño del modelo) y creemos que RoboFlamingo tiene el potencial de ser una solución rentable y fácil de usar para la manipulación robótica, brindando a todos la posibilidad de capacidad de ajustar su propia política de robótica.
Este es también el repositorio de código oficial para el documento Vision-Language Foundation Models as Effective Robot Imitators.
Todos nuestros experimentos se realizan en un único servidor GPU con 8 GPU Nvidia A100 (80G).
Los modelos previamente entrenados están disponibles en Hugging Face.
Admitimos codificadores de visión previamente entrenados del paquete OpenCLIP, que incluye los modelos previamente entrenados de OpenAI. También admitimos modelos de lenguaje previamente entrenados del paquete transformers , como los modelos MPT, RedPajama, LLaMA, OPT, GPT-Neo, GPT-J y Pythia.
from robot_flamingo . factor import create_model_and_transforms
model , image_processor , tokenizer = create_model_and_transforms (
clip_vision_encoder_path = "ViT-L-14" ,
clip_vision_encoder_pretrained = "openai" ,
lang_encoder_path = "PATH/TO/LLM/DIR" ,
tokenizer_path = "PATH/TO/LLM/DIR" ,
cross_attn_every_n_layers = 1 ,
decoder_type = 'lstm' ,
) El argumento cross_attn_every_n_layers controla la frecuencia con la que se aplican las capas de atención cruzada y debe ser coherente con el VLM. El argumento decoder_type controla el tipo de decodificador; actualmente, admitimos lstm , fc , diffusion (existen errores para el cargador de datos) y GPT .
Informamos los resultados en el benchmark CALVIN.
| Método | Datos de entrenamiento | División de prueba | 1 | 2 | 3 | 4 | 5 | Len promedio |
|---|---|---|---|---|---|---|---|---|
| MCIL | ABCD (completo) | D | 0.373 | 0,027 | 0.002 | 0.000 | 0.000 | 0,40 |
| HULC | ABCD (completo) | D | 0,889 | 0.733 | 0.587 | 0,475 | 0.383 | 3.06 |
| HULC (reentrenado) | ABCD (idioma) | D | 0,892 | 0.701 | 0.548 | 0.420 | 0.335 | 2.90 |
| RT-1 (reentrenado) | ABCD (idioma) | D | 0.844 | 0,617 | 0.438 | 0.323 | 0.227 | 2.45 |
| Nuestro | ABCD (idioma) | D | 0.964 | 0.896 | 0.824 | 0.740 | 0,66 | 4.09 |
| MCIL | ABC (completo) | D | 0.304 | 0.013 | 0.002 | 0.000 | 0.000 | 0,31 |
| HULC | ABC (completo) | D | 0.418 | 0.165 | 0,057 | 0.019 | 0.011 | 0,67 |
| RT-1 (reentrenado) | ABC (idioma) | D | 0.533 | 0.222 | 0.094 | 0.038 | 0.013 | 0,90 |
| Nuestro | ABC (idioma) | D | 0.824 | 0,619 | 0.466 | 0.331 | 0.235 | 2.48 |
| HULC | ABCD (completo) | D (Enriquecer) | 0,715 | 0.470 | 0.308 | 0,199 | 0.130 | 1,82 |
| RT-1 (reentrenado) | ABCD (idioma) | D (Enriquecer) | 0,494 | 0.222 | 0.086 | 0.036 | 0,017 | 0,86 |
| Nuestro | ABCD (idioma) | D (Enriquecer) | 0.720 | 0.480 | 0,299 | 0.211 | 0.144 | 1,85 |
| Nuestro (congelar-emb) | ABCD (idioma) | D (Enriquecer) | 0,737 | 0.530 | 0.385 | 0.275 | 0,192 | 2.12 |
Siga las instrucciones de OpenFlamingo y CALVIN para descargar el conjunto de datos necesario y los modelos preentrenados de VLM.
Descargue el conjunto de datos de CALVIN, elija una división con:
cd $HULC_ROOT /dataset
sh download_data.sh D | ABC | ABCD | debugDescargue los modelos OpenFlamingo lanzados:
| # parámetros | modelo de lenguaje | Codificador de visión | Intervalo Xattn* | SIDRA COCO 4 tragos | Precisión de 4 disparos VQAv2 | Len promedio | Pesos |
|---|---|---|---|---|---|---|---|
| 3B | anas-awadalla/mpt-1b-pijama-rojo-200b | openai CLIP ViT-L/14 | 1 | 77,3 | 45,8 | 3.94 | Enlace |
| 3B | anas-awadalla/mpt-1b-pijama-rojo-200b-dolly | openai CLIP ViT-L/14 | 1 | 82,7 | 45,7 | 4.09 | Enlace |
| 4B | togethercomputer/RedPajama-INCITE-Base-3B-v1 | openai CLIP ViT-L/14 | 2 | 81,8 | 49.0 | 3.67 | Enlace |
| 4B | togethercomputer/RedPajama-INCITE-Instruct-3B-v1 | openai CLIP ViT-L/14 | 2 | 85,8 | 49.0 | 3.79 | Enlace |
| 9B | anas-awadalla/mpt-7b | openai CLIP ViT-L/14 | 4 | 89.0 | 54,8 | 3.97 | Enlace |
Reemplace ${lang_encoder_path} y ${tokenizer_path} del diccionario de rutas (por ejemplo, mpt_dict ) en robot_flamingo/models/factory.py para cada VLM previamente entrenado con sus propias rutas.
Clonar este repositorio
git clone https://github.com/RoboFlamingo/RoboFlamingo.git
Instale los paquetes necesarios:
cd RoboFlamingo
conda create -n RoboFlamingo python=3.8
source activate RoboFlamingo
pip install -r requirements.txt
torchrun --nnodes=1 --nproc_per_node=8 --master_port=6042 robot_flamingo/train/train_calvin.py
--report_to_wandb
--llm_name mpt_dolly_3b
--traj_cons
--use_gripper
--fusion_mode post
--rgb_pad 10
--gripper_pad 4
--precision fp32
--num_epochs 5
--gradient_accumulation_steps 1
--batch_size_calvin 6
--run_name RobotFlamingoDBG
--calvin_dataset ${calvin_dataset_path}
--lm_path ${lm_path}
--tokenizer_path ${tokenizer_path}
--openflamingo_checkpoint ${openflamingo_checkpoint}
--cross_attn_every_n_layers 4
--dataset_resampled
--loss_multiplier_calvin 1.0
--workers 1
--lr_scheduler constant
--warmup_steps 5000
--learning_rate 1e-4
--save_every_iter 10000
--from_scratch
--window_size 12 > ${log_file} 2>&1
${calvin_dataset_path} es la ruta al conjunto de datos CALVIN;
${lm_path} es el camino hacia el LLM previamente capacitado;
${tokenizer_path} es la ruta al tokenizador VLM;
${openflamingo_checkpoint} es el camino al modelo previamente entrenado de OpenFlamingo;
${log_file} es la ruta al archivo de registro.
También proporcionamos robot_flamingo/pt_run_gripper_post_ws_12_traj_aug_mpt_dolly_3b.bash para iniciar la capacitación. Este bash afina la versión MPT-3B-IFT del modelo OpenFlamingo, que contiene los hiperparámetros predeterminados para entrenar el modelo y corresponde a los mejores resultados del artículo.
python eval_ckpts.py
Al agregar el nombre del punto de control y el directorio en eval_ckpts.py , el script cargaría automáticamente el modelo y lo evaluaría. Por ejemplo, si desea evaluar el punto de control en la ruta 'su-ruta-de-punto-de-control', puede modificar las variables ckpt_dir y ckpt_names en eval_ckpts.py, y los resultados de la evaluación se guardarán como 'logs/your-checkpoint-prefix'. registro'.
Los resultados que se muestran a continuación indican que el coentrenamiento podría preservar la mayor parte de la capacidad de la columna vertebral de VLM en tareas de VL, al tiempo que se pierde un poco de rendimiento en tareas de robot.
usar
bash robot_flamingo/pt_run_gripper_post_ws_12_traj_aug_mpt_dolly_3b_co_train.bash
lanzar el co-entrenamiento RoboFlamingo con CoCO, VQAV2 y CALVIN. Debe actualizar las rutas CoCO y VQA en get_coco_dataset y get_vqa_dataset en robot_flamingo/data/data.py .
| Dividir | SR 1 | SR 2 | SR 3 | SR 4 | SR 5 | Len promedio |
|---|---|---|---|---|---|---|
| Co-entrenamiento | ABC->D | 82,9% | 63,6% | 45,3% | 32,1% | 23,4% |
| Afinar | ABC->D | 82,4% | 61,9% | 46,6% | 33,1% | 23,5% |
| Co-entrenamiento | ABCD->D | 95,7% | 85,8% | 73,7% | 64,5% | 56,1% |
| Afinar | ABCD->D | 96,4% | 89,6% | 82,4% | 74,0% | 66,2% |
| Co-entrenamiento | ABCD->D (Enriquecer) | 67,8% | 45,2% | 29,4% | 18,9% | 11,7% |
| Afinar | ABCD->D (Enriquecer) | 72,0% | 48,0% | 29,9% | 21,1% | 14,4% |
| palma de coco | VQA | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| AZUL-1 | AZUL-2 | AZUL-3 | AZUL-4 | METEORITO | ROJO_L | Sidra | CONDIMENTAR | Acc | |
| Ajuste fino (3B, disparo cero) | 0,156 | 0.051 | 0,018 | 0.007 | 0.038 | 0,148 | 0.004 | 0.006 | 4.09 |
| Ajuste fino (3B, 4 disparos) | 0,166 | 0.056 | 0.020 | 0.008 | 0,042 | 0,158 | 0.004 | 0.008 | 3.87 |
| Co-Train (3B, tiro cero) | 0.225 | 0,158 | 0.107 | 0,072 | 0,124 | 0.334 | 0.345 | 0,085 | 36.37 |
| Flamenco original (80B, afinado) | - | - | - | - | - | - | 1.381 | - | 82.0 |
El logo se genera usando MidJourney.
Este trabajo utiliza código de los siguientes proyectos y conjuntos de datos de código abierto:
Original: https://github.com/mees/calvin Licencia: MIT
Original: https://github.com/openai/CLIP Licencia: MIT
Original: https://github.com/mlfoundations/open_flamingo Licencia: MIT
@article{li2023vision,
title = {Vision-Language Foundation Models as Effective Robot Imitators},
author = {Li, Xinghang and Liu, Minghuan and Zhang, Hanbo and Yu, Cunjun and Xu, Jie and Wu, Hongtao and Cheang, Chilam and Jing, Ya and Zhang, Weinan and Liu, Huaping and Li, Hang and Kong, Tao},
journal={arXiv preprint arXiv:2311.01378},
year={2023}


