Extendible Hashing for DBMS
1.0.0
Una implementación de bajo nivel de hash extensible para sistemas de bases de datos.
Este método utiliza directorios y depósitos para realizar hash de datos y es ampliamente conocido por su flexibilidad y eficiencia en el tiempo de computación.
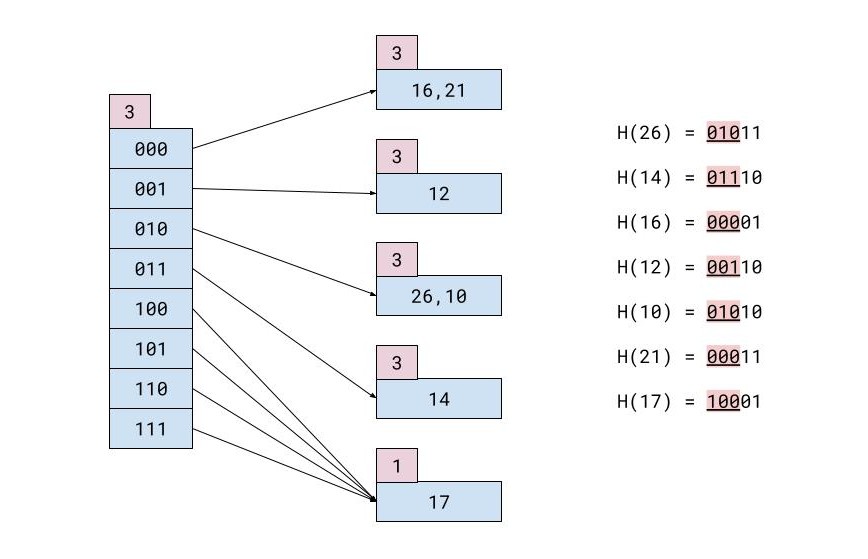
Por ejemplo, tienes esta tabla de registros:
| IDENTIFICACIÓN | NOMBRE | APELLIDO | CIUDAD |
|---|---|---|---|
| 26 | María | Koronis | Hong Kong |
| 14 | cristóforos | gaitanes | Tokio |
| 16 | mariana | Karvounari | miami |
| 12 | teófilo | Nikolópulos | Londres |
| 10 | José | Svingos | Tokio |
| 21 | teófilo | michas | Atenas |
| 17 | Giorgos | Halatsis | Munich |
Si cada bloque de memoria puede tener solo 2 registros, el archivo hash después de todas las inserciones se verá así:
El programa se puede ejecutar mediante dos funciones principales diferentes. Este primero inserta una gran cantidad de registros en un archivo y el segundo crea e inserta registros en tres archivos diferentes simultáneamente.
prueba_main1:
make main1
./build/runner
prueba_main2:
make main2
./build/runner