liuli
v0.2.0
Sólo explícalo brevemente:
Coleccionista : monitorea fuentes de lectura personalizadas, como cuentas públicas, libros o fuentes de blogs que siguen, y fluye hacia Liuli en un formato estándar unificado como fuente de entrada;
Procesador : personalice el contenido de destino, como utilizar el aprendizaje automático para etiquetar automáticamente un clasificador de publicidad en función de datos publicitarios históricos o introducir funciones de enlace para ejecutar en nodos relevantes;
Distribuidor : se basa en la capa de interfaz para realizar solicitudes y respuestas de datos, proporciona a los usuarios configuraciones personalizadas y luego distribuye automáticamente según la configuración, enviando artículos limpios a clientes WeChat, DingTalk, TG, RSS e incluso sitios web de creación propia;
Respaldador : realice una copia de seguridad de los artículos procesados, como conservarlos en una base de datos o GitHub, etc.
Con esto se logra la construcción de un ambiente de lectura limpio. Derivadamente, hay muchas cosas que se pueden hacer en base a los datos obtenidos. Es posible que desee difundir sus ideas.
Panel de progreso del desarrollo:
v0.2.0: Implementar funciones básicas para garantizar que se puedan aplicar soluciones para escenarios comunes
v0.3.0: Implementar la personalización del recopilador, los usuarios pueden recopilar lo que ven
Para mejorar la precisión del reconocimiento del modelo, espero que todos puedan contribuir con algunas muestras publicitarias. Consulte el archivo de muestra: .files/datasets/ads.csv.
| título | URL | es_proceso |
|---|---|---|
| Título del artículo publicitario | Enlace del artículo publicitario | 0 |
Descripción del campo:
título: título del artículo
URL: enlace del artículo Si desea utilizar el artículo de WeChat, primero verifique si no es válido.
is_process: indica si se realiza el procesamiento de muestras. Complete 0 de forma predeterminada.
Pongamos un ejemplo:
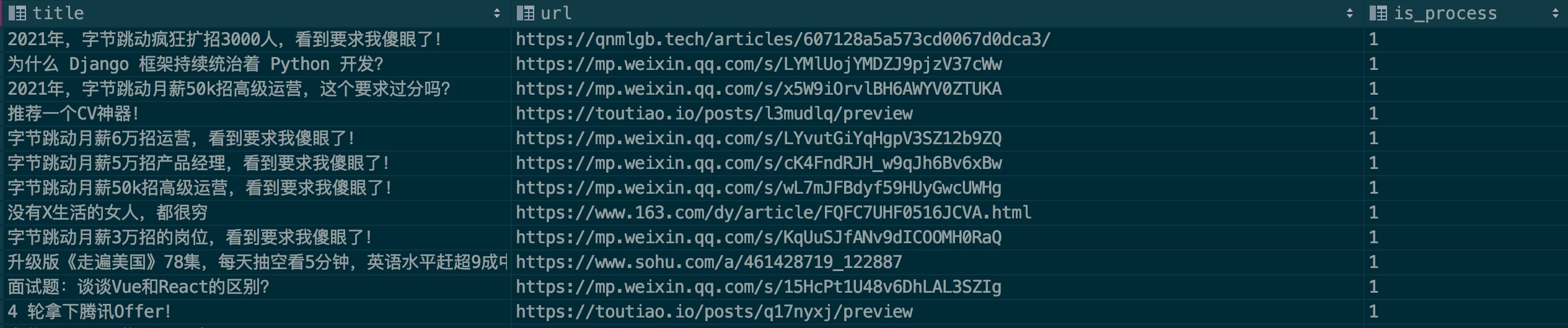
Generalmente, los anuncios se colocarán repetidamente en varias cuentas públicas. Verifique si este registro existe al completarlo. Espero que todos puedan trabajar juntos para contribuir.
Gracias a los siguientes proyectos de código abierto:
Frasco: marco web
Vue: marco de JavaScript progresivo
Ruia: marco de rastreo asincrónico (desarrollado y utilizado por usted mismo)
dramaturgo: extracción de datos mediante el navegador
Lo anterior solo enumera las dependencias principales de código abierto. Para obtener más dependencias de terceros, consulte el archivo Pipfile.
Cualquier PR que reciba es un gran apoyo para el proyecto Liuli . Estamos muy agradecidos a los siguientes desarrolladores por sus contribuciones (sin ningún orden en particular):
Bienvenidos a comunicarnos juntos (sigue el grupo):


