ChatGPT WechatBot using OpenAI API via Wechty
1.0.0
ChatGPT-WechatBot es un robot similar a chatGPT implementado utilizando el modelo de diálogo basado en la API oficial de OpenAI y se implementa en WeChat a través del marco Wechaty para realizar el chat del robot.
ChatGPT WechatBot es un tipo de robot chatGPT basado en la API oficial de OpenAI y que utiliza el modelo de diálogo. Se implementa en WeChat a través del marco de Wechat para lograr el chat robótico.
Nota : este proyecto es una implementación local de Win10 y no requiere la implementación del servidor (si se requiere la implementación del servidor, puede implementar Docker en el servidor)
(1), Windows10
(2), acoplador 20.10.21
(3), Python3.9
(4), WeChaty 0.10.7
1. Descarga Docker
https://www.docker.com/products/docker-desktop/ Descargar Docker
2. Active la virtualización de Win10
Ingrese control en cmd para abrir el panel de control e ingresar al programa, como se muestra en la siguiente figura:
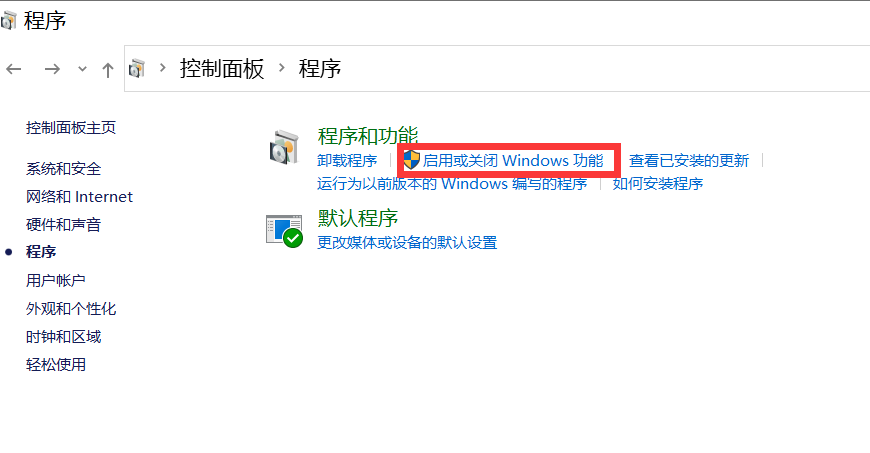
Vaya a Activar o desactivar las funciones de Windows y active Hyper-V.
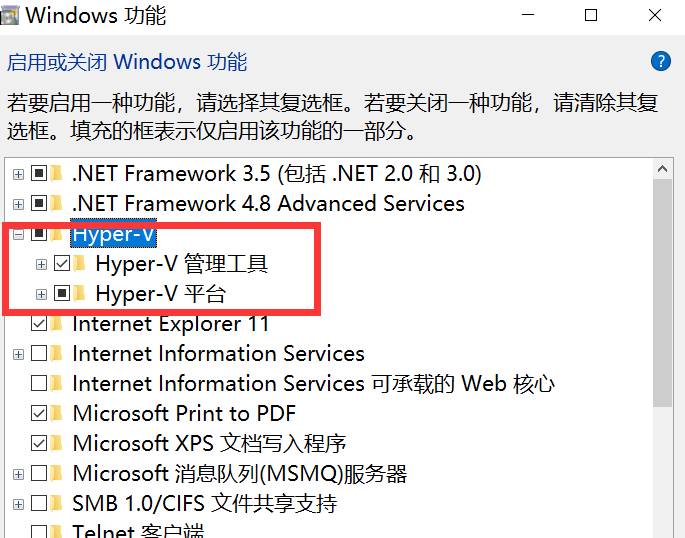
Nota : Si su computadora no tiene Hyper-V, debe realizar las siguientes operaciones:
Cree un documento de texto, complete el siguiente código y asígnele el nombre Hyper.cmd
pushd " %~dp0 "
dir /b %SystemRoot% s ervicing P ackages * Hyper-V * .mum > hyper-v.txt
for /f %%i in ( ' findstr /i . hyper-v.txt 2^>nul ' ) do dism /online /norestart /add-package: " %SystemRoot%servicingPackages%%i "
del hyper-v.txt
Dism /online /enable-feature /featurename:Microsoft-Hyper-V-All /LimitAccess /ALLLuego ejecute este archivo como administrador. Una vez que el script haya terminado de ejecutarse, habrá un nodo Hyper-V después de reiniciar la computadora.
3. Ejecute Docker
Nota : Si ocurre lo siguiente al ejecutar Docker por primera vez:
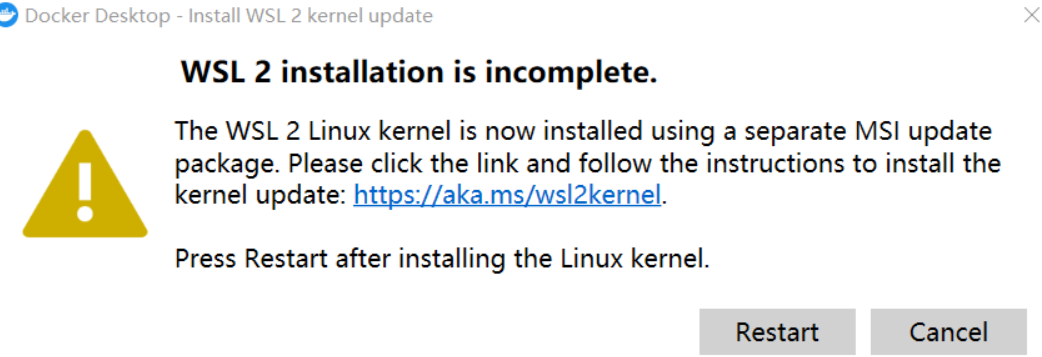
Necesita descargar el último paquete WSL 2
https://wslstorestorage.blob.core.windows.net/wslblob/wsl_update_x64.msi
Después de la actualización, puede ingresar a la página principal, luego cambiar la configuración en el motor Docker y reemplazar la imagen con la imagen nacional de Alibaba Cloud:
{
"builder": {
"gc": {
"defaultKeepStorage": "20GB",
"enabled": true
}
},
"debug": false,
"experimental": false,
"features": {
"buildkit": true
},
"insecure-registries": [],
"registry-mirrors": [
"https://9cpn8tt6.mirror.aliyuncs.com"
]
}De esta forma es más rápido sacar el espejo (para usuarios domésticos)
4. Extraiga la imagen de Wechaty :
docker pull wechaty:0 . 65Porque durante las pruebas, se descubrió que la versión 0.65 de wechaty es la más estable.
Después de sacar la imagen:
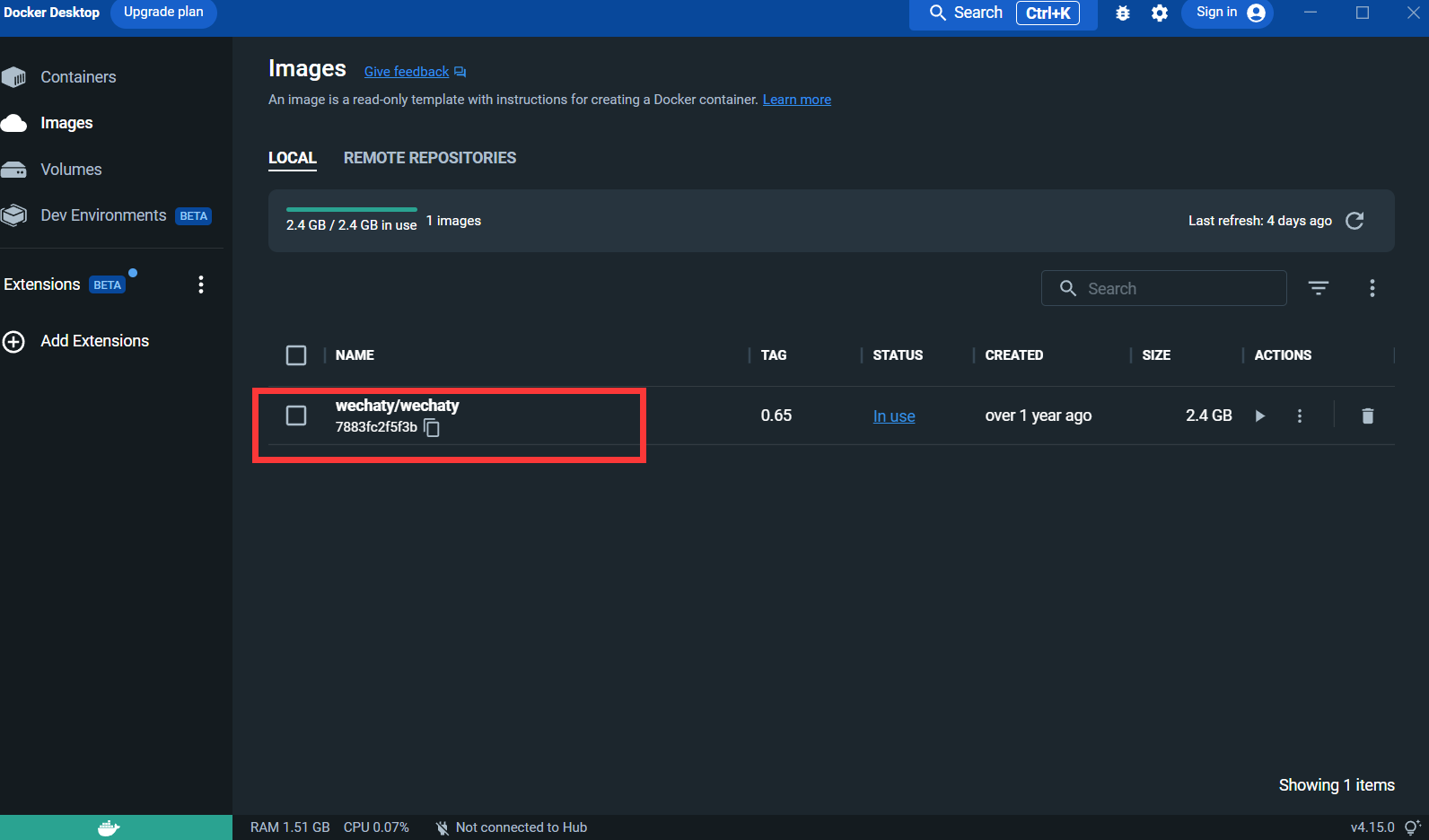
Puppet : si desea utilizar Wechaty para desarrollar un robot WeChat, debe utilizar un Puppet de middleware para controlar el funcionamiento de WeChat. La traducción oficial de Puppet es Puppet. Actualmente hay muchos tipos de Puppet disponibles. de Puppet son las diferentes funciones del robot que se pueden lograr. Por ejemplo, si desea que su robot expulse a los usuarios de un chat grupal, debe usar Puppet bajo el protocolo Pad.
Solicite conexión: http://pad-local.com/#/login
Nota : Después de solicitar una cuenta, recibirá un token de 7 días.
Después de solicitar el token, ejecute el siguiente comando en la ventana cmd:
docker run - it - d -- name wechaty_test - e WECHATY_LOG="verbose" - e WECHATY_PUPPET="wechaty - puppet - padlocal" - e WECHATY_PUPPET_PADLOCAL_TOKEN="yourtoken" - e WECHATY_PUPPET_SERVER_PORT="8080" - e WECHATY_TOKEN="1fe5f846 - 3cfb - 401d - b20c - sailor==" - p "8080:8080" wechaty/wechaty:0 . 65
Descripción del parámetro:
WECHATY_PUPPET_PADLOCAL_TOKEN : Solicita un buen token
**WECHATY_TOKEN **: Simplemente escriba una cadena aleatoria que se garantice que sea única
WECHATY_PUPPET_SERVER_PORT : puerto del servidor acoplable
wechaty/wechaty:0.65 : versión de la imagen de wechaty
Nota: - "8080:8080"* es el puerto de su máquina local y del servidor acoplable. Tenga en cuenta que el puerto del servidor acoplable debe ser coherente con WECHATY_PUPPET_SERVER_PORT.
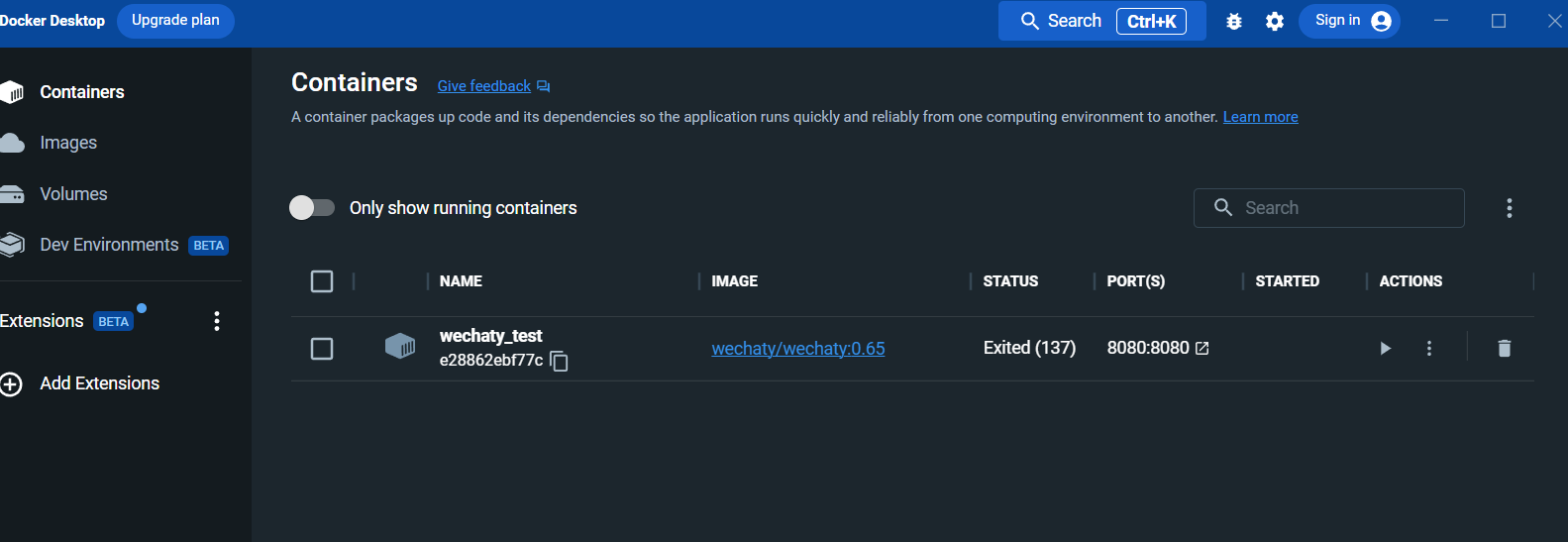
Después de ejecutar, vea el contenedor en el panel del escritorio de la ventana acoplable:
Ingrese a la interfaz de registro:
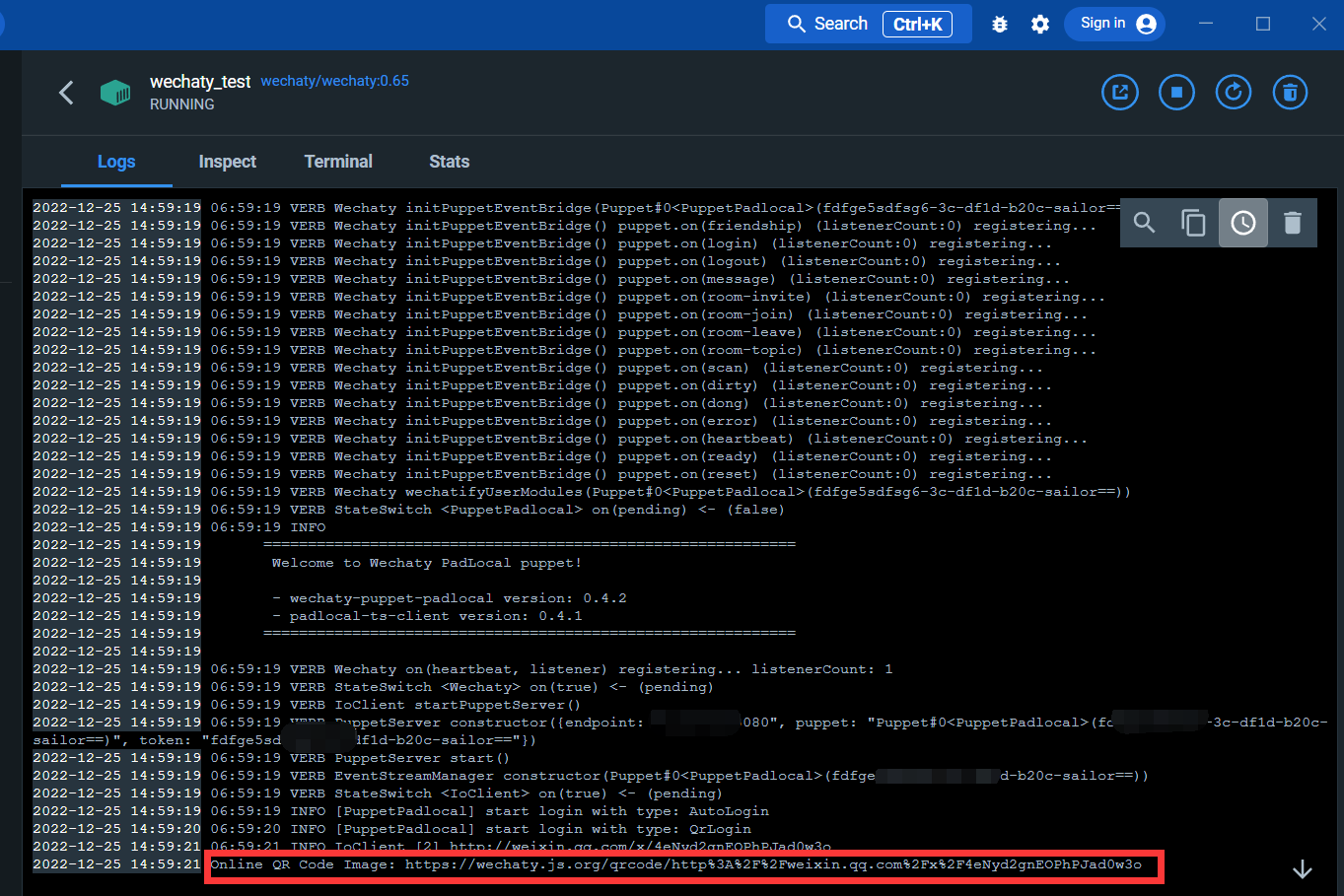
A través del siguiente enlace, puede escanear el código QR para iniciar sesión en WeChat
Después de iniciar sesión, se completa el servicio Docker.
Instalar bibliotecas wechaty y openai
Abra cmd y ejecute el siguiente comando:
pip install wechaty
pip install openaiInicie sesión en openAI
https://beta.openai.com/
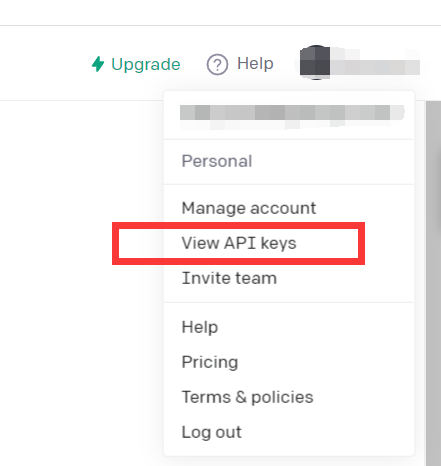
Haga clic en Ver claves API
Solo obtén API kyes
En este punto, el entorno está configurado.
Puedes intentar leer este código de demostración.
import openai
openai . api_key = "your API-KEY"
start_sequence = "A:"
restart_sequence = "Q: "
while True :
print ( restart_sequence , end = "" )
prompt = input ()
if prompt == 'quit' :
break
else :
try :
response = openai . Completion . create (
model = "text-davinci-003" ,
prompt = prompt ,
temperature = 0.9 ,
max_tokens = 2000 ,
frequency_penalty = 0 ,
presence_penalty = 0
)
print ( start_sequence , response [ "choices" ][ 0 ][ "text" ]. strip ())
except Exception as exc :
print ( exc )
Este código llama al modelo CPT-3, que es el mismo modelo que chatGPT, y el efecto de respuesta también es bueno.
El modelo GPT-3 de openAI se presenta de la siguiente manera:
Nuestros modelos GPT-3 pueden comprender y generar lenguaje natural. Ofrecemos cuatro modelos principales con diferentes niveles de potencia adecuados para diferentes tareas. Davinci es el modelo más capaz y Ada es el más rápido.
| ÚLTIMO MODELO | DESCRIPCIÓN | SOLICITUD MAX | DATOS DE ENTRENAMIENTO |
|---|---|---|---|
| texto-davinci-003 | El modelo GPT-3 más capaz puede realizar cualquier tarea que los otros modelos puedan realizar, a menudo con mayor calidad, mayor duración y mejor seguimiento de instrucciones. También admite la inserción de completaciones dentro del texto. | 4.000 fichas | Hasta junio de 2021 |
| texto-curie-001 | Muy capaz, pero más rápido y de menor costo que Davinci. | 2.048 fichas | Hasta octubre de 2019 |
| texto-babbage-001 | Capaz de realizar tareas sencillas, muy rápidas y de menor coste. | 2.048 fichas | Hasta octubre de 2019 |
| texto-ada-001 | Capaz de realizar tareas muy sencillas, suele ser el modelo más rápido de la serie GPT-3 y de menor coste. | 2.048 fichas | Hasta octubre de 2019 |
Si bien Davinci es generalmente el más capaz, los otros modelos pueden realizar ciertas tareas extremadamente bien con importantes ventajas de velocidad o costo. Por ejemplo, Curie puede realizar muchas de las mismas tareas que Davinci, pero más rápido y por una décima parte del costo.
Recomendamos usar Davinci mientras experimenta, ya que obtendrá los mejores resultados. Una vez que todo funcione, le recomendamos que pruebe los otros modelos para ver si puede obtener los mismos resultados con una latencia más baja. También puede mejorar el otro. el rendimiento de los modelos ajustándolos en una tarea específica.
En definitiva, el modelo GPT-3 más potente. Puede hacer cualquier cosa que otros modelos puedan hacer, generalmente con mayor calidad, mayor producción y mejor seguimiento de instrucciones. También se admite la inserción de completaciones en el texto.
Aunque el modelo text-davinci-003 se puede utilizar directamente para lograr el efecto de diálogo de ronda única de chatGPT, para lograr mejor el mismo efecto de diálogo de ronda múltiple que chatGPT, se puede diseñar un modelo de diálogo.
Principio básico: decirle al modelo text-davinci-003 el contexto de la conversación actual
Método de implementación: diseñe una cola de memoria de diálogo para guardar las primeras k rondas de diálogo del diálogo actual, dígale al modelo text-davinci-003 el contenido de las primeras k rondas de diálogo antes de hacer una pregunta y luego obtenga la respuesta actual. a través del contenido del modelo text-davinci-003
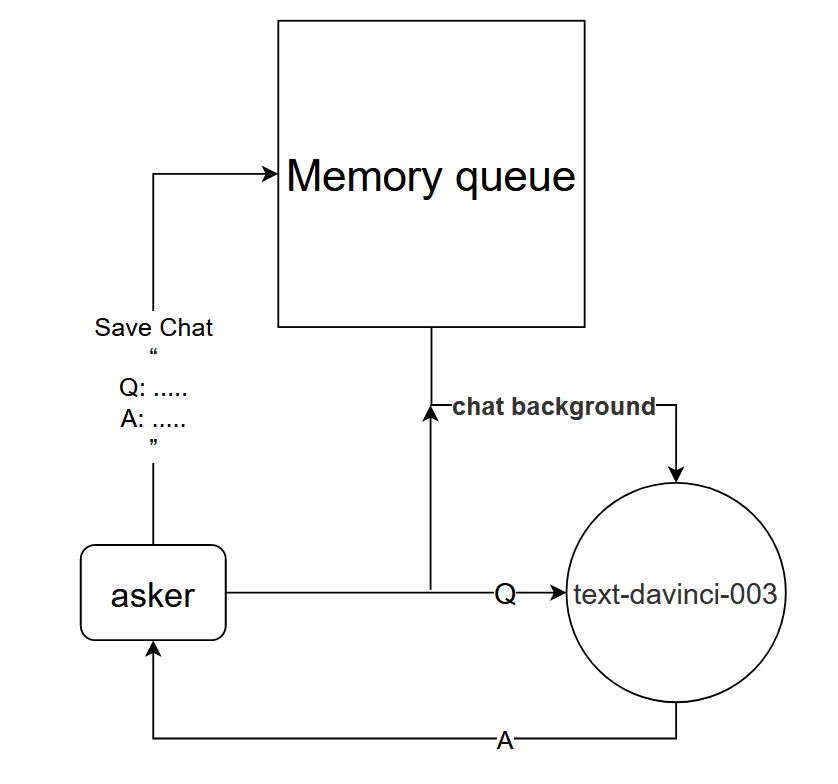
¡Este método funciona sorprendentemente bien! Dar algunos registros de chat.
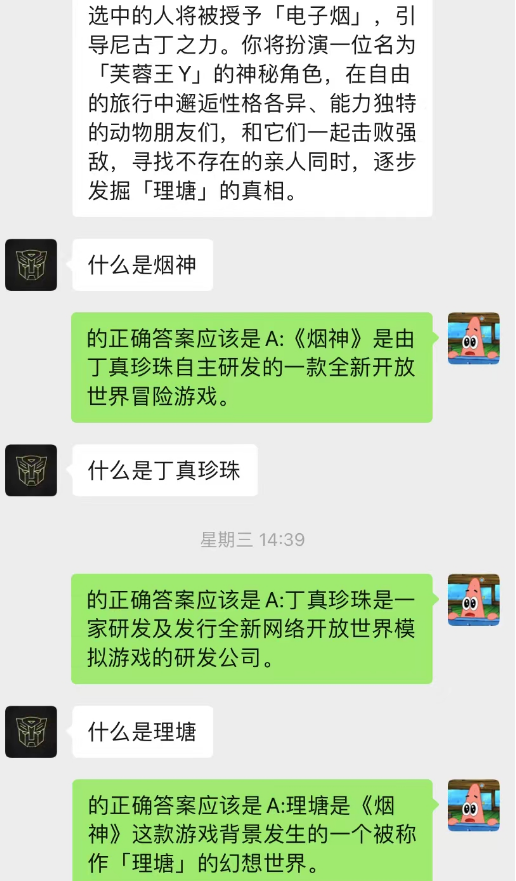
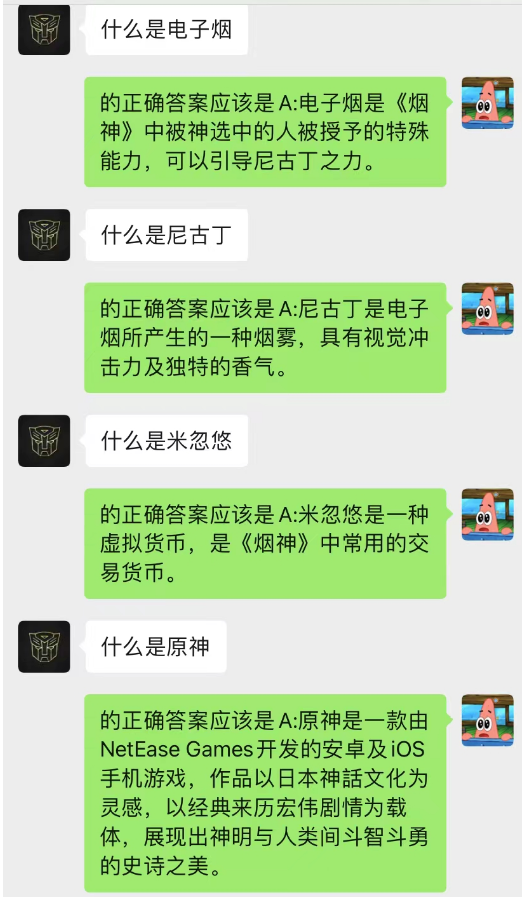
Se puede ver que actualmente el fondo del chat también se puede utilizar para permitir que la IA complete el aprendizaje situacional.
No solo eso, también puedes lograr la misma redacción guiada de artículos que chatGPT.
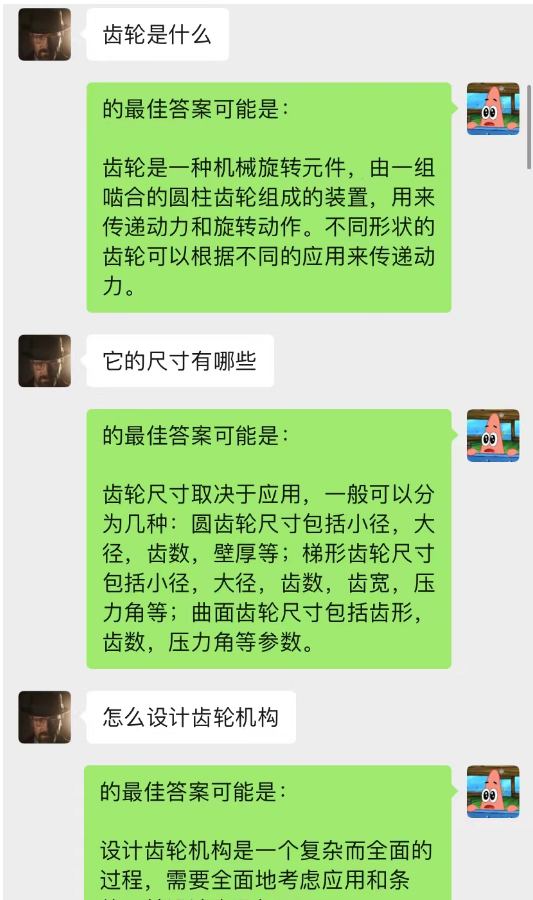
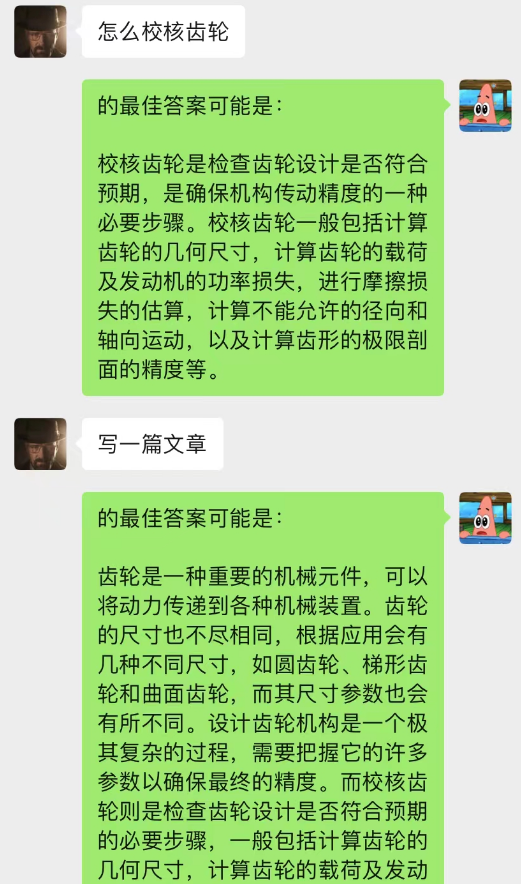
Este modelo es un método que estoy concibiendo actualmente para optimizar el modelo de diálogo de fondo de chat. Su lógica básica es la misma que la del modelo de lenguaje N-gram, excepto que N se cambia dinámicamente y se agregan propiedades de Markov para predecir el diálogo actual. el contexto, para juzgar que la sección en el fondo del chat es la más importante, y luego usar el modelo text-davinci-003 para dar una respuesta basada en el contenido de la conversación memorizado más importante y el problema actual (equivalente a dejar AI Hazlo durante el chat, usando contenido del chat anterior)
La implementación de este modelo requiere una gran cantidad de datos para el entrenamiento y el código aún no se ha completado.
------ Excavación : una vez implementado el código, actualice esta parte de los pasos detallados
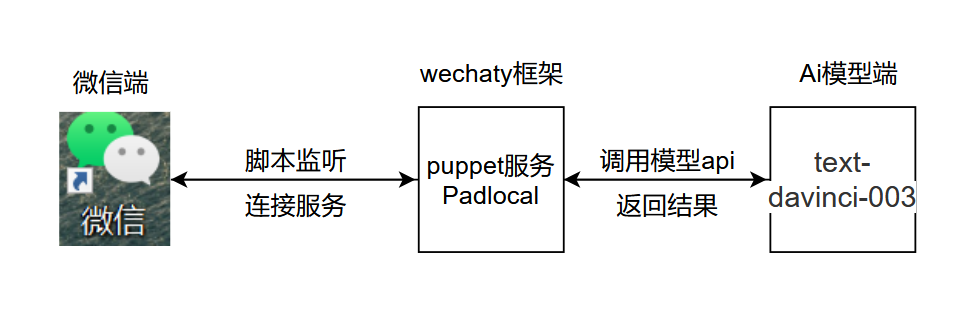
La lógica básica del proyecto se muestra en la siguiente figura:
 .py, agregue y abra chatGPT.py en la ubicación que se muestra, agregue la clave secreta y configure las variables de entorno en la ubicación que se muestra
.py, agregue y abra chatGPT.py en la ubicación que se muestra, agregue la clave secreta y configure las variables de entorno en la ubicación que se muestra

Explicación del código :
os . environ [ "WECHATY_PUPPET_SERVICE_TOKEN" ] = "填入你的Puppet的token" os . environ [ 'WECHATY_PUPPET' ] = 'wechaty-puppet-padlocal' #保证与docker中相同即可 os.environ['WECHATY_PUPPET_SERVICE_ENDPOINT'] = '主机ip:端口号'
Ejecutar exitosamente
1. Inicie sesión en la ventana acoplable, no utilice el inicio de sesión de Wechaty en Python
2. Configure time.sleep() en el código para simular la velocidad a la que las personas responden a los mensajes.
3. Es mejor no utilizar un tamaño grande al realizar pruebas. Se recomienda crear un tamaño pequeño dedicado para las pruebas de IA.
El contenido de este proyecto es únicamente para investigación técnica y divulgación científica, y no sirve como base concluyente. No proporciona ninguna autorización de aplicación comercial y no es responsable de ninguna acción.
~~correo electrónico: [email protected]


