glory admin
1.0.0
GloryAdmin es un marco en segundo plano basado en springboot2.1.9.RELEASE y vue-admin-template;
GloryAdmin utiliza gestión de permisos basada en roles. El árbol de funciones es un árbol con "Administrador del sistema" como nodo raíz y el árbol de permisos se compone de varios árboles de subpermisos. El "administrador del sistema" tiene todos los permisos; los roles que no son administradores del sistema pueden ver la información del rol actual y los roles directamente subordinados, pero solo pueden agregar, eliminar y modificar la información de los roles directamente subordinados (subordinados directos: A es el directo). subordinado de B, entonces A debe ser el nodo hijo de B).
Gloria-Administrador
| proyecto | tecnología |
|---|---|
| proyecto de fondo | arranque de primavera |
| Proyecto inicial | Elemento UI y Vue.js |
| base de datos | mysql |
| cache | Redis |

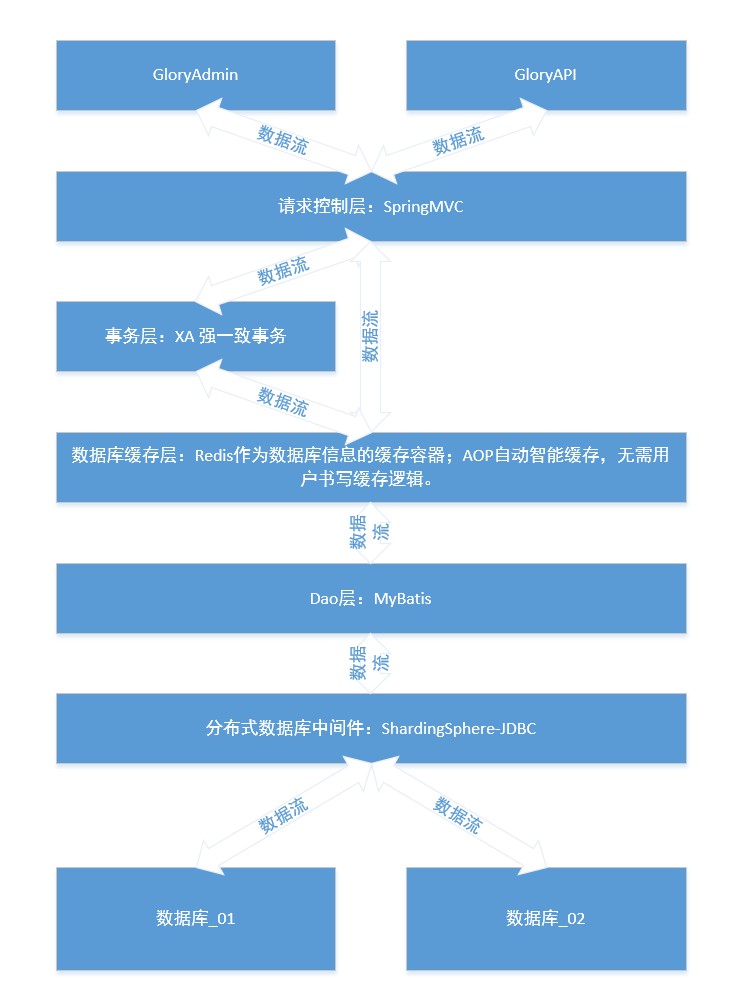
Este proyecto utiliza la base de datos mysql, puede usar el script de la base de datos para crear 2 bases de datos multi_module_db multi_module_db_01
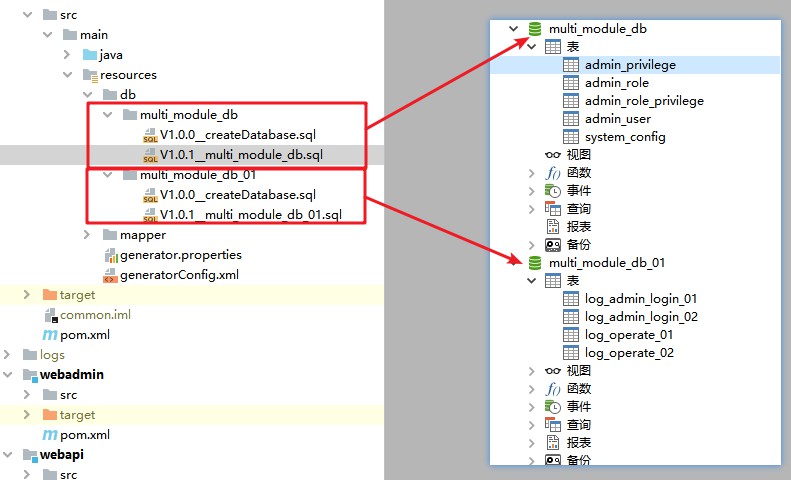
Comience en segundo plano y use el puerto 28081
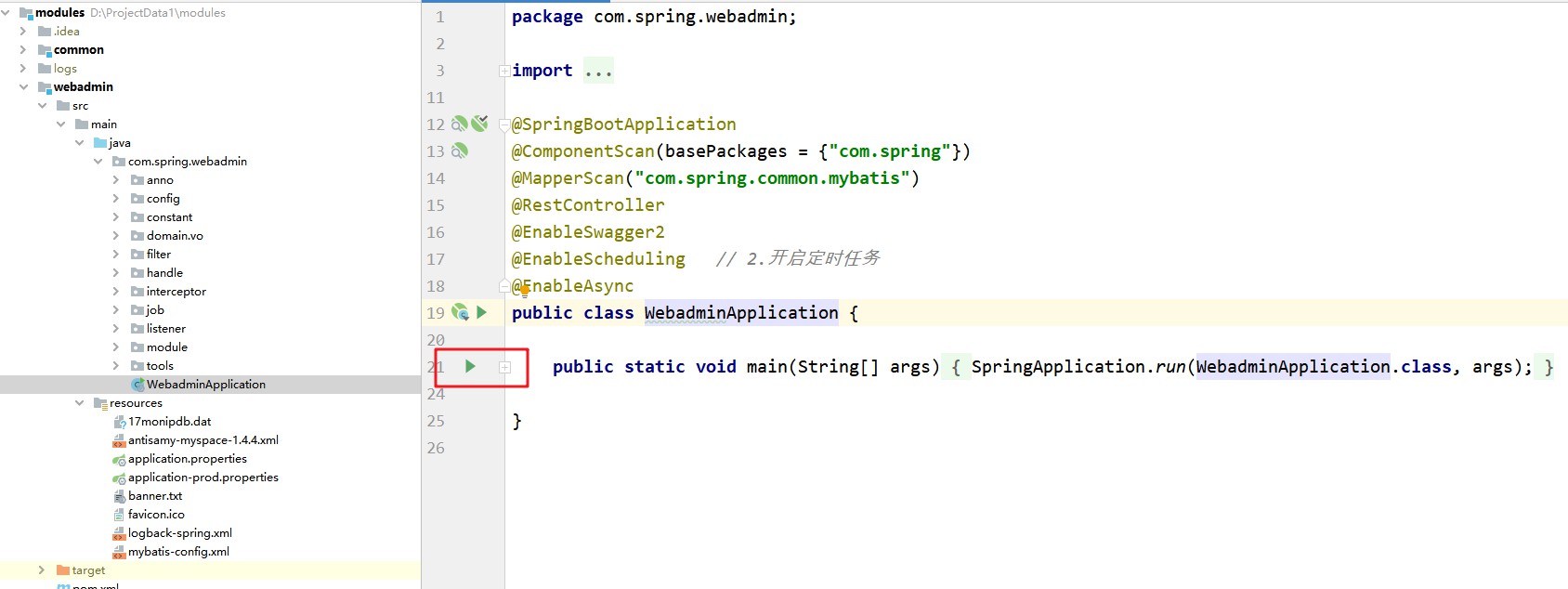
Inicie el front-end y use el puerto 9523
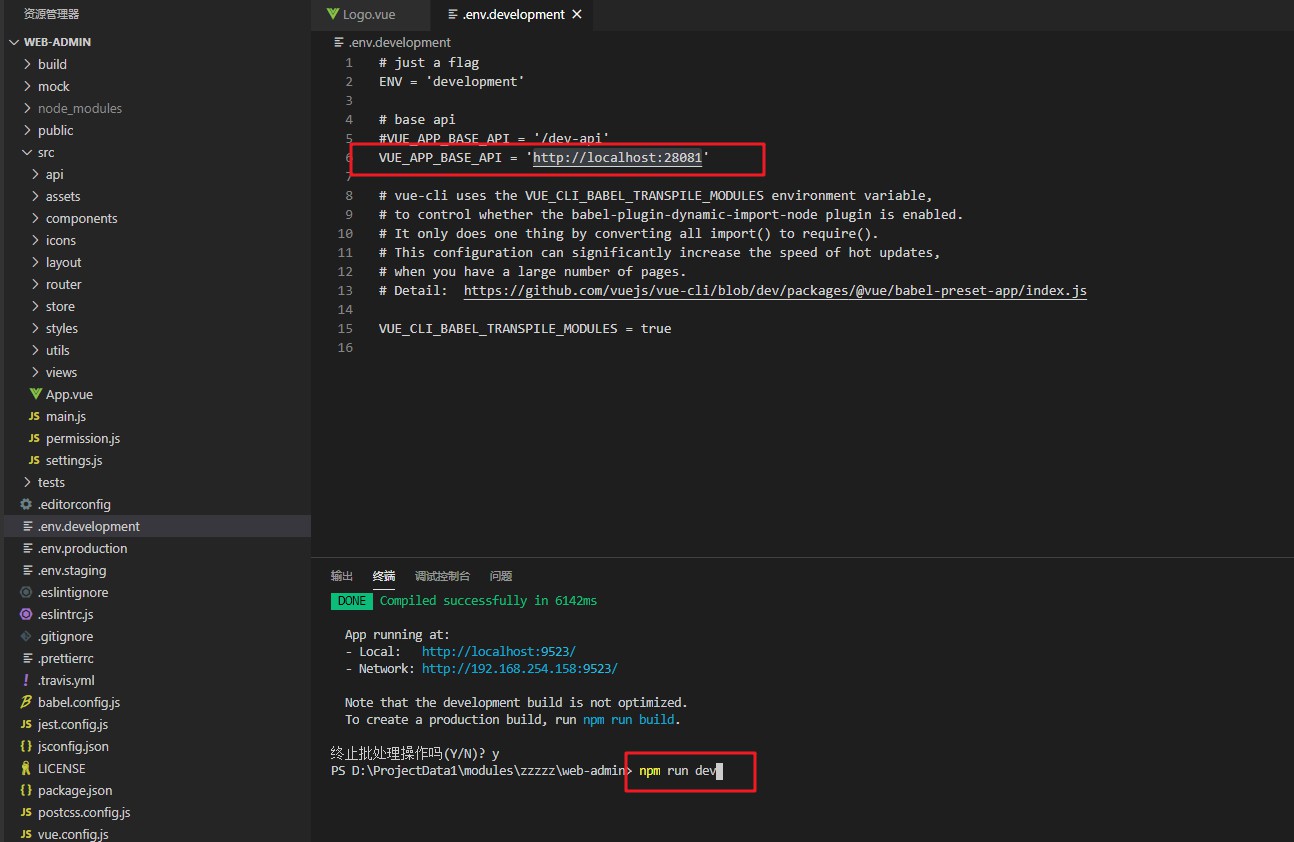
Abra el navegador y visite http://localhost:9523 admin a123456
La esencia de la fragmentación o fragmentación es el fracaso de la Ley de Moore. La solución de almacenar datos centralmente en un solo nodo de datos ha sido difícil de cumplir con los escenarios de datos masivos de Internet en términos de rendimiento, disponibilidad y costos de operación y mantenimiento.
Una sola base de datos no puede respaldar las empresas existentes, por lo que han surgido subbases de datos y tablas, y se utilizan múltiples bases de datos para el almacenamiento de datos. La comprensión simple de subbase de datos y subtabla es que el contenido de una canasta es limitado, lo que afecta la eficiencia y la capacidad de búsqueda. El contenido de la canasta se divide en N partes y se coloca en diferentes cestas. Esto rompe las limitaciones de capacidad y mejora la eficiencia de las consultas.
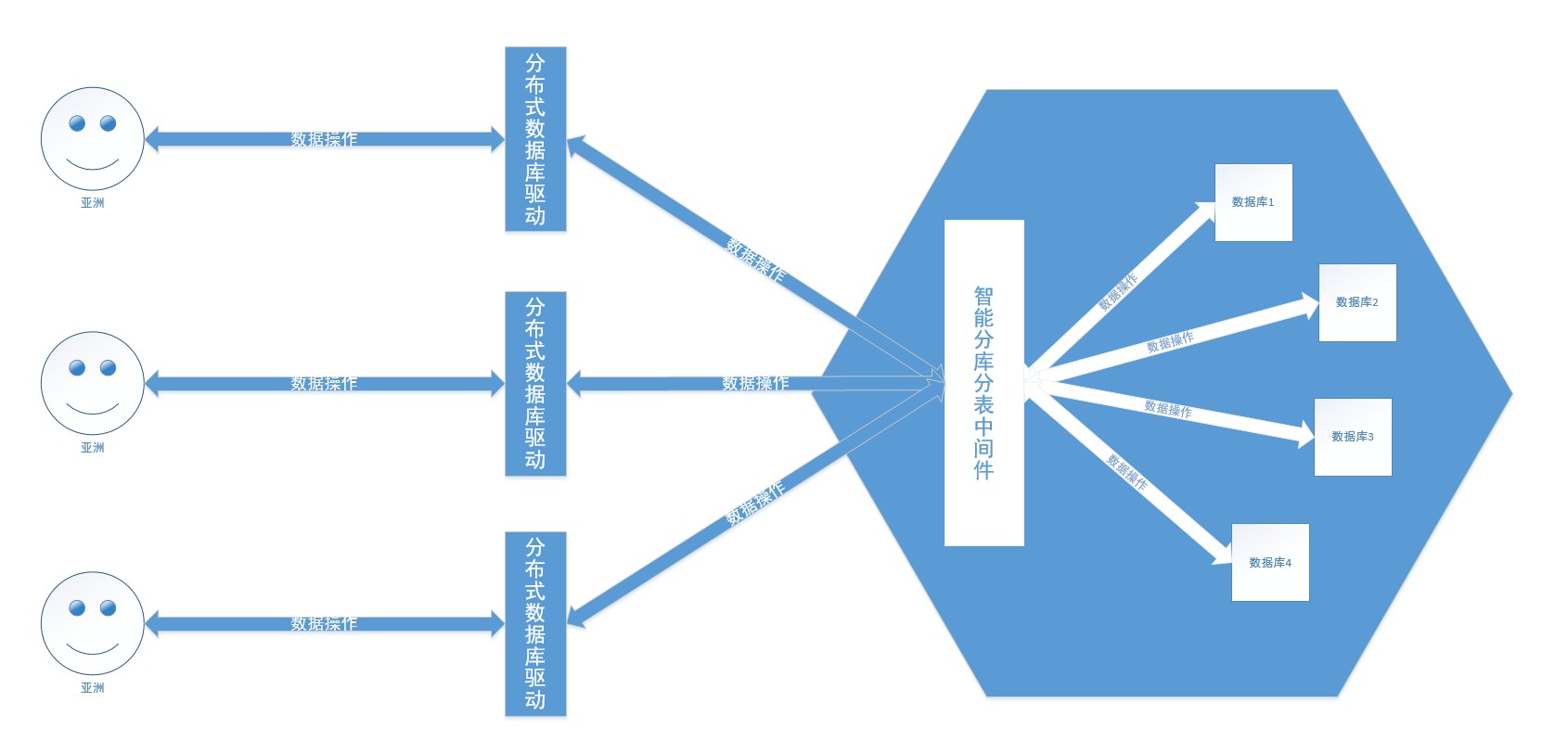
Entonces hablemos de bases de datos distribuidas. Las más populares en China incluyen TDSQL de Tencent, OceanBase de Alibaba, PolarDB, GaussDB de Huawei, etc. Básicamente, se desarrollan de forma independiente, con una gran consistencia y alta disponibilidad, arquitectura de implementación global, expansión horizontal ilimitada distribuida, alto rendimiento, cientos de miles de millones de registros y transacciones entre filas y tablas en cientos de TB de datos (como para la patria) . La base de datos distribuida oculta la estrategia de fragmentación de bases de datos y tablas, fragmenta datos de manera inteligente en bases de datos y tablas y los usa como si operara una base de datos.
Dado que las operaciones de memoria y las operaciones de disco no son del mismo orden de magnitud en absoluto, los proyectos grandes requieren una capa de búfer de tipo memoria para que las bases de datos de tipo disco almacenen en caché los datos del disco en la memoria. La capa de almacenamiento en caché de datos se utiliza para almacenar en caché los datos de toda la capa de datos para acelerar el acceso al sitio. Este proyecto utiliza tecnología AOP y la base de datos en memoria Redis como capa de caché de datos. Consulte el código com/spring/common/aop/CacheDaoAspect.java para obtener más detalles.
Este proyecto utiliza fragmentación JDBC para procesar la base de datos y las tablas de la base de datos. Divida los datos usted mismo según los escenarios comerciales.
Por lo general, los proyectos solo tienen una base de datos y el druida de Alibaba Cloud se usa con más frecuencia en China como grupo de conexiones de bases de datos. Este proyecto utiliza mysql, druid y sharding JDBC. El principio de la fragmentación de datos es mantener múltiples grupos de conexiones de bases de datos en el programa, y cada grupo de conexiones de bases de datos corresponde a una base de datos. La base de datos fragmentada y las tablas fragmentadas utilizan un procesamiento de transacciones de dos fases basado en el protocolo XA . Ruta de configuración com.spring.common.config.shardingJDBC
División vertical: el método de división empresarial se denomina fragmentación vertical, también conocida como división vertical. Distribuya tablas a diferentes bases de datos según el negocio, distribuyendo así la presión a diferentes bases de datos.
División horizontal: no le importa la clasificación de la lógica empresarial, sino que dispersa los datos en varias bibliotecas o tablas de acuerdo con ciertas reglas a través de un determinado campo (o varios campos) de una determinada tabla. Las reglas aquí y el algoritmo involucrado se denominan algoritmos de fragmentación .
( El siguiente contenido está tomado de la documentación de shardingJDBC )
Corresponde a PreciseShardingAlgorithm, que se utiliza para manejar el escenario de = e IN fragmentación utilizando una única clave como clave de fragmentación. Debe usarse con StandardShardingStrategy.
Corresponde al RangeShardingAlgorithm, que se utiliza para manejar escenarios de fragmentación usando BETWEEN AND , > , < , >= y <= usando una única clave como clave de fragmentación. Debe usarse con StandardShardingStrategy.
Corresponde al Algoritmo ComplexKeysSharding, que se utiliza para manejar escenarios en los que se utilizan varias claves como claves de fragmentación para la fragmentación. La lógica que contiene varias claves de fragmentación es compleja y los desarrolladores de aplicaciones deben manejar la complejidad por sí mismos. Debe usarse con ComplexShardingStrategy.
Corresponde a HintShardingAlgorithm, que se utiliza para manejar escenarios donde se utiliza la fragmentación de filas Hint . Debe usarse con HintShardingStrategy.
El usuario inicia sesión para obtener el token y almacenarlo localmente (adminLogin)
El usuario envía un token para obtener información del usuario e información de permisos, y los almacena en la tienda. Dado que F5 hará que se pierda la tienda, se agrega un interceptor a la solicitud de front-end. Si no hay información del usuario ni información de permisos, se volverán a obtener la información y los permisos del usuario (getAdminInfo).
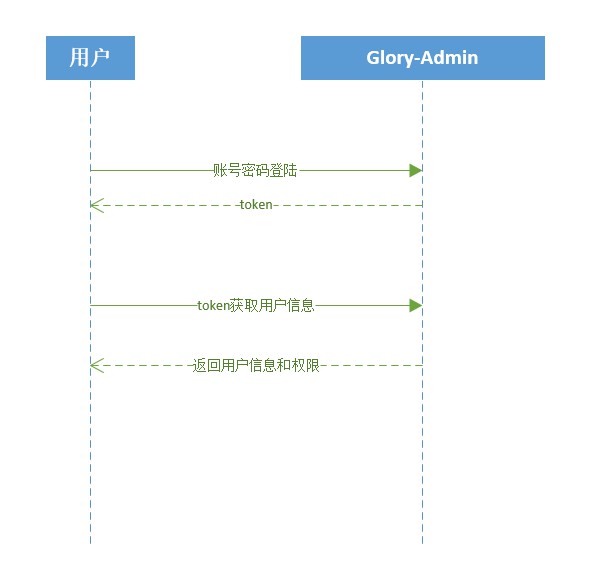
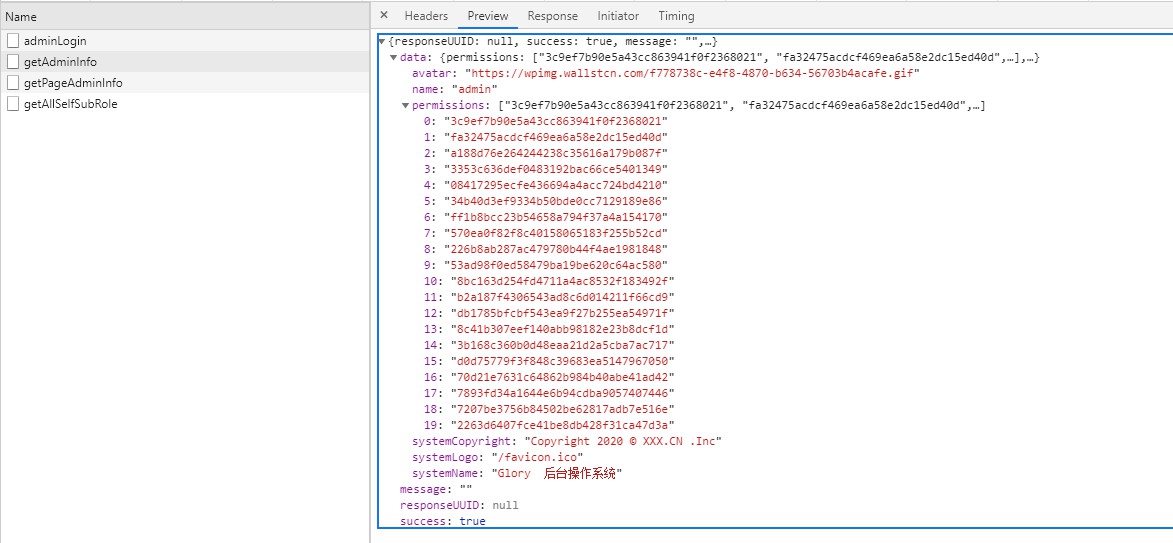
Lo que se devuelve aquí son todos los permisos del usuario en lugar del rol. El usuario genera dinámicamente rutas de front-end.
asyncRoutes es un permiso generado dinámicamente. Si el permiso del usuario corresponde al permiso de la ruta, se mostrará;
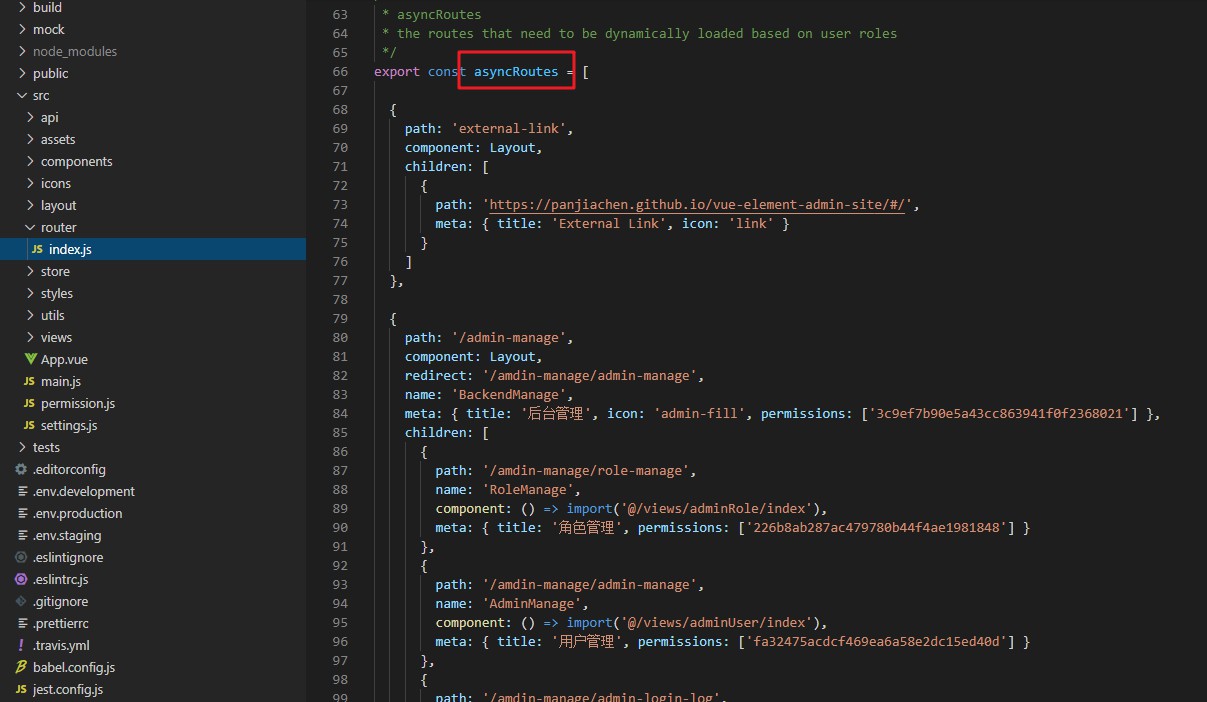
Comunes: operaciones de datos, almacenamiento en caché de datos, operaciones de transacciones.
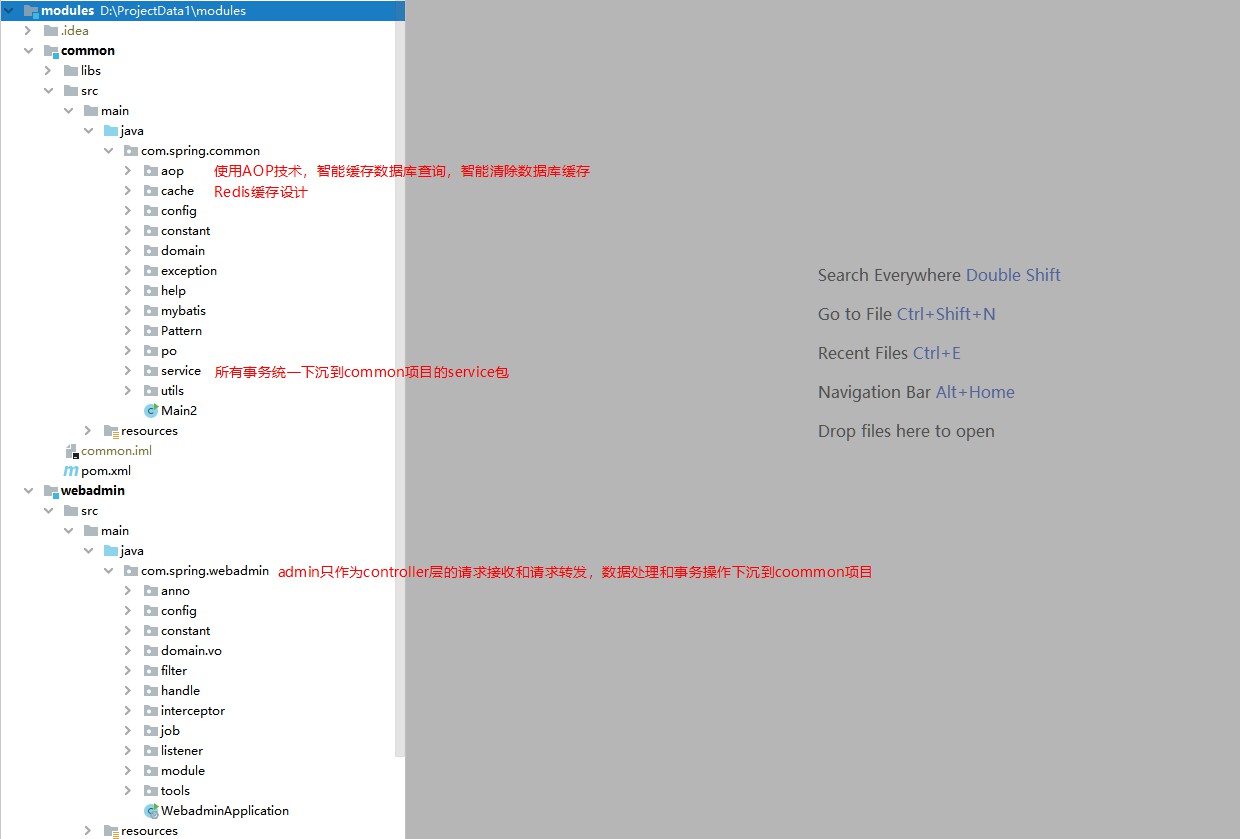
El administrador solo actúa como controlador, que se utiliza para manejar el reenvío entre las solicitudes de los usuarios y el negocio de back-end. (¿Por qué está diseñado así?) Porque algunos sistemas de middleware necesitan usar el marco RPC para el reenvío de solicitudes, y porque algunos sistemas confidenciales desdeñan usar springMVC y eligen vertx para desarrollar de forma independiente la capa de solicitud.
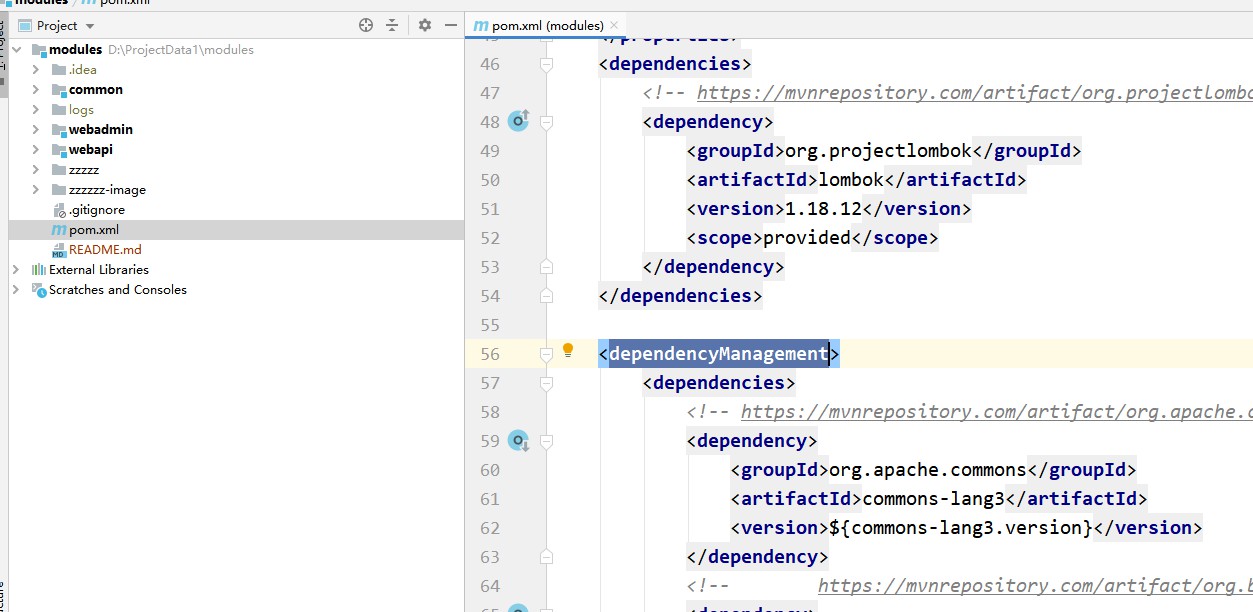
Utilice la herencia de Maven para gestionar las dependencias del proyecto. En los Módulos, las dependencias se introducen a través de dependencyManagement y las versiones se especifican. Los subproyectos heredan los Módulos y no es necesario especificar versiones al introducir dependencias.
Procesamiento de registros globales
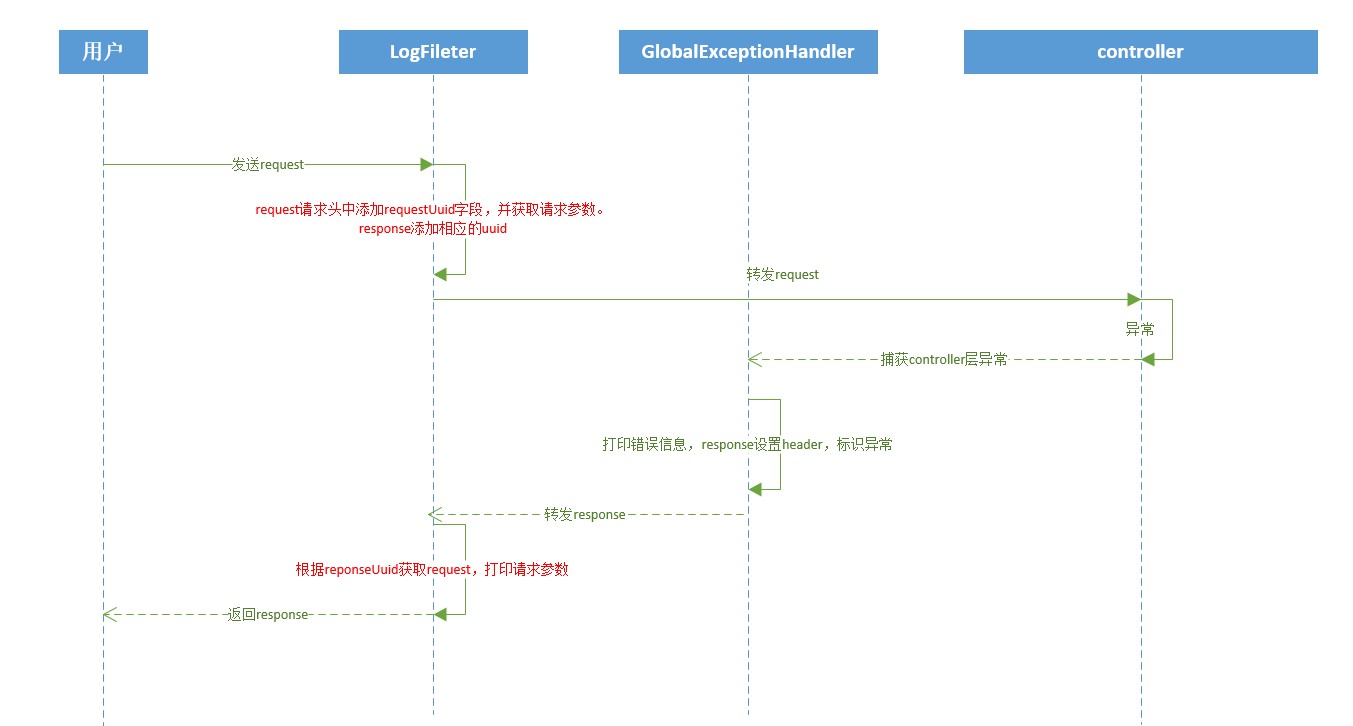
Los registros de operaciones del usuario utilizan métodos de anotación. Si este método necesita registrar registros de operaciones, simplemente agregue la anotación **@OperateLog** encima del nombre del método.
@ OperateLog
@ ApiOperation ( value = "登出" , notes = "登出" )
@ GetMapping ( Route . Admin . adminLogout )
public ResponseDate adminLogout ( HttpServletRequest httpServletRequest ) {
AdminInfoDTO adminInfoDTO = AdminTool . getAdminUser ( httpServletRequest );
AdminUser adminUser = adminUserMapper . selectByPrimaryKey ( adminInfoDTO . getAdminUk ());
adminUser . setNowToken ( "log-out" );
int result = adminUserService . updateAdminToken ( adminUser );
return ResponseDate . builder ()
. success ( result == 1 )
. build ();
}

