El objetivo de este repositorio es realizar un seguimiento de algunos trucos GGPLOT2 ordenados que he aprendido. Esto supone que se ha familiarizado con los conceptos básicos de GGPLOT2 y puede construir algunas buenas tramas propias. Si no es así, examina el libro en tu valía.
No me adapto increíblemente en las tramas de forma gloriosamente tipográfica y los temas y paletas de colores finamente fingentes, por lo que tendrías que perdonarme. El conjunto de datos mpg es muy versátil para trazar, por lo que verá mucho de eso mientras lee. Los paquetes de extensión son geniales, y me he incrustado, pero trataré de limitarme a los trucos de vainilla GGPLOT2 aquí.
Por ahora, esta será principalmente una bolsa de trucos solo para lectura, pero puedo decidir más tarde ponerlos en grupos separados en otros archivos.
Cargando la biblioteca y estableciendo un tema de trazado. El primer truco aquí es usar theme_set() para establecer un tema para todas sus tramas en un documento. Si se encuentra estableciendo un tema muy detallado para cada trama, aquí está el lugar donde configura todas sus configuraciones comunes. ¡Entonces nunca vuelvas a escribir una novela de elementos temáticos nunca más !
library( ggplot2 )
library( scales )
theme_set(
# Pick a starting theme
theme_gray() +
# Add your favourite elements
theme(
axis.line = element_line(),
panel.background = element_rect( fill = " white " ),
panel.grid.major = element_line( " grey95 " , linewidth = 0.25 ),
legend.key = element_rect( fill = NA )
)
) La documentación ?aes no te dice esto, pero puedes empalmar el argumento mapping en GGPLOT2. ¿Qué significa eso? Bueno, significa que puedes componer el argumento mapping sobre la marcha !!! . Esto es especialmente ingenioso si necesita reciclar la estética de vez en cuando.
my_mapping <- aes( x = foo , y = bar )
aes( colour = qux , !!! my_mapping )
# > Aesthetic mapping:
# > * `x` -> `foo`
# > * `y` -> `bar`
# > * `colour` -> `qux` Mi uso favorito de esto es hacer que el color fill coincida con el color colour , pero un poco más claro 2 . Usaremos el sistema de evaluación tardía para esto, after_scale() en este caso, que verá más en la sección después de esta. Repetiré este truco un par de veces a lo largo de este documento.
my_fill <- aes( fill = after_scale(alpha( colour , 0.3 )))
ggplot( mpg , aes( displ , hwy )) +
geom_point(aes( colour = factor ( cyl ), !!! my_fill ), shape = 21 )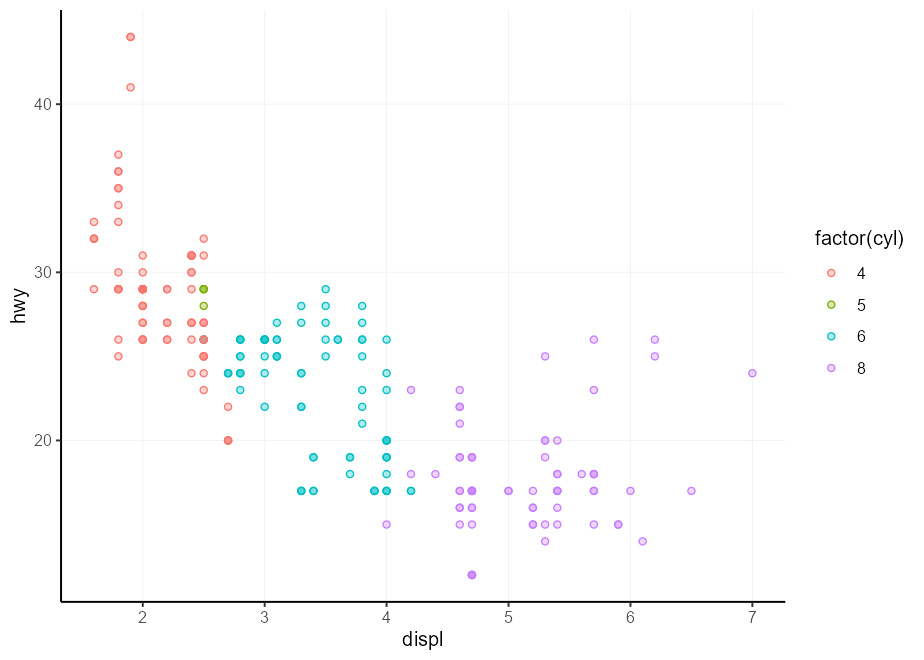
Puede encontrarse en una situación en la que se le pide que haga un mapa de calor de un pequeño número de variables. Por lo general, las escalas secuenciales funcionan de luz a oscura o viceversa, lo que hace que el texto de un solo color sea difícil de leer. Podríamos diseñar un método para escribir automáticamente el texto en blanco sobre un fondo oscuro y negro sobre un fondo claro. La siguiente función considera un valor de ligereza para un color y devuelve en blanco o negro dependiendo de esa ligereza.
contrast <- function ( colour ) {
out <- rep( " black " , length( colour ))
light <- farver :: get_channel( colour , " l " , space = " hcl " )
out [ light < 50 ] <- " white "
out
} Ahora, podemos hacer una estética para ser empalmada en el argumento mapping de una capa a pedido.
autocontrast <- aes( colour = after_scale(contrast( fill )))Por último, podemos probar nuestro artilugio automático de contraste. Puede notar que se adapta a la escala, por lo que no necesitaría hacer un montón de formateo condicional para esto.
cors <- cor( mtcars )
# Melt matrix
df <- data.frame (
col = colnames( cors )[as.vector(col( cors ))],
row = rownames( cors )[as.vector(row( cors ))],
value = as.vector( cors )
)
# Basic plot
p <- ggplot( df , aes( row , col , fill = value )) +
geom_raster() +
geom_text(aes( label = round( value , 2 ), !!! autocontrast )) +
coord_equal()
p + scale_fill_viridis_c( direction = 1 )
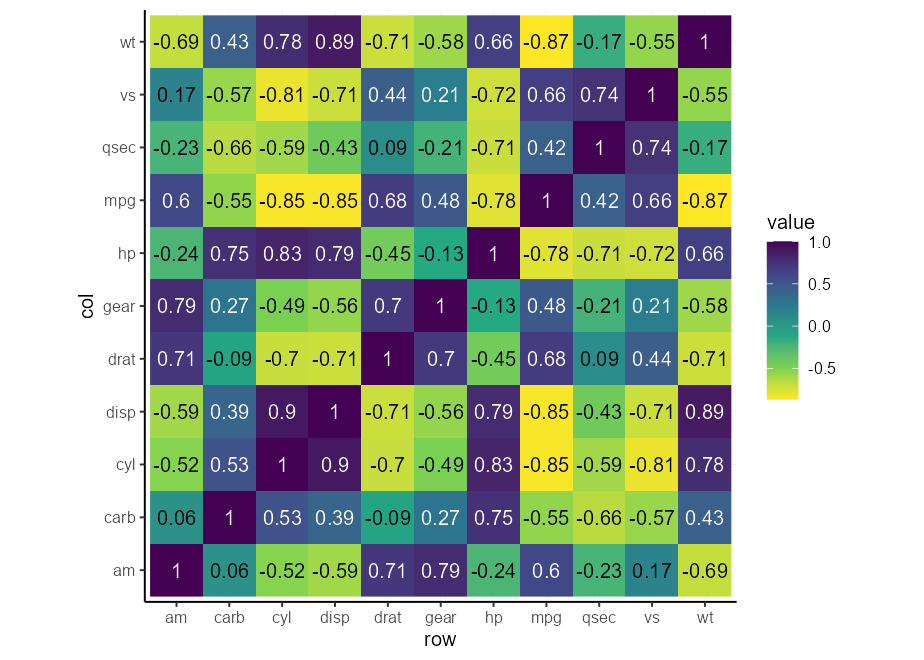
p + scale_fill_viridis_c( direction = - 1 )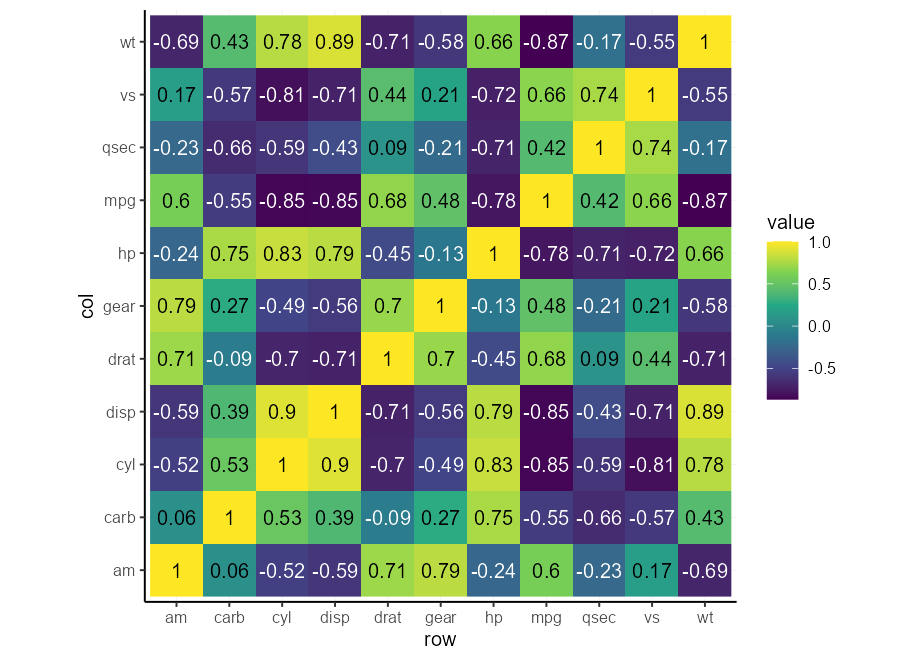
Hay algunas extensiones que ofrecen versiones de las cosas de medio geom. De los que conozco, Gghalves y el paquete See ofrecen algunas medias geoms.
Aquí es cómo abusar del sistema de evaluación retrasado para hacer el suyo. Esto puede ser útil si no está dispuesto a asumir una dependencia adicional para solo esta función.
El estuche fácil es el diagrama de caja. Puede configurar xmin o xmax en after_scale(x) para mantener las partes derecha e izquierda de un diagrama de caja respectivamente. Esto todavía funciona bien con position = "dodge" .
# A basic plot to reuse for examples
p <- ggplot( mpg , aes( class , displ , colour = class , !!! my_fill )) +
guides( colour = " none " , fill = " none " ) +
labs( y = " Engine Displacement [L] " , x = " Type of car " )
p + geom_boxplot(aes( xmin = after_scale( x )))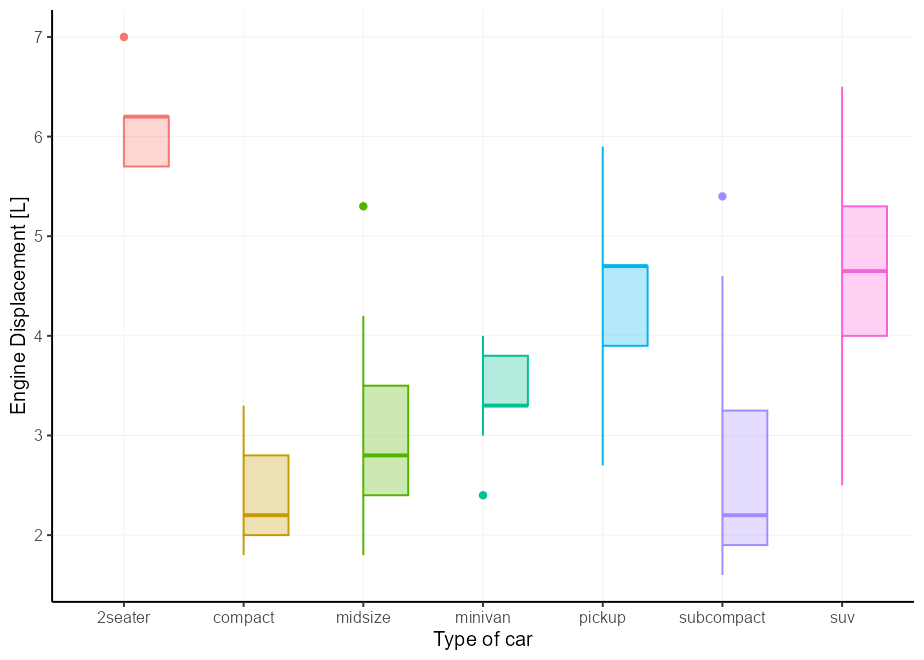
Lo mismo que funciona para los diagramas de caja, también funciona para Borras de error.
p + geom_errorbar(
stat = " summary " ,
fun.data = mean_se ,
aes( xmin = after_scale( x ))
)
Una vez más, podemos hacer lo mismo por las parcelas de violín, pero la capa se queja de no saber sobre la estética xmin . Utiliza esa estética, pero solo después de que los datos se han configurado, por lo que no pretende ser una estética accesible para el usuario. Podemos silenciar la advertencia actualizando el xmin predeterminado a NULL , lo que significa que no se quejará, pero tampoco la usa si está ausente.
update_geom_defaults( " violin " , list ( xmin = NULL ))
p + geom_violin(aes( xmin = after_scale( x )))
Esta vez no me dejó como un ejercicio para el lector, pero solo quería mostrar cómo funcionaría si combinara dos mitades y las quisieran un poco compensadas entre sí. Abusaremos de las barras de error para servir como alimentos básicos para los gráficos de caja.
# A small nudge offset
offset <- 0.025
# We can pre-specify the mappings if we plan on recycling some
right_nudge <- aes(
xmin = after_scale( x ),
x = stage( class , after_stat = x + offset )
)
left_nudge <- aes(
xmax = after_scale( x ),
x = stage( class , after_stat = x - offset )
)
# Combining
p +
geom_violin( right_nudge ) +
geom_boxplot( left_nudge ) +
geom_errorbar( left_nudge , stat = " boxplot " , width = 0.3 )
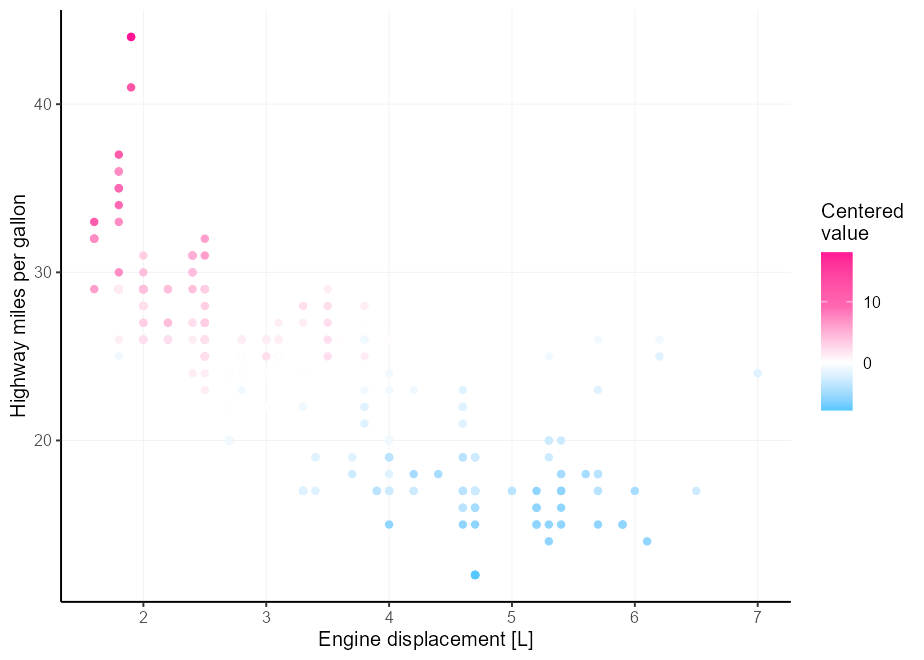
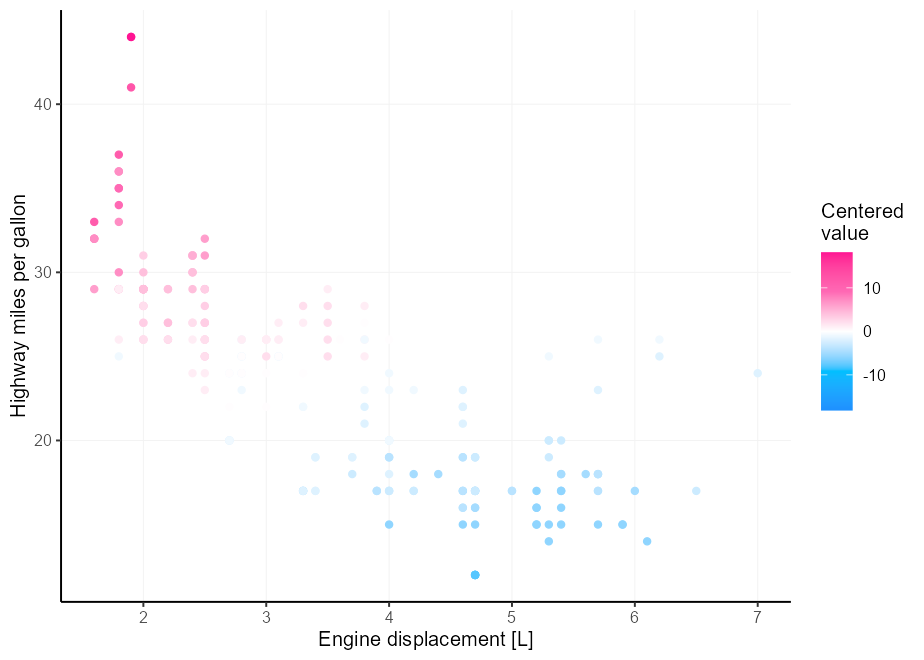
Digamos que tienes una mejor intuición de color que yo, y tres colores no son suficientes para tus necesidades de paleta de colores divergentes. Un punto de dolor es que es difícil obtener el punto medio correcto si sus límites no están perfectamente centrados en él. Ingrese el argumento rescaler en la liga con scales::rescale_mid() .
my_palette <- c( " dodgerblue " , " deepskyblue " , " white " , " hotpink " , " deeppink " )
p <- ggplot( mpg , aes( displ , hwy , colour = cty - mean( cty ))) +
geom_point() +
labs(
x = " Engine displacement [L] " ,
y = " Highway miles per gallon " ,
colour = " Centered n value "
)
p +
scale_colour_gradientn(
colours = my_palette ,
rescaler = ~ rescale_mid( .x , mid = 0 )
)
Una alternativa es simplemente centrar los límites en x. Podemos hacerlo proporcionando una función a los límites de la escala.
p +
scale_colour_gradientn(
colours = my_palette ,
limits = ~ c( - 1 , 1 ) * max(abs( .x ))
)
Puede etiquetar puntos con geom_text() , pero un problema potencial es que el texto y los puntos se superponen.
set.seed( 0 )
df <- USArrests [sample(nrow( USArrests ), 5 ), ]
df $ state <- rownames( df )
q <- ggplot( df , aes( Murder , Rape , label = state )) +
geom_point()
q + geom_text()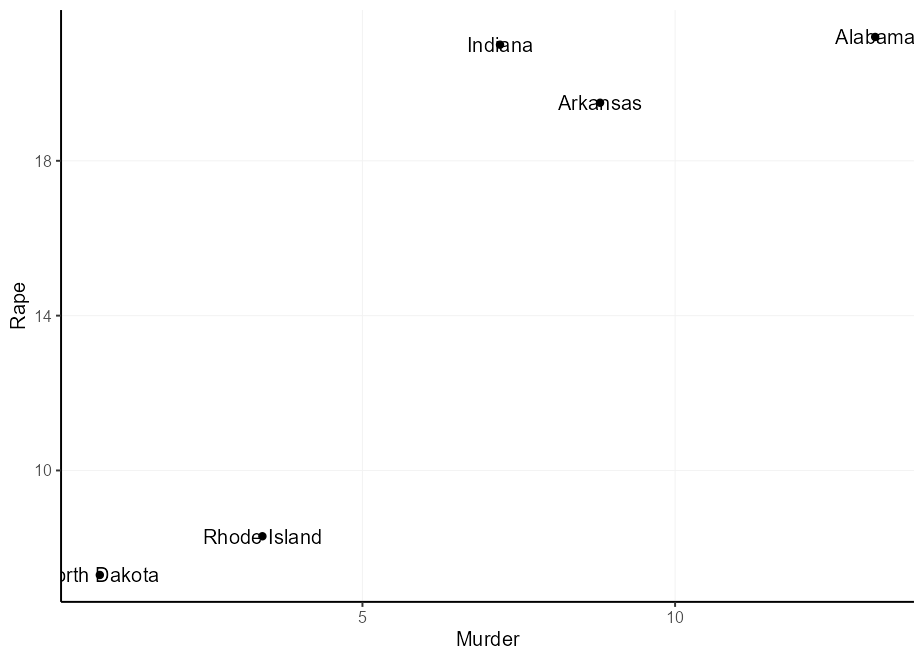
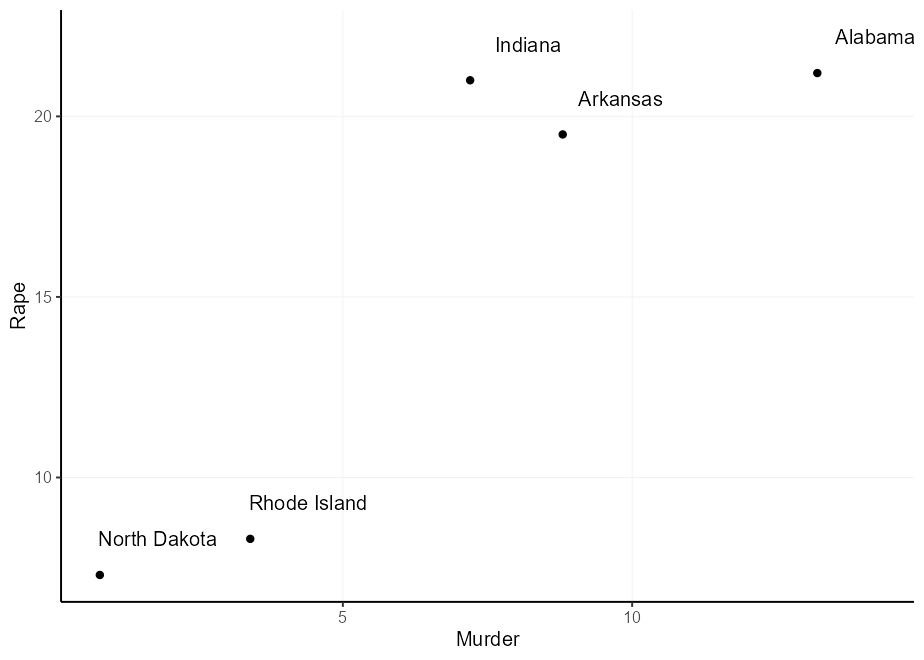
Hay varias soluciones típicas a este problema, y todas vienen con inconvenientes:
nudge_x y nudge_y . El problema aquí es que estos se definen en las unidades de datos, por lo que el espacio es impredecible, y no hay forma de que estos dependan de las ubicaciones originales.hjust y vjust . Le permite depender de las ubicaciones originales, pero estos no tienen compensaciones naturales.Aquí hay opciones 2 y 3 en acción:
q + geom_text( nudge_x = 1 , nudge_y = 1 )
q + geom_text(aes(
hjust = Murder > mean( Murder ),
vjust = Rape > mean( Rape )
))
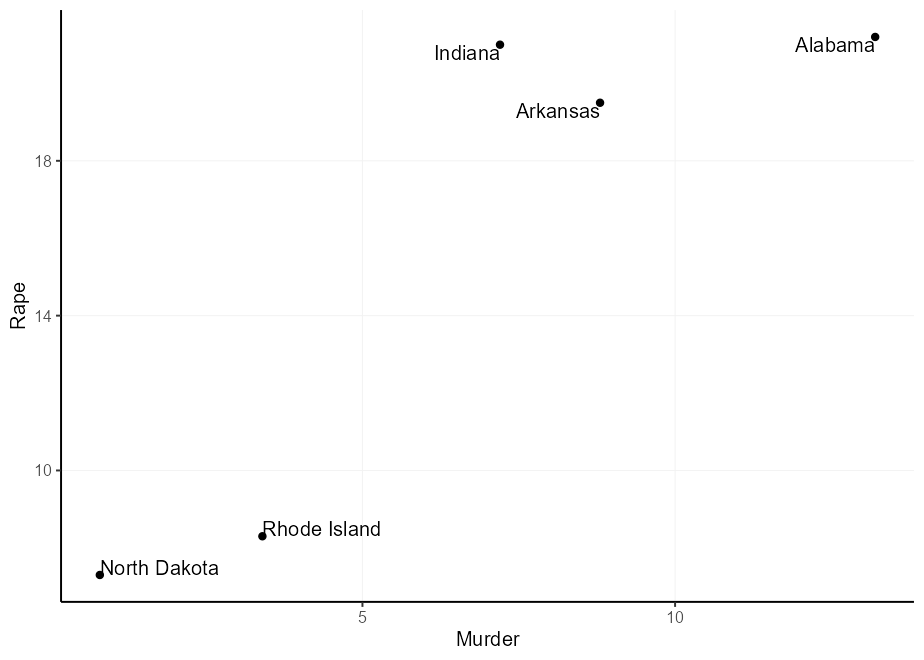
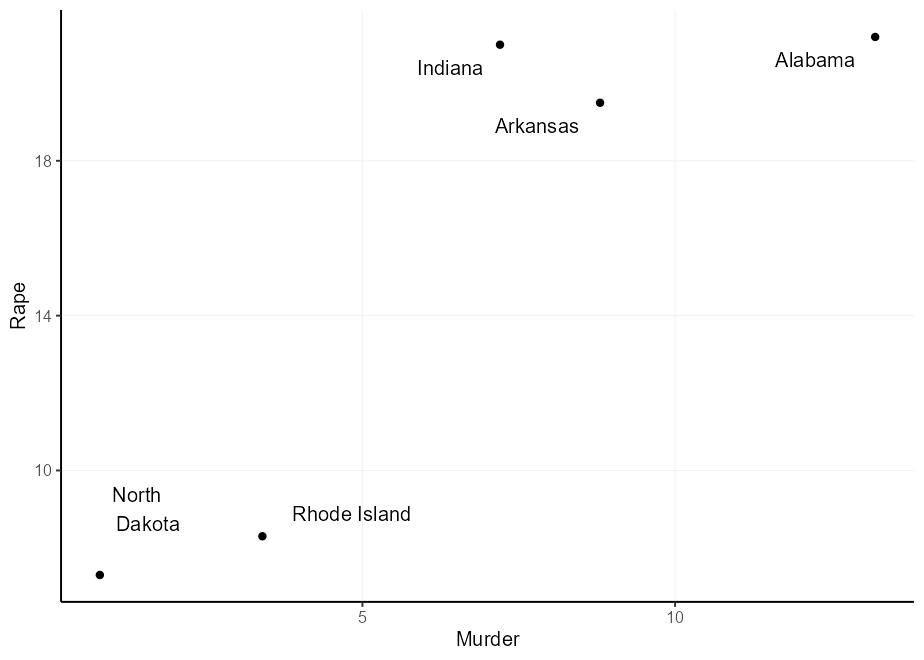
Podrías pensar: "Puedo multiplicar las justificaciones para obtener un desplazamiento más amplio", y tendrías razón. Sin embargo, debido a que la justificación depende del tamaño del texto, puede obtener compensaciones desiguales. Observe en la trama a continuación que 'Dakota del Norte' se compensa demasiado en la dirección Y y 'Rhode Island' en la dirección X.
q + geom_text(aes(
label = gsub( " North Dakota " , " North n Dakota " , state ),
hjust = (( Murder > mean( Murder )) - 0.5 ) * 1.5 + 0.5 ,
vjust = (( Rape > mean( Rape )) - 0.5 ) * 3 + 0.5
))
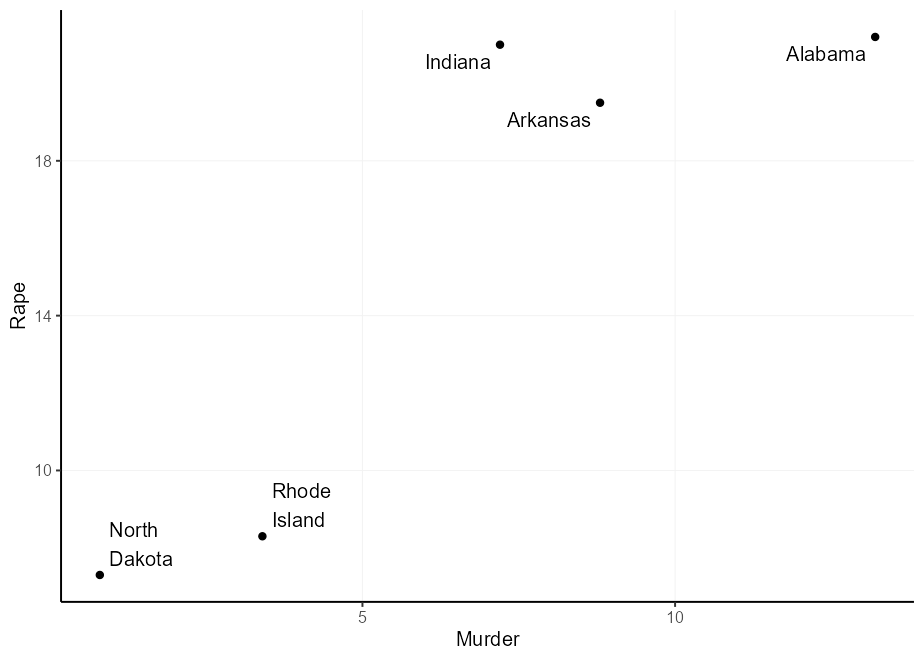
Lo bueno de geom_label() es que puede apagar el cuadro de etiqueta y mantener el texto. De esa manera, puede continuar utilizando otras cosas útiles, como la label.padding Configuración del marcador, para dar un desplazamiento absoluto (independiente de los datos) del texto a la etiqueta.
q + geom_label(
aes(
label = gsub( " " , " n " , state ),
hjust = Murder > mean( Murder ),
vjust = Rape > mean( Rape )
),
label.padding = unit( 5 , " pt " ),
label.size = NA , fill = NA
)
Esto solía ser un consejo sobre colocar etiquetas de faceta en los paneles, lo que solía ser complicado. Con GGPLOT2 3.5.0, ya no tiene que jugar con la configuración de posiciones infinitas y ajustar los parámetros hjust o vjust . Ahora puede usar x = I(0.95), y = I(0.95) para colocar el texto en la esquina superior derecha. Abra los detalles para ver la vieja punta.
Poner anotaciones de texto en parcelas facetadas es un dolor, porque los límites pueden variar por panel, por lo que es muy difícil encontrar la posición correcta. Una extensión que explora aliviar este dolor es la extensión del etiquetador, pero podemos hacer algo similar en Vanilla GGPLOT2.
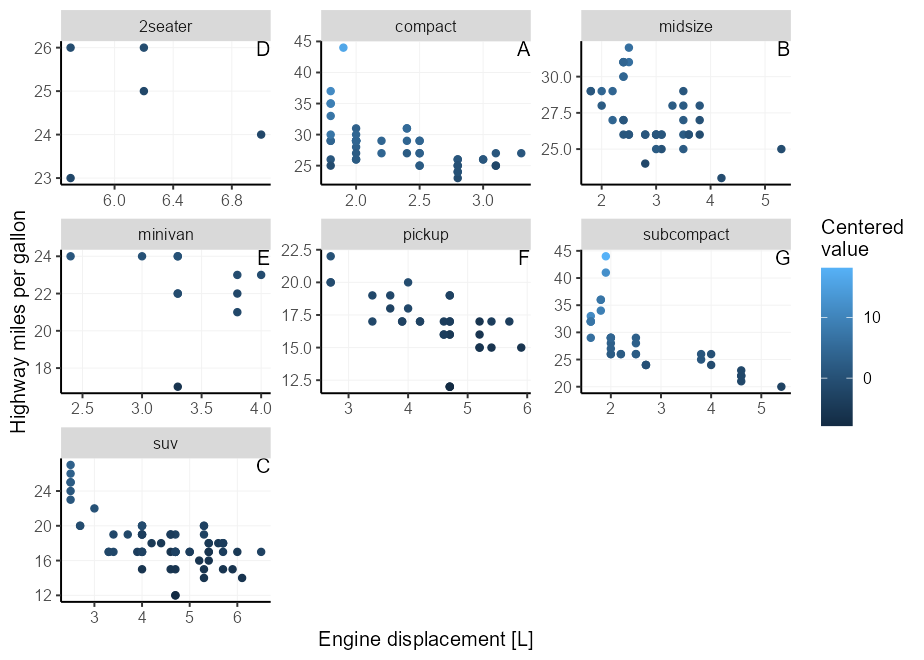
Afortunadamente, hay un mecánico en los ejes de posición de GGPLOT2 que -Inf Inf se interpreten como el límite mínimo y máximo de la escala respectivamente 3 . Puede explotar esto eligiendo x = Inf, y = Inf para poner las etiquetas en una esquina. También puede usar -Inf en lugar de Inf para colocar en la parte inferior en lugar de la parte superior o izquierda en lugar de la derecha.
Necesitamos coincidir con los argumentos hjust / vjust al lado de la trama. Para x/y = Inf , necesitarían ser hjust/vjust = 1 , y para x/y = -Inf necesitan ser hjust/vjust = 0 .
p + facet_wrap( ~ class , scales = " free " ) +
geom_text(
# We only need 1 row per facet, so we deduplicate the facetting variable
data = ~ subset( .x , ! duplicated( class )),
aes( x = Inf , y = Inf , label = LETTERS [seq_along( class )]),
hjust = 1 , vjust = 1 ,
colour = " black "
)
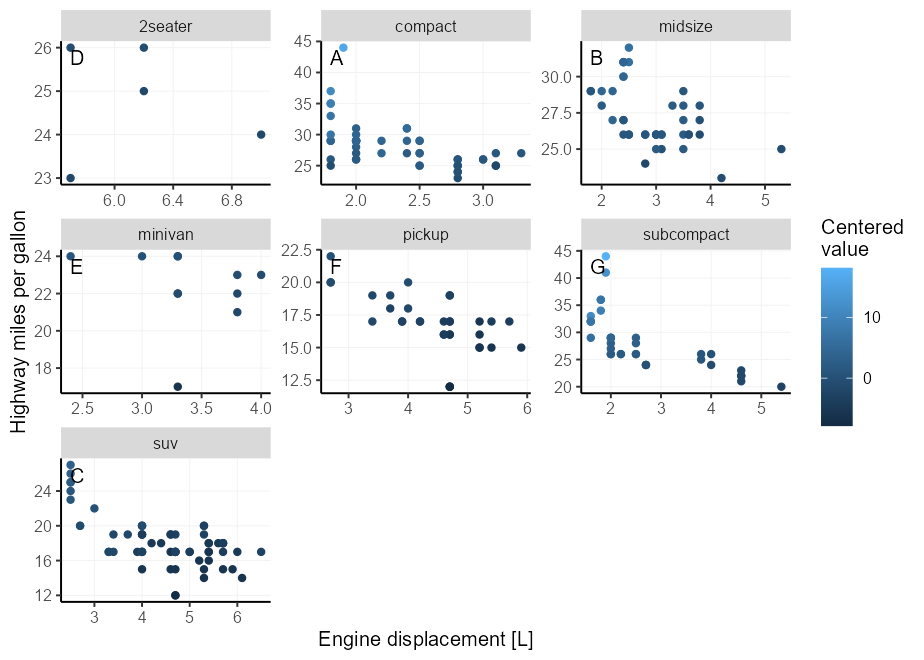
Desafortunadamente, esto coloca el texto directamente en la frontera del panel, que puede ofender nuestro sentido de belleza. Podemos obtener un poco más elegante usando geom_label() , lo que nos permite controlar con mayor precisión el espacio entre el texto y los bordes del panel estableciendo el argumento label.padding .
Además, podemos usar label.size = NA, fill = NA Para fines de ilustración, ahora colocamos la etiqueta en la parte superior izquierda en lugar de la primera derecha.
p + facet_wrap( ~ class , scales = " free " ) +
geom_label(
data = ~ subset( .x , ! duplicated( class )),
aes( x = - Inf , y = Inf , label = LETTERS [seq_along( class )]),
hjust = 0 , vjust = 1 , label.size = NA , fill = NA ,
label.padding = unit( 5 , " pt " ),
colour = " black "
)
Digamos que tenemos la tarea de hacer un montón de gráficos similares, con diferentes conjuntos de datos y columnas. Por ejemplo, es posible que queramos hacer una serie de bolos 4 con algunos pre-establos específicos: nos gustaría que las barras toquen el eje X y no dibujen líneas de cuadrículas verticales.
Una forma bien conocida de hacer un montón de tramas similares es envolver la construcción de la trama en una función. De esa manera, puede usar codificar todos los preajustes que desee en su función.
Es posible que no sepa, hay varios métodos para programar con la función aes() , y usar {{ }} (curly-curly) es una de las formas más flexibles 5 .
barplot_fun <- function ( data , x ) {
ggplot( data , aes( x = {{ x }})) +
geom_bar( width = 0.618 ) +
scale_y_continuous( expand = c( 0 , 0 , 0.05 , 0 )) +
theme( panel.grid.major.x = element_blank())
}
barplot_fun( mpg , class )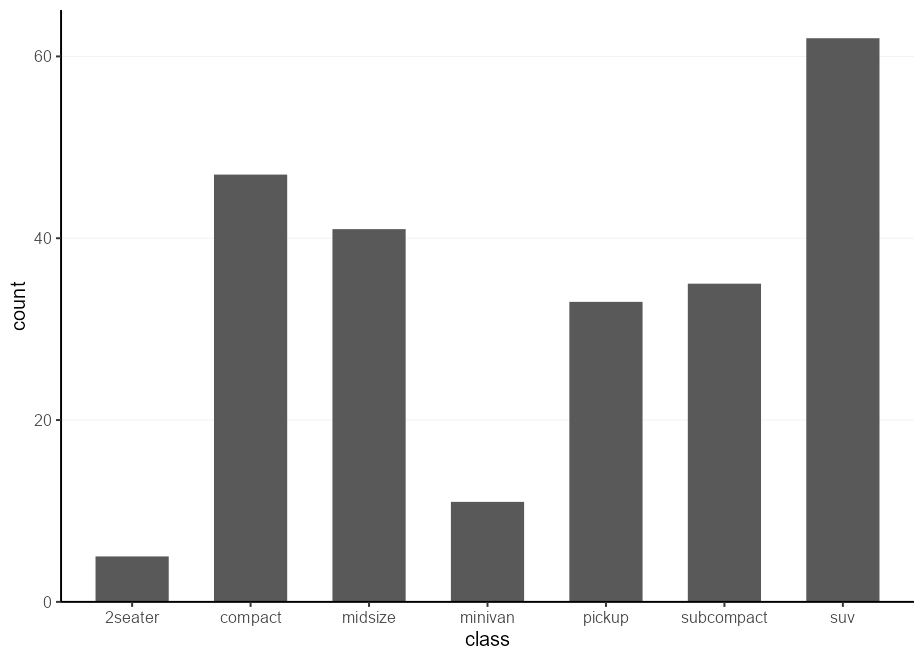
Un inconveniente de este enfoque es que bloquea cualquier estética en los argumentos de la función. Para dar esto, una forma aún más simple es simplemente pasar ... directamente a aes() .
barplot_fun <- function ( data , ... ) {
ggplot( data , aes( ... )) +
geom_bar( width = 0.618 ) +
scale_y_continuous( expand = c( 0 , 0 , 0.1 , 0 )) +
theme( panel.grid.major.x = element_blank())
}
barplot_fun( mpg , class , colour = factor ( cyl ), !!! my_fill )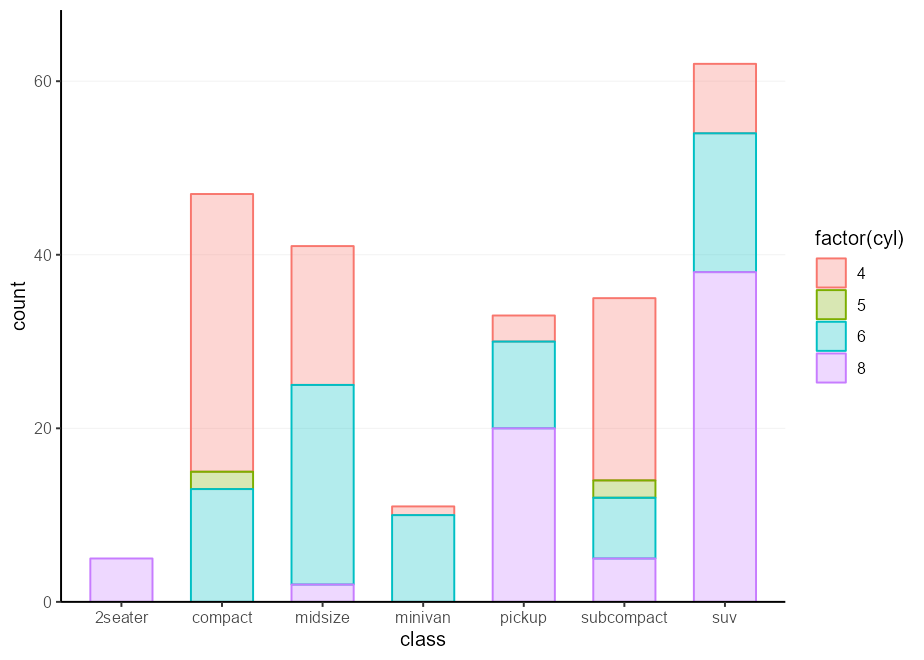
Otro método para hacer algo muy similar es usar 'esqueletos' de la trama. La idea detrás de un esqueleto es que puede construir una trama, con o sin ningún argumento data , y agregar los detalles más adelante. Luego, cuando realmente desee hacer un gráfico, puede usar el %+% para completar o reemplazar el conjunto de datos, y + aes(...) para establecer la estética relevante.
barplot_skelly <- ggplot() +
geom_bar( width = 0.618 ) +
scale_y_continuous( expand = c( 0 , 0 , 0.1 , 0 )) +
theme( panel.grid.major.x = element_blank())
my_plot <- barplot_skelly % + % mpg +
aes( class , colour = factor ( cyl ), !!! my_fill )
my_plot 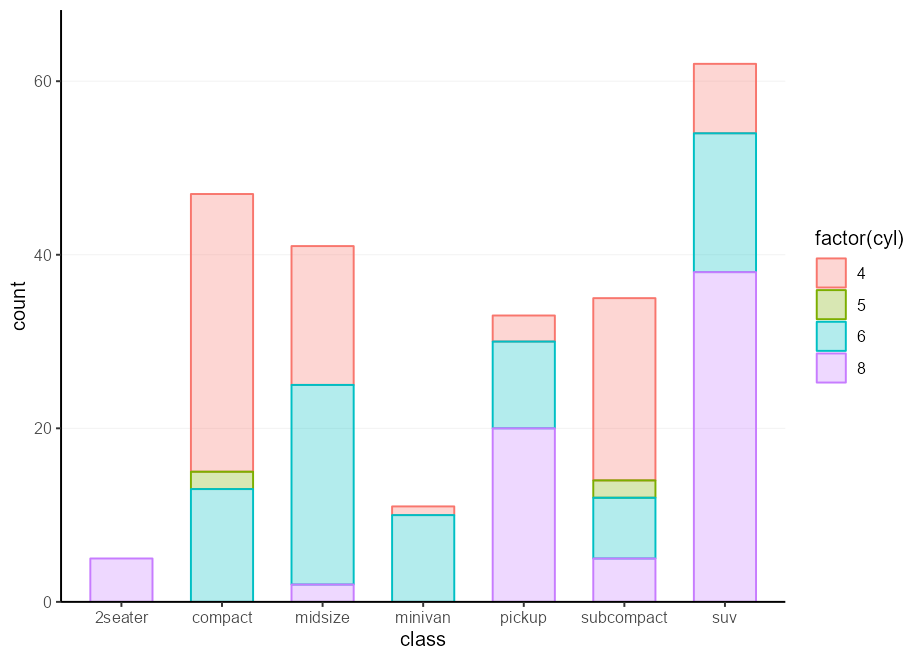
Una buena cosa de estos esqueletos es que incluso cuando ya ha completado los data y los argumentos mapping , puede reemplazarlos una y otra vez.
my_plot % + % mtcars +
aes( factor ( carb ), colour = factor ( cyl ), !!! my_fill )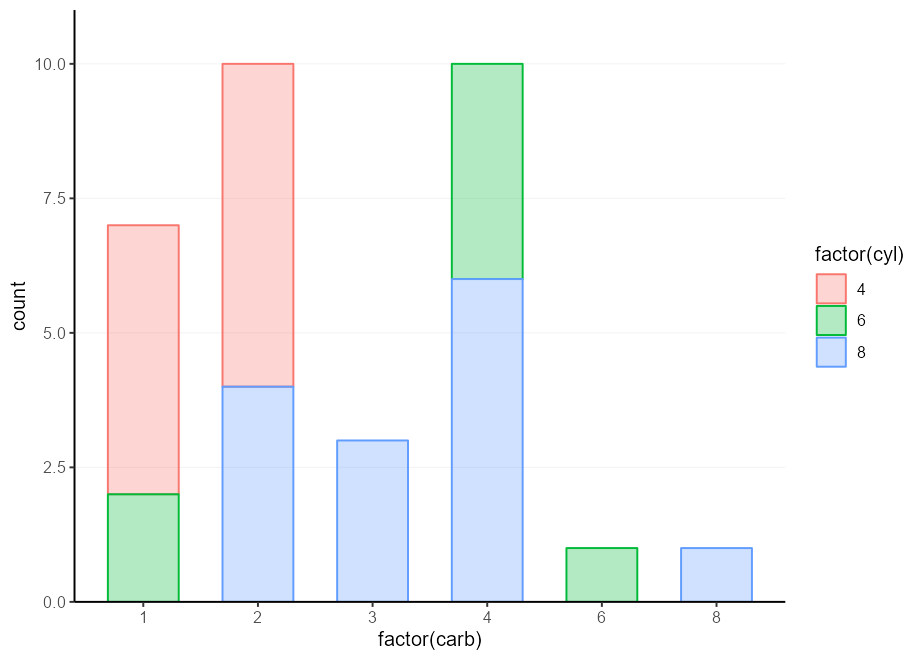
La idea aquí es no esqueletizar toda la trama, sino solo un conjunto de piezas frecuentemente reutilizado. Por ejemplo, es posible que queramos etiquetar nuestra placa y unir todas las cosas que componen una placa etiquetada. El truco para esto es no agregar estos componentes junto con + , sino simplemente ponerlos en una list() . Luego puede + su lista junto con la llamada de la trama principal.
labelled_bars <- list (
geom_bar( my_fill , width = 0.618 ),
geom_text(
stat = " count " ,
aes( y = after_stat( count ),
label = after_stat( count ),
fill = NULL , colour = NULL ),
vjust = - 1 , show.legend = FALSE
),
scale_y_continuous( expand = c( 0 , 0 , 0.1 , 0 )),
theme( panel.grid.major.x = element_blank())
)
ggplot( mpg , aes( class , colour = factor ( cyl ))) +
labelled_bars +
ggtitle( " The `mpg` dataset " )
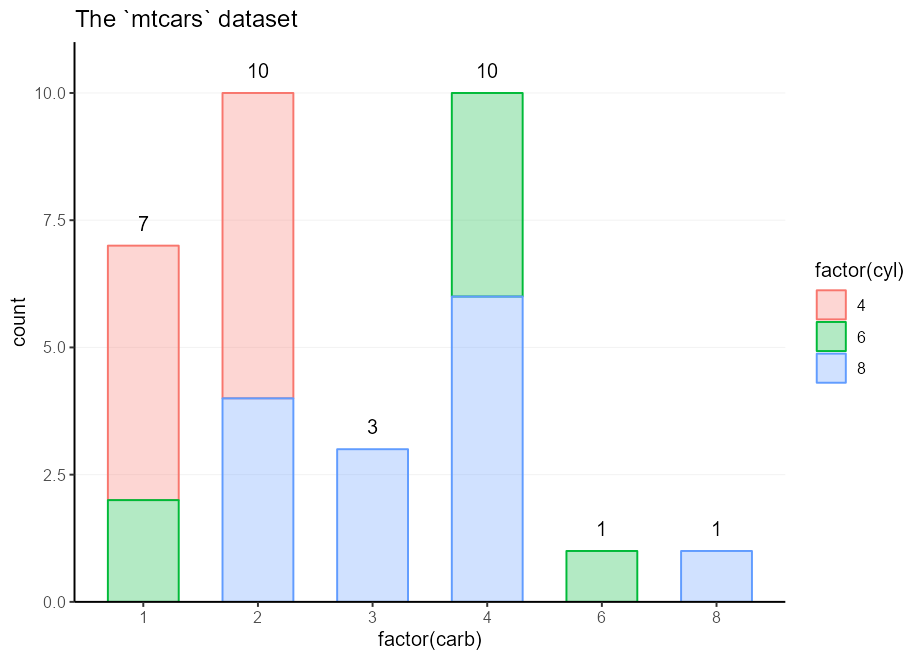
ggplot( mtcars , aes( factor ( carb ), colour = factor ( cyl ))) +
labelled_bars +
ggtitle( " The `mtcars` dataset " )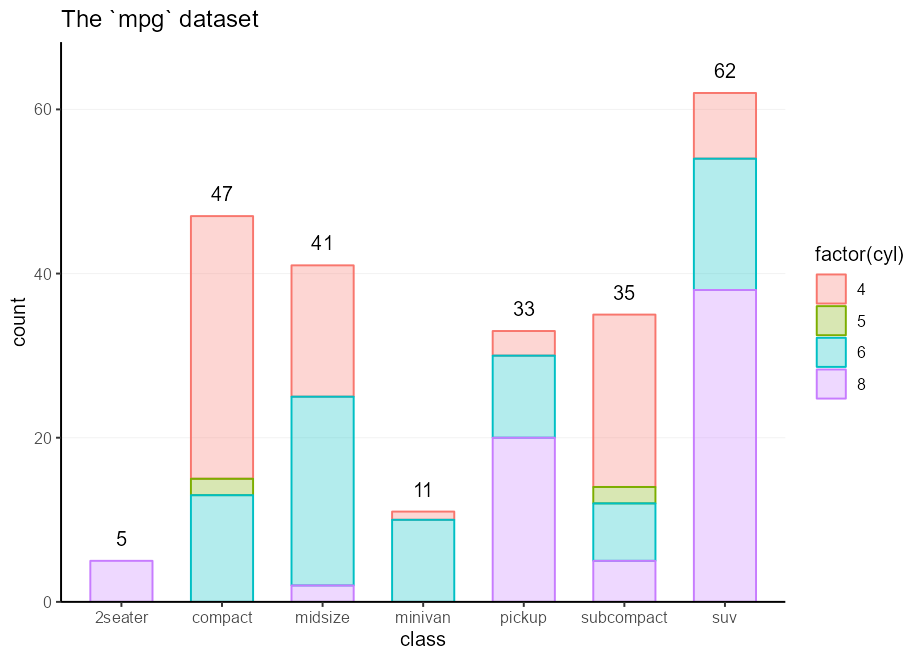
#> ─ Session info ───────────────────────────────────────────────────────────────
#> setting value
#> version R version 4.3.2 (2023-10-31 ucrt)
#> os Windows 11 x64 (build 22631)
#> system x86_64, mingw32
#> ui RTerm
#> language (EN)
#> collate English_Netherlands.utf8
#> ctype English_Netherlands.utf8
#> tz Europe/Amsterdam
#> date 2024-02-27
#> pandoc 3.1.1
#>
#> ─ Packages ───────────────────────────────────────────────────────────────────
#> package * version date (UTC) lib source
#> cli 3.6.2 2023-12-11 [] CRAN (R 4.3.2)
#> colorspace 2.1-0 2023-01-23 [] CRAN (R 4.3.2)
#> digest 0.6.34 2024-01-11 [] CRAN (R 4.3.2)
#> dplyr 1.1.4 2023-11-17 [] CRAN (R 4.3.2)
#> evaluate 0.23 2023-11-01 [] CRAN (R 4.3.2)
#> fansi 1.0.6 2023-12-08 [] CRAN (R 4.3.2)
#> farver 2.1.1 2022-07-06 [] CRAN (R 4.3.2)
#> fastmap 1.1.1 2023-02-24 [] CRAN (R 4.3.2)
#> generics 0.1.3 2022-07-05 [] CRAN (R 4.3.2)
#> ggplot2 * 3.5.0.9000 2024-02-27 [] local
#> glue 1.7.0 2024-01-09 [] CRAN (R 4.3.2)
#> gtable 0.3.4 2023-08-21 [] CRAN (R 4.3.2)
#> highr 0.10 2022-12-22 [] CRAN (R 4.3.2)
#> htmltools 0.5.7 2023-11-03 [] CRAN (R 4.3.2)
#> knitr 1.45 2023-10-30 [] CRAN (R 4.3.2)
#> labeling 0.4.3 2023-08-29 [] CRAN (R 4.3.1)
#> lifecycle 1.0.4 2023-11-07 [] CRAN (R 4.3.2)
#> magrittr 2.0.3 2022-03-30 [] CRAN (R 4.3.2)
#> munsell 0.5.0 2018-06-12 [] CRAN (R 4.3.2)
#> pillar 1.9.0 2023-03-22 [] CRAN (R 4.3.2)
#> pkgconfig 2.0.3 2019-09-22 [] CRAN (R 4.3.2)
#> R6 2.5.1 2021-08-19 [] CRAN (R 4.3.2)
#> ragg 1.2.7 2023-12-11 [] CRAN (R 4.3.2)
#> rlang 1.1.3 2024-01-10 [] CRAN (R 4.3.2)
#> rmarkdown 2.25 2023-09-18 [] CRAN (R 4.3.2)
#> rstudioapi 0.15.0 2023-07-07 [] CRAN (R 4.3.2)
#> scales * 1.3.0 2023-11-28 [] CRAN (R 4.3.2)
#> sessioninfo 1.2.2 2021-12-06 [] CRAN (R 4.3.2)
#> systemfonts 1.0.5 2023-10-09 [] CRAN (R 4.3.2)
#> textshaping 0.3.7 2023-10-09 [] CRAN (R 4.3.2)
#> tibble 3.2.1 2023-03-20 [] CRAN (R 4.3.2)
#> tidyselect 1.2.0 2022-10-10 [] CRAN (R 4.3.2)
#> utf8 1.2.4 2023-10-22 [] CRAN (R 4.3.2)
#> vctrs 0.6.5 2023-12-01 [] CRAN (R 4.3.2)
#> viridisLite 0.4.2 2023-05-02 [] CRAN (R 4.3.2)
#> withr 3.0.0 2024-01-16 [] CRAN (R 4.3.2)
#> xfun 0.41 2023-11-01 [] CRAN (R 4.3.2)
#> yaml 2.3.8 2023-12-11 [] CRAN (R 4.3.2)
#>
#>
#> ──────────────────────────────────────────────────────────────────────────────
Bueno, debe hacerlo una vez al comienzo de su documento. ¡Pero entonces nunca más! Excepto en su próximo documento. Simplemente escriba un script y source() plot_defaults.R que desde su documento. Copiar pete ese script para cada proyecto. Entonces, verdaderamente, nunca más: corazón:. ↩
Esta es una mentira. En realidad, uso aes(colour = after_scale(colorspace::darken(fill, 0.3))) en lugar de aligerar el relleno. Sin embargo, no quería que este readme dependa de {Colorspace}. ↩
A menos que se auto-sabotaje sus gráficos configurando oob = scales::oob_censor_any en la escala, por ejemplo. ↩
En tu alma de almas, ¿ realmente quieres hacer un montón de bolos? ↩
La alternativa es usar el pronombre .data , que puede ser .data$var si desea bloquear esa columna por adelantado, o .data[[var]] cuando var se pasa como carácter. ↩
Este bit se llamaba originalmente 'esqueleto parcial', pero como una caja torácica es parte de un esqueleto, este título sonaba más evocador. ↩


