whisper.cpp
v1.7.2
Estable: V1.7.2 / Hoja de ruta | Preguntas frecuentes
Inferencia de alto rendimiento del modelo de reconocimiento automático de voz de OpenAI's Whisper (ASR):
Plataformas compatibles:
Toda la implementación de alto nivel del modelo está contenida en Whisper.h y Whisper.cpp. El resto del código es parte de la biblioteca de aprendizaje automático ggml .
Tener una implementación tan ligera del modelo permite integrarlo fácilmente en diferentes plataformas y aplicaciones. Como ejemplo, aquí hay un video de ejecutar el modelo en un dispositivo iPhone 13: completamente fuera de línea, en el dispositivo: whisper.objc
También puede hacer fácilmente su propia aplicación de asistente de voz fuera de línea: comando
En Apple Silicon, la inferencia funciona completamente en la GPU a través del metal:
O incluso puedes ejecutarlo directamente en el navegador: hablar.wasm
Los operadores de tensor están optimizados en gran medida para las CPU de silicio de manzana. Dependiendo del tamaño de cálculo, se utilizan intrínsecos SIMD de neón del brazo o las rutinas de marco de aceleración de CBLAS. Estos últimos son especialmente efectivos para tamaños más grandes, ya que el marco de Acelerate utiliza el coprocesador AMX de uso especial disponible en productos modernos de Apple.
Primer clon el repositorio:
git clone https://github.com/ggerganov/whisper.cpp.gitNavegue al directorio:
cd whisper.cpp
Luego, descargue uno de los modelos Whisper convertidos en formato ggml . Por ejemplo:
sh ./models/download-ggml-model.sh base.enAhora cree el ejemplo principal y transcriba un archivo de audio como este:
# build the main example
make -j
# transcribe an audio file
./main -f samples/jfk.wav Para una demostración rápida, simplemente ejecute make base.en :
$ make -j base.en
cc -I. -O3 -std=c11 -pthread -DGGML_USE_ACCELERATE -c ggml.c -o ggml.o
c++ -I. -I./examples -O3 -std=c++11 -pthread -c whisper.cpp -o whisper.o
c++ -I. -I./examples -O3 -std=c++11 -pthread examples/main/main.cpp whisper.o ggml.o -o main -framework Accelerate
./main -h
usage: ./main [options] file0.wav file1.wav ...
options:
-h, --help [default] show this help message and exit
-t N, --threads N [4 ] number of threads to use during computation
-p N, --processors N [1 ] number of processors to use during computation
-ot N, --offset-t N [0 ] time offset in milliseconds
-on N, --offset-n N [0 ] segment index offset
-d N, --duration N [0 ] duration of audio to process in milliseconds
-mc N, --max-context N [-1 ] maximum number of text context tokens to store
-ml N, --max-len N [0 ] maximum segment length in characters
-sow, --split-on-word [false ] split on word rather than on token
-bo N, --best-of N [5 ] number of best candidates to keep
-bs N, --beam-size N [5 ] beam size for beam search
-wt N, --word-thold N [0.01 ] word timestamp probability threshold
-et N, --entropy-thold N [2.40 ] entropy threshold for decoder fail
-lpt N, --logprob-thold N [-1.00 ] log probability threshold for decoder fail
-debug, --debug-mode [false ] enable debug mode (eg. dump log_mel)
-tr, --translate [false ] translate from source language to english
-di, --diarize [false ] stereo audio diarization
-tdrz, --tinydiarize [false ] enable tinydiarize (requires a tdrz model)
-nf, --no-fallback [false ] do not use temperature fallback while decoding
-otxt, --output-txt [false ] output result in a text file
-ovtt, --output-vtt [false ] output result in a vtt file
-osrt, --output-srt [false ] output result in a srt file
-olrc, --output-lrc [false ] output result in a lrc file
-owts, --output-words [false ] output script for generating karaoke video
-fp, --font-path [/System/Library/Fonts/Supplemental/Courier New Bold.ttf] path to a monospace font for karaoke video
-ocsv, --output-csv [false ] output result in a CSV file
-oj, --output-json [false ] output result in a JSON file
-ojf, --output-json-full [false ] include more information in the JSON file
-of FNAME, --output-file FNAME [ ] output file path (without file extension)
-ps, --print-special [false ] print special tokens
-pc, --print-colors [false ] print colors
-pp, --print-progress [false ] print progress
-nt, --no-timestamps [false ] do not print timestamps
-l LANG, --language LANG [en ] spoken language ('auto' for auto-detect)
-dl, --detect-language [false ] exit after automatically detecting language
--prompt PROMPT [ ] initial prompt
-m FNAME, --model FNAME [models/ggml-base.en.bin] model path
-f FNAME, --file FNAME [ ] input WAV file path
-oved D, --ov-e-device DNAME [CPU ] the OpenVINO device used for encode inference
-ls, --log-score [false ] log best decoder scores of tokens
-ng, --no-gpu [false ] disable GPU
sh ./models/download-ggml-model.sh base.en
Downloading ggml model base.en ...
ggml-base.en.bin 100%[========================>] 141.11M 6.34MB/s in 24s
Done! Model 'base.en' saved in 'models/ggml-base.en.bin'
You can now use it like this:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
===============================================
Running base.en on all samples in ./samples ...
===============================================
----------------------------------------------
[+] Running base.en on samples/jfk.wav ... (run 'ffplay samples/jfk.wav' to listen)
----------------------------------------------
whisper_init_from_file: loading model from 'models/ggml-base.en.bin'
whisper_model_load: loading model
whisper_model_load: n_vocab = 51864
whisper_model_load: n_audio_ctx = 1500
whisper_model_load: n_audio_state = 512
whisper_model_load: n_audio_head = 8
whisper_model_load: n_audio_layer = 6
whisper_model_load: n_text_ctx = 448
whisper_model_load: n_text_state = 512
whisper_model_load: n_text_head = 8
whisper_model_load: n_text_layer = 6
whisper_model_load: n_mels = 80
whisper_model_load: f16 = 1
whisper_model_load: type = 2
whisper_model_load: mem required = 215.00 MB (+ 6.00 MB per decoder)
whisper_model_load: kv self size = 5.25 MB
whisper_model_load: kv cross size = 17.58 MB
whisper_model_load: adding 1607 extra tokens
whisper_model_load: model ctx = 140.60 MB
whisper_model_load: model size = 140.54 MB
system_info: n_threads = 4 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 |
main: processing 'samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:11.000] And so my fellow Americans, ask not what your country can do for you, ask what you can do for your country.
whisper_print_timings: fallbacks = 0 p / 0 h
whisper_print_timings: load time = 113.81 ms
whisper_print_timings: mel time = 15.40 ms
whisper_print_timings: sample time = 11.58 ms / 27 runs ( 0.43 ms per run)
whisper_print_timings: encode time = 266.60 ms / 1 runs ( 266.60 ms per run)
whisper_print_timings: decode time = 66.11 ms / 27 runs ( 2.45 ms per run)
whisper_print_timings: total time = 476.31 ms
El comando descarga el modelo base.en convertido en formato ggml personalizado y ejecuta la inferencia en todas las muestras .wav en las samples de carpeta.
Para instrucciones de uso detalladas, ejecute: ./main -h
Tenga en cuenta que el ejemplo principal actualmente se ejecuta solo con archivos WAV de 16 bits, así que asegúrese de convertir su entrada antes de ejecutar la herramienta. Por ejemplo, puede usar ffmpeg como este:
ffmpeg -i input.mp3 -ar 16000 -ac 1 -c:a pcm_s16le output.wavSi desea algunas muestras de audio adicionales para jugar, simplemente ejecute:
make -j samples
Esto descargará algunos archivos de audio más de Wikipedia y los convertirá en formato WAV de 16 bits a través de ffmpeg .
Puede descargar y ejecutar los otros modelos de la siguiente manera:
make -j tiny.en
make -j tiny
make -j base.en
make -j base
make -j small.en
make -j small
make -j medium.en
make -j medium
make -j large-v1
make -j large-v2
make -j large-v3
make -j large-v3-turbo
| Modelo | Disco | Memorando |
|---|---|---|
| diminuto | 75 MIB | ~ 273 MB |
| base | 142 MIB | ~ 388 MB |
| pequeño | 466 MIB | ~ 852 MB |
| medio | 1.5 GIB | ~ 2.1 GB |
| grande | 2.9 GIB | ~ 3.9 GB |
whisper.cpp admite cuantización entera de los modelos Whisper ggml . Los modelos cuantificados requieren menos memoria y espacio en disco y, dependiendo del hardware, se puede procesar de manera más eficiente.
Estos son los pasos para crear y usar un modelo cuantificado:
# quantize a model with Q5_0 method
make -j quantize
./quantize models/ggml-base.en.bin models/ggml-base.en-q5_0.bin q5_0
# run the examples as usual, specifying the quantized model file
./main -m models/ggml-base.en-q5_0.bin ./samples/gb0.wav En los dispositivos Apple Silicon, la inferencia del codificador se puede ejecutar en el motor neural de Apple (ANE) a través de Core ML. Esto puede dar lugar a una aceleración significativa, más de X3 más rápido en comparación con la ejecución de solo CPU. Estas son las instrucciones para generar un modelo ML central y usarlo con whisper.cpp :
Instale las dependencias de Python necesarias para la creación del modelo Core ML:
pip install ane_transformers
pip install openai-whisper
pip install coremltoolscoremltools funcione correctamente, confirme que Xcode está instalado y ejecute xcode-select --install para instalar las herramientas de línea de comandos.conda create -n py310-whisper python=3.10 -yconda activate py310-whisper Genere un modelo ML central. Por ejemplo, para generar un modelo base.en , use:
./models/generate-coreml-model.sh base.en Esto generará los models/ggml-base.en-encoder.mlmodelc
Build whisper.cpp con soporte de Core ML:
# using Makefile
make clean
WHISPER_COREML=1 make -j
# using CMake
cmake -B build -DWHISPER_COREML=1
cmake --build build -j --config ReleaseEjecute los ejemplos como de costumbre. Por ejemplo:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
...
whisper_init_state: loading Core ML model from 'models/ggml-base.en-encoder.mlmodelc'
whisper_init_state: first run on a device may take a while ...
whisper_init_state: Core ML model loaded
system_info: n_threads = 4 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 | COREML = 1 |
...
La primera ejecución en un dispositivo es lenta, ya que el servicio ANE compila el modelo Core ML en algún formato específico del dispositivo. Las siguientes carreras son más rápidas.
Para obtener más información sobre la implementación central de ML, consulte PR #566.
En las plataformas que admiten OpenVino, la inferencia del codificador se puede ejecutar en dispositivos respaldados por OpenVino, incluidas las CPU X86 e Intel GPU (integradas y discretas).
Esto puede dar lugar a una aceleración significativa en el rendimiento del codificador. Estas son las instrucciones para generar el modelo OpenVino y usarlo con whisper.cpp :
Primero, configure Python Virtual Env. e instalar dependencias de Python. Se recomienda Python 3.10.
Windows:
cd models
python - m venv openvino_conv_env
openvino_conv_envScriptsactivate
python - m pip install -- upgrade pip
pip install - r requirements - openvino.txtLinux y macOS:
cd models
python3 -m venv openvino_conv_env
source openvino_conv_env/bin/activate
python -m pip install --upgrade pip
pip install -r requirements-openvino.txt Genere un modelo de codificador OpenVino. Por ejemplo, para generar un modelo base.en , use:
python convert-whisper-to-openvino.py --model base.en
Esto producirá GGML-Base.en-Enner-Openvino.xml/.bin IR Modelo Archivos. Se recomienda reubicarlos en la misma carpeta que los modelos ggml , ya que esa es la ubicación predeterminada que la extensión de OpenVino buscará en tiempo de ejecución.
Build whisper.cpp con soporte de OpenVino:
Descargue el paquete OpenVino desde la página de lanzamiento. La versión recomendada para usar es 2023.0.0.
Después de descargar y extraer el paquete en su sistema de desarrollo, configure el entorno requerido obteniendo el script SetupVars. Por ejemplo:
Linux:
source /path/to/l_openvino_toolkit_ubuntu22_2023.0.0.10926.b4452d56304_x86_64/setupvars.shWindows (CMD):
C:PathTow_openvino_toolkit_windows_2023. 0.0 . 10926. b4452d56304_x86_64 setupvars.batY luego construya el proyecto usando CMake:
cmake -B build -DWHISPER_OPENVINO=1
cmake --build build -j --config ReleaseEjecute los ejemplos como de costumbre. Por ejemplo:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
...
whisper_ctx_init_openvino_encoder: loading OpenVINO model from 'models/ggml-base.en-encoder-openvino.xml'
whisper_ctx_init_openvino_encoder: first run on a device may take a while ...
whisper_openvino_init: path_model = models/ggml-base.en-encoder-openvino.xml, device = GPU, cache_dir = models/ggml-base.en-encoder-openvino-cache
whisper_ctx_init_openvino_encoder: OpenVINO model loaded
system_info: n_threads = 4 / 8 | AVX = 1 | AVX2 = 1 | AVX512 = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | VSX = 0 | COREML = 0 | OPENVINO = 1 |
...
La primera vez que se ejecuta en un dispositivo OpenVino es lento, ya que el marco OpenVino compilará el modelo IR (representación intermedia) en un 'blob' específico de dispositivo. Este blob específico del dispositivo se almacenará en caché para la próxima ejecución.
Para obtener más información sobre la implementación central de ML, consulte PR #1037.
Con las tarjetas NVIDIA, el procesamiento de los modelos se realiza de manera eficiente en la GPU a través de CUBLAS y los núcleos CUDA personalizados. Primero, asegúrese de haber instalado cuda : https://developer.nvidia.com/cuda-downloads
Ahora construya whisper.cpp con soporte CUDA:
make clean
GGML_CUDA=1 make -j
Solución de proveedores cruzados que le permite acelerar la carga de trabajo en su GPU. Primero, asegúrese de que el controlador de su tarjeta gráfica proporcione soporte para la API Vulkan.
Ahora construya whisper.cpp con Soporte de Vulkan:
make clean
make GGML_VULKAN=1 -j
El procesamiento del codificador se puede acelerar en la CPU a través de OpenBlas. Primero, asegúrese de haber instalado openblas : https://www.openblas.net/
Ahora construya whisper.cpp con soporte de abre -blas:
make clean
GGML_OPENBLAS=1 make -j
El procesamiento del codificador se puede acelerar en la CPU a través de la interfaz compatible con BLAS de la biblioteca de kernel matemática de Intel. Primero, asegúrese de haber instalado los paquetes de desarrollo y desarrollo de MKL de Intel: https://www.intel.com/content/www/us/en/developer/tools/oneapi/onemkl-dowload.html
Ahora construya whisper.cpp con Intel MKL BLAS Soporte:
source /opt/intel/oneapi/setvars.sh
mkdir build
cd build
cmake -DWHISPER_MKL=ON ..
WHISPER_MKL=1 make -j
ASCEND NPU proporciona aceleración de inferencia a través de núcleos CANN y Ai.
Primero, verifique si su dispositivo ASCEND NPU es compatible:
Dispositivos verificados
| Ascender npu | Estado |
|---|---|
| Atlas 300t A2 | Apoyo |
Luego, asegúrese de haber instalado CANN toolkit . Se recomienda la versión duradera de Cann.
Ahora construya whisper.cpp con soporte de cann:
mkdir build
cd build
cmake .. -D GGML_CANN=on
make -j
Ejecute los ejemplos de inferencia como de costumbre, por ejemplo:
./build/bin/main -f samples/jfk.wav -m models/ggml-base.en.bin -t 8
Notas:
Verified devices de la tabla. Tenemos dos imágenes de Docker disponibles para este proyecto:
ghcr.io/ggerganov/whisper.cpp:main : esta imagen incluye el archivo ejecutable principal, así como curl y ffmpeg . (Plataformas: linux/amd64 , linux/arm64 )ghcr.io/ggerganov/whisper.cpp:main-cuda : igual que main pero compilado con soporte CUDA. (Plataformas: linux/amd64 ) # download model and persist it in a local folder
docker run -it --rm
-v path/to/models:/models
whisper.cpp:main " ./models/download-ggml-model.sh base /models "
# transcribe an audio file
docker run -it --rm
-v path/to/models:/models
-v path/to/audios:/audios
whisper.cpp:main " ./main -m /models/ggml-base.bin -f /audios/jfk.wav "
# transcribe an audio file in samples folder
docker run -it --rm
-v path/to/models:/models
whisper.cpp:main " ./main -m /models/ggml-base.bin -f ./samples/jfk.wav " Puede instalar binarios preconstruidos para whisper.cpp o construirlo desde la fuente usando Conan. Use el siguiente comando:
conan install --requires="whisper-cpp/[*]" --build=missing
Para obtener instrucciones detalladas sobre cómo usar Conan, consulte la documentación de Conan.
Aquí hay otro ejemplo de transcribir un discurso de 3:24 minutos en aproximadamente medio minuto en un MacBook M1 Pro, usando Modelo medium.en :
$ ./main -m models/ggml-medium.en.bin -f samples/gb1.wav -t 8
whisper_init_from_file: loading model from 'models/ggml-medium.en.bin'
whisper_model_load: loading model
whisper_model_load: n_vocab = 51864
whisper_model_load: n_audio_ctx = 1500
whisper_model_load: n_audio_state = 1024
whisper_model_load: n_audio_head = 16
whisper_model_load: n_audio_layer = 24
whisper_model_load: n_text_ctx = 448
whisper_model_load: n_text_state = 1024
whisper_model_load: n_text_head = 16
whisper_model_load: n_text_layer = 24
whisper_model_load: n_mels = 80
whisper_model_load: f16 = 1
whisper_model_load: type = 4
whisper_model_load: mem required = 1720.00 MB (+ 43.00 MB per decoder)
whisper_model_load: kv self size = 42.00 MB
whisper_model_load: kv cross size = 140.62 MB
whisper_model_load: adding 1607 extra tokens
whisper_model_load: model ctx = 1462.35 MB
whisper_model_load: model size = 1462.12 MB
system_info: n_threads = 8 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 |
main: processing 'samples/gb1.wav' (3179750 samples, 198.7 sec), 8 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:08.000] My fellow Americans, this day has brought terrible news and great sadness to our country.
[00:00:08.000 --> 00:00:17.000] At nine o'clock this morning, Mission Control in Houston lost contact with our Space Shuttle Columbia.
[00:00:17.000 --> 00:00:23.000] A short time later, debris was seen falling from the skies above Texas.
[00:00:23.000 --> 00:00:29.000] The Columbia's lost. There are no survivors.
[00:00:29.000 --> 00:00:32.000] On board was a crew of seven.
[00:00:32.000 --> 00:00:39.000] Colonel Rick Husband, Lieutenant Colonel Michael Anderson, Commander Laurel Clark,
[00:00:39.000 --> 00:00:48.000] Captain David Brown, Commander William McCool, Dr. Kultna Shavla, and Ilan Ramon,
[00:00:48.000 --> 00:00:52.000] a colonel in the Israeli Air Force.
[00:00:52.000 --> 00:00:58.000] These men and women assumed great risk in the service to all humanity.
[00:00:58.000 --> 00:01:03.000] In an age when space flight has come to seem almost routine,
[00:01:03.000 --> 00:01:07.000] it is easy to overlook the dangers of travel by rocket
[00:01:07.000 --> 00:01:12.000] and the difficulties of navigating the fierce outer atmosphere of the Earth.
[00:01:12.000 --> 00:01:18.000] These astronauts knew the dangers, and they faced them willingly,
[00:01:18.000 --> 00:01:23.000] knowing they had a high and noble purpose in life.
[00:01:23.000 --> 00:01:31.000] Because of their courage and daring and idealism, we will miss them all the more.
[00:01:31.000 --> 00:01:36.000] All Americans today are thinking as well of the families of these men and women
[00:01:36.000 --> 00:01:40.000] who have been given this sudden shock and grief.
[00:01:40.000 --> 00:01:45.000] You're not alone. Our entire nation grieves with you,
[00:01:45.000 --> 00:01:52.000] and those you love will always have the respect and gratitude of this country.
[00:01:52.000 --> 00:01:56.000] The cause in which they died will continue.
[00:01:56.000 --> 00:02:04.000] Mankind is led into the darkness beyond our world by the inspiration of discovery
[00:02:04.000 --> 00:02:11.000] and the longing to understand. Our journey into space will go on.
[00:02:11.000 --> 00:02:16.000] In the skies today, we saw destruction and tragedy.
[00:02:16.000 --> 00:02:22.000] Yet farther than we can see, there is comfort and hope.
[00:02:22.000 --> 00:02:29.000] In the words of the prophet Isaiah, "Lift your eyes and look to the heavens
[00:02:29.000 --> 00:02:35.000] who created all these. He who brings out the starry hosts one by one
[00:02:35.000 --> 00:02:39.000] and calls them each by name."
[00:02:39.000 --> 00:02:46.000] Because of His great power and mighty strength, not one of them is missing.
[00:02:46.000 --> 00:02:55.000] The same Creator who names the stars also knows the names of the seven souls we mourn today.
[00:02:55.000 --> 00:03:01.000] The crew of the shuttle Columbia did not return safely to earth,
[00:03:01.000 --> 00:03:05.000] yet we can pray that all are safely home.
[00:03:05.000 --> 00:03:13.000] May God bless the grieving families, and may God continue to bless America.
[00:03:13.000 --> 00:03:19.000] [Silence]
whisper_print_timings: fallbacks = 1 p / 0 h
whisper_print_timings: load time = 569.03 ms
whisper_print_timings: mel time = 146.85 ms
whisper_print_timings: sample time = 238.66 ms / 553 runs ( 0.43 ms per run)
whisper_print_timings: encode time = 18665.10 ms / 9 runs ( 2073.90 ms per run)
whisper_print_timings: decode time = 13090.93 ms / 549 runs ( 23.85 ms per run)
whisper_print_timings: total time = 32733.52 ms
Este es un ejemplo ingenuo de realizar una inferencia en tiempo real en el audio desde su micrófono. La herramienta de transmisión muestra el audio cada medio segundo y ejecuta la transcripción continuamente. Hay más información disponible en el número 10.
make stream -j
./stream -m ./models/ggml-base.en.bin -t 8 --step 500 --length 5000 Agregar el argumento --print-colors imprimirá el texto transcrito utilizando una estrategia de codificación de color experimental para resaltar palabras con alta o baja confianza:
./main -m models/ggml-base.en.bin -f samples/gb0.wav --print-colors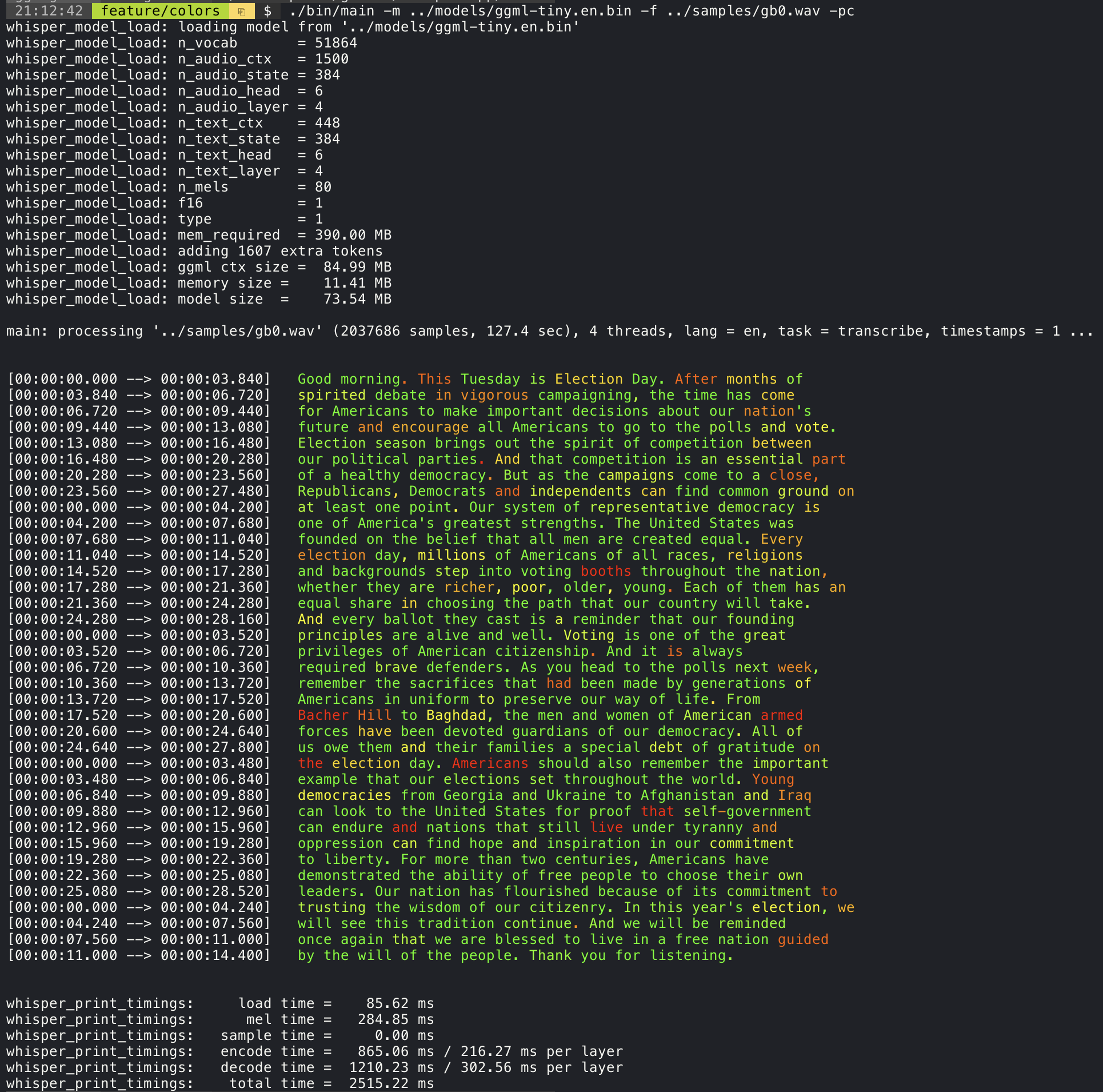
Por ejemplo, para limitar la longitud de la línea a un máximo de 16 caracteres, simplemente agregue -ml 16 :
$ ./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 16
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
system_info: n_threads = 4 / 10 | AVX2 = 0 | AVX512 = 0 | NEON = 1 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 |
main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:00.850] And so my
[00:00:00.850 --> 00:00:01.590] fellow
[00:00:01.590 --> 00:00:04.140] Americans, ask
[00:00:04.140 --> 00:00:05.660] not what your
[00:00:05.660 --> 00:00:06.840] country can do
[00:00:06.840 --> 00:00:08.430] for you, ask
[00:00:08.430 --> 00:00:09.440] what you can do
[00:00:09.440 --> 00:00:10.020] for your
[00:00:10.020 --> 00:00:11.000] country.
El argumento --max-len se puede usar para obtener marcas de tiempo a nivel de palabra. Simplemente use -ml 1 :
$ ./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 1
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
system_info: n_threads = 4 / 10 | AVX2 = 0 | AVX512 = 0 | NEON = 1 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 |
main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:00.320]
[00:00:00.320 --> 00:00:00.370] And
[00:00:00.370 --> 00:00:00.690] so
[00:00:00.690 --> 00:00:00.850] my
[00:00:00.850 --> 00:00:01.590] fellow
[00:00:01.590 --> 00:00:02.850] Americans
[00:00:02.850 --> 00:00:03.300] ,
[00:00:03.300 --> 00:00:04.140] ask
[00:00:04.140 --> 00:00:04.990] not
[00:00:04.990 --> 00:00:05.410] what
[00:00:05.410 --> 00:00:05.660] your
[00:00:05.660 --> 00:00:06.260] country
[00:00:06.260 --> 00:00:06.600] can
[00:00:06.600 --> 00:00:06.840] do
[00:00:06.840 --> 00:00:07.010] for
[00:00:07.010 --> 00:00:08.170] you
[00:00:08.170 --> 00:00:08.190] ,
[00:00:08.190 --> 00:00:08.430] ask
[00:00:08.430 --> 00:00:08.910] what
[00:00:08.910 --> 00:00:09.040] you
[00:00:09.040 --> 00:00:09.320] can
[00:00:09.320 --> 00:00:09.440] do
[00:00:09.440 --> 00:00:09.760] for
[00:00:09.760 --> 00:00:10.020] your
[00:00:10.020 --> 00:00:10.510] country
[00:00:10.510 --> 00:00:11.000] .
Más información sobre este enfoque está disponible aquí: #1058
Uso de la muestra:
# download a tinydiarize compatible model
. / models / download - ggml - model . sh small . en - tdrz
# run as usual, adding the "-tdrz" command-line argument
. / main - f . / samples / a13 . wav - m . / models / ggml - small . en - tdrz . bin - tdrz
...
main : processing './samples/a13.wav' ( 480000 samples , 30.0 sec ), 4 threads , 1 processors , lang = en , task = transcribe , tdrz = 1 , timestamps = 1 ...
...
[ 00 : 00 : 00.000 - - > 00 : 00 : 03.800 ] Okay Houston , we ' ve had a problem here . [ SPEAKER_TURN ]
[ 00 : 00 : 03.800 - - > 00 : 00 : 06.200 ] This is Houston . Say again please . [ SPEAKER_TURN ]
[ 00 : 00 : 06.200 - - > 00 : 00 : 08.260 ] Uh Houston we ' ve had a problem .
[ 00 : 00 : 08.260 - - > 00 : 00 : 11.320 ] We ' ve had a main beam up on a volt . [ SPEAKER_TURN ]
[ 00 : 00 : 11.320 - - > 00 : 00 : 13.820 ] Roger main beam interval . [ SPEAKER_TURN ]
[ 00 : 00 : 13.820 - - > 00 : 00 : 15.100 ] Uh uh [ SPEAKER_TURN ]
[ 00 : 00 : 15.100 - - > 00 : 00 : 18.020 ] So okay stand , by thirteen we ' re looking at it . [ SPEAKER_TURN ]
[ 00 : 00 : 18.020 - - > 00 : 00 : 25.740 ] Okay uh right now uh Houston the uh voltage is uh is looking good um .
[ 00 : 00 : 27.620 - - > 00 : 00 : 29.940 ] And we had a a pretty large bank or so . El ejemplo principal proporciona soporte para la producción de películas de estilo karaoke, donde se resalta la palabra pronunciada actualmente. Use el argumento -wts y ejecute el script bash generado. Esto requiere tener instalado ffmpeg .
Aquí hay algunos ejemplos "típicos" :
./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -owts
source ./samples/jfk.wav.wts
ffplay ./samples/jfk.wav.mp4./main -m ./models/ggml-base.en.bin -f ./samples/mm0.wav -owts
source ./samples/mm0.wav.wts
ffplay ./samples/mm0.wav.mp4./main -m ./models/ggml-base.en.bin -f ./samples/gb0.wav -owts
source ./samples/gb0.wav.wts
ffplay ./samples/gb0.wav.mp4Use el scripts/bench wts.sh script para generar un video en el siguiente formato:
./scripts/bench-wts.sh samples/jfk.wav
ffplay ./samples/jfk.wav.all.mp4Para tener una comparación objetiva del rendimiento de la inferencia en diferentes configuraciones del sistema, use la herramienta de banco. La herramienta simplemente ejecuta la parte del codificador del modelo e imprime cuánto tiempo tardó en ejecutarlo. Los resultados se resumen en el siguiente problema de GitHub:
Resultados de referencia
Además, se proporciona un script para ejecutar whisper.cpp con diferentes modelos y archivos de audio bench.py.
Puede ejecutarlo con el siguiente comando, de forma predeterminada se ejecutará en cualquier modelo estándar en la carpeta de modelos.
python3 scripts/bench.py -f samples/jfk.wav -t 2,4,8 -p 1,2Está escrito en Python con la intención de ser fácil de modificar y extender para su caso de uso de evaluación comparativa.
Emite un archivo CSV con los resultados de la evaluación comparativa.
ggmlLos modelos originales se convierten en un formato binario personalizado. Esto permite empacar todo lo necesario en un solo archivo:
Puede descargar los modelos convertidos utilizando el script modelos/descargar-ggml-model.sh o manualmente desde aquí:
Para obtener más detalles, consulte los modelos de script de conversión/convert-pt-to-ggml.py o modelos/readme.md.
Hay varios ejemplos de uso de la biblioteca para diferentes proyectos en la carpeta de ejemplos. Algunos de los ejemplos incluso están portados para ejecutarse en el navegador utilizando WebAssembly. ¡Míralos!
| Ejemplo | Web | Descripción |
|---|---|---|
| principal | Whisper.wasm | Herramienta para traducir y transcribir audio usando Whisper |
| banco | bench.wasm | Compare el rendimiento de Whisper on Your Machine |
| arroyo | transmisión.Wasm | Transcripción en tiempo real de captura de micrófono sin procesar |
| dominio | comando.wasm | Ejemplo básico de asistente de voz para recibir comandos de voz del micrófono |
| wchess | wchess.wasm | Ajedrez controlado por voz |
| hablar | hablar.wasm | Hablar con un bot-2 bot-2 |
| Talk-llama | Habla con un bot de Llama | |
| whisper.objc | Aplicación móvil de iOS usando Whisper.cpp | |
| whisper.swiftui | Aplicación swiftui iOS / macOS usando whisper.cpp | |
| Whisper.Android | Aplicación móvil de Android usando Whisper.cpp | |
| Whisper.nvim | Complemento de voz a texto para neovim | |
| generar- karaoke.sh | Script auxiliar para generar fácilmente un video de karaoke de captura de audio en bruto | |
| livestress.sh | Transcripción de audio en vivo | |
| yt-wsp.sh | Descargar + transcribir y/o traducir cualquier vod (original) | |
| servidor | Servidor de transcripción HTTP con API similar a OAI |
Si tiene algún tipo de retroalimentación sobre este proyecto, no dude en usar la sección de discusiones y abrir un nuevo tema. Puede usar el programa y decirle a la categoría que comparta sus propios proyectos que usan whisper.cpp . Si tiene una pregunta, asegúrese de verificar la discusión de preguntas (#126) frecuentes.


