Desde la aparición del modelo de lenguaje grande (LLM) representado por ChatGPT, debido a su asombrosa capacidad de inteligencia artificial universal (AGI) de propósito general, ha desencadenado una ola de investigación y aplicación en el campo del procesamiento del lenguaje natural. Especialmente después del pequeño código abierto de LLM a escala que puede ejecutarse con ChatGlm, LLAMA y otros jugadores civiles pueden ejecutar, hay muchos casos de aplicaciones mínimamente ajustadas o basadas en LLM basadas en LLM. ¡Este proyecto tiene como objetivo recopilar y ordenar modelos de código abierto, aplicaciones, conjuntos de datos y tutoriales relacionados con la LLM china.
Si este proyecto puede brindarle un poco de ayuda, por favor déjeme un poco ~
Al mismo tiempo, también puede contribuir a los modelos de código abierto impopulares, aplicaciones, conjuntos de datos, etc. de este proyecto. Proporcione nueva información de almacén, inicie PR y proporcione información relacionada, como enlaces de almacén, números de estrellas, perfiles, información y otra información relacionada de acuerdo con el formato de este proyecto.
Descripción general de los detalles del modelo base: descripción:
Base
Incluir un modelo
Tamaño del parámetro del modelo
Número de token de senderos
Capacitación máxima
Si comercializar
Chatglm
Chatglm/2/3/4 base y chat
6b
1T/1.4
2k/32k
Uso comercial
Llama
Llama/2/3 base y chat
7B/8B/13B/33B/70B
1T/2T
2k/4k
Parcialmente comercializado
Baichuan
Baichuan/2 base y chat
7b/13b
1.2t/1.4t
4K
Uso comercial
Qwen
Qwen/1.5/2/2.5 Base y Chat & VL
7B/14B/32B/72B/110B
2.2t/3t/18t
8k/32k
Uso comercial
Floración
Floración
1B/7B/176B-MT
1.5t
2k
Uso comercial
Águila
Aquila/2 base/chat
7b/34b
-
2k
Uso comercial
Internet
Internet
7B/20B
-
200K
Uso comercial
Mixtrac
Base y chat
8x7b
-
32k
Uso comercial
Yi
Base y chat
6B/9B/34B
3T
200K
Uso comercial
Veterano
Base y chat
1.3b/7b/33b/67b
-
4K
Uso comercial
Xverse
Base y chat
7B/13B/65B/A4.2B
2.6t/3.2t
8k/16k/256k
Uso comercial
Tabla de contenido
Tabla de contenido
1. Modelo
1.1 Modelo de texto LLM
1.2 modelo multifamiliar LLM
2. Aplicación
2.1 Filtrado en el campo vertical
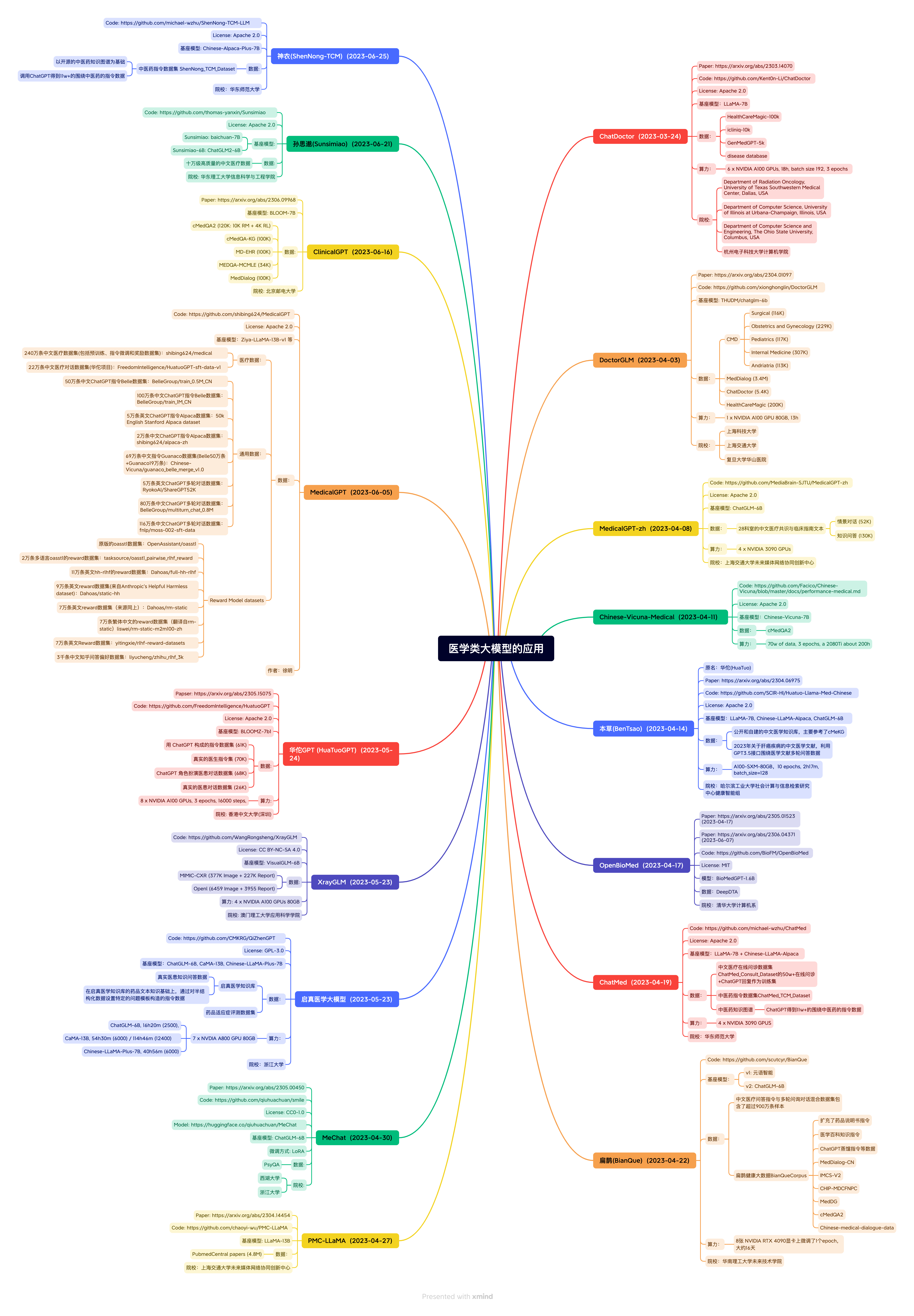
Atención médica
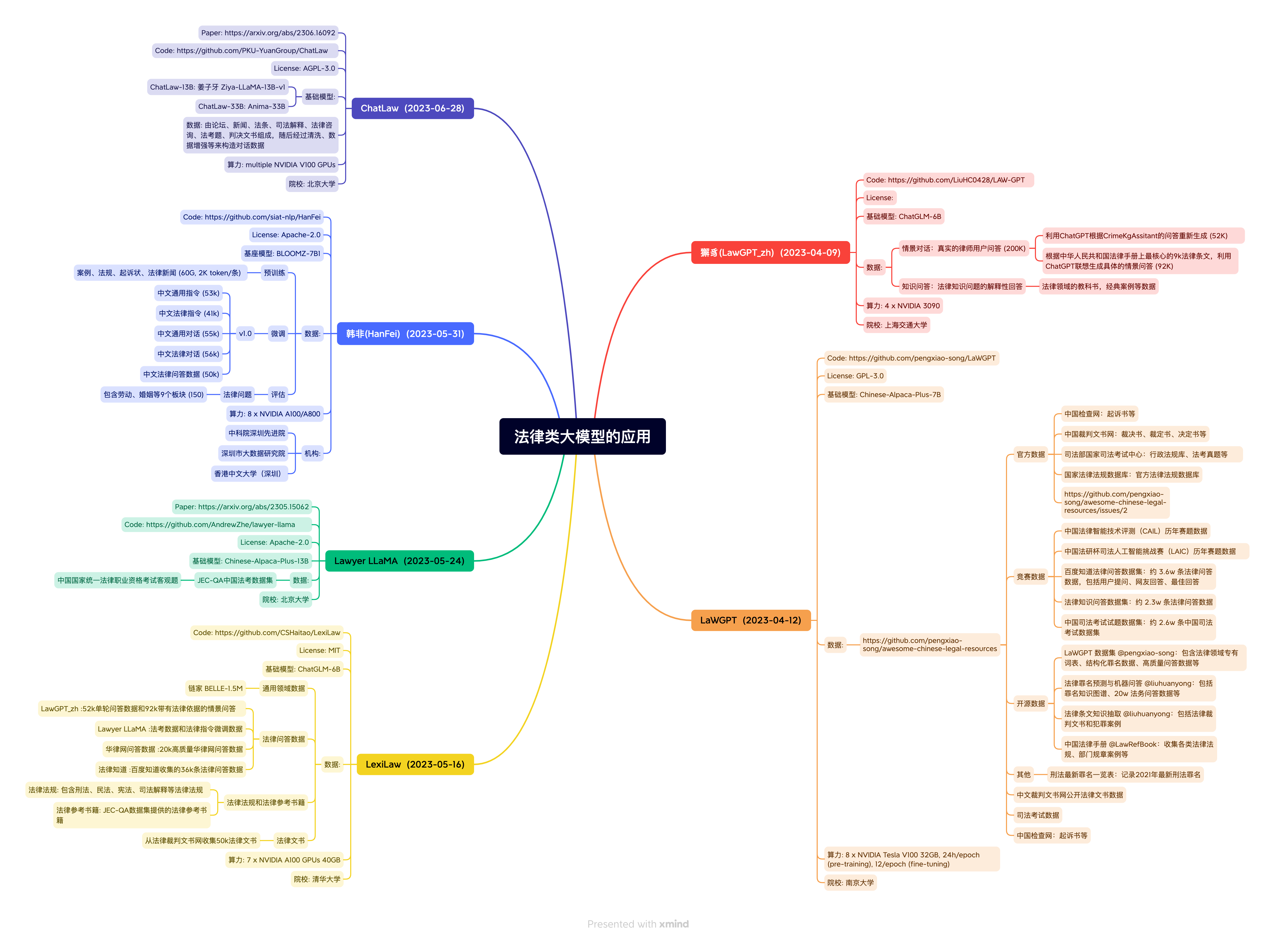
ley
finanzas
educar
ciencia y tecnología
E -commerce
Seguridad de la red
agricultura
2.2 Aplicación de Langchain
2.3 otras aplicaciones
3. Conjunto de datos
Conjunto de datos previo al entrenamiento
Conjunto de datos SFT
Conjunto de datos de preferencias
4. Entrenamiento de LLM Marco fino
5. Marco de implementación de razonamiento LLM
6. Evaluación de LLM
7. Tutorial de LLM
LLM conocimiento básico
Tutorial de ingeniería de solicitación
Tutorial de aplicaciones LLM
LLM Tutorial de combate real
8. Almacén relacionado
Historia de la estrella
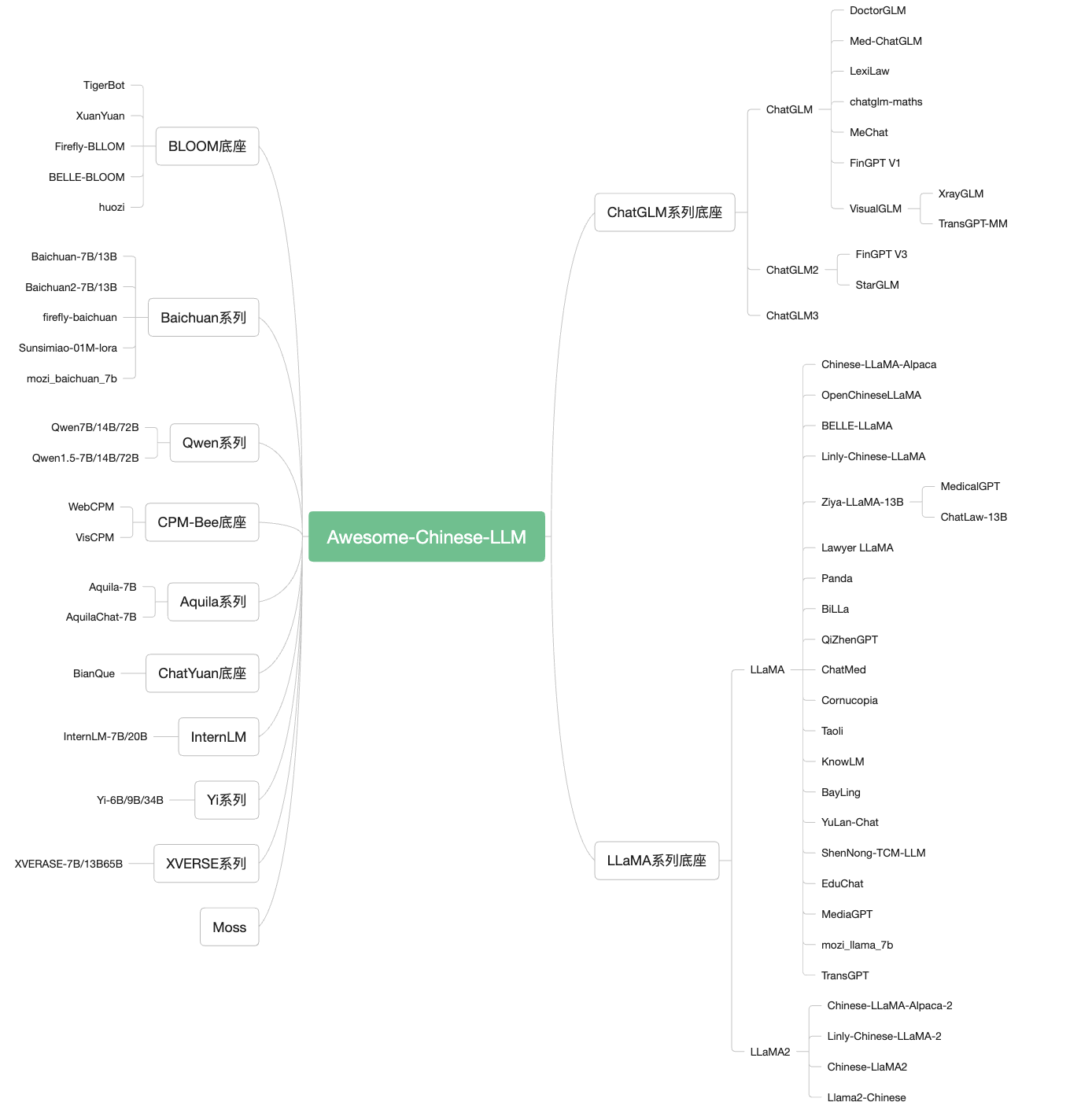
1. Modelo
1.1 Modelo de texto LLM
Chatglm:
Dirección: https://github.com/thudm/chatglm-6b
Introducción: uno de los modelos base de código abierto más efectivos en el campo chino, optimizó las preguntas y respuestas y el diálogo chino. Después de una capacitación bilingüe de aproximadamente 1T identificador, complementado por tecnologías como supervisar las finas, la retroalimentación y la retroalimentación de la retroalimentación humana para fortalecer el aprendizaje
Chatglm2-6b
Dirección: https://github.com/thudm/chatglm2-6b
INTRODUCCIÓN: Basado en la versión de segunda generación del modelo de diálogo de código abierto e inglés Chatglm-6b, ha introducido la función de objetivo híbrido de GLM sobre la base del diálogo del modelo preservado y los umbrales de bajo despliegue, que han sido retenidos. -Training de los símbolos de identificación británicos en la T y la alineación de las preferencias humanas; uso comercial.
Chatglm3-6b
Dirección: https://github.com/thudm/chatglm3
Introducción: ChatGlm3-6b es el modelo de código abierto en la serie ChatGlm3. : ChatGlm3- El modelo básico de 6b ChatGlm3-6b-base utiliza más datos de capacitación, más pasos de entrenamiento completos y estrategias de entrenamiento más razonables;同时原生支持工具调用( Llama de función )、代码执行( Código intérprete )和 Agente 任务等复杂场景;更全面的开源序列 : 除了对话模型 CHATGLM3-6B 外 , 还开源了基础模型 CHATGLM3-6B-BASE 、长文本Modelo de diálogo CHATGLM3-6B-32K. El peso anterior está completamente abierto a la investigación académica, y el uso comercial gratuito también se permite después de completar el cuestionario.
GLM-4
Dirección: https://github.com/thudm/glm-4
Breve introducción: GLM-4-9B es la versión de código abierto del modelo de pre-entrenamiento de última generación lanzado por Smart Spectrum AI. En la evaluación de conjuntos de datos como semántica, matemáticas, razonamiento, código y conocimiento, el GLM-4-9B y su versión de preferencia humana de GLM-4-9B-CHAT muestran un excelente rendimiento más allá de la esencia de Llama-3-8B Además de múltiples rondas de diálogo, GLM-4-9B-CHAT también tiene funciones avanzadas como navegación web, ejecución de código, llamadas de herramientas personalizadas (llamada de función) y razonamiento de texto largo (soporte para el máximo contexto de 128k). Esta generación ha agregado soporte de lenguaje múltiple, que respalda 26 idiomas, incluidos japonés, coreano y alemán. También lanzamos modelos GLM-4-9B-CHAT-1M que admiten una longitud contextual de 1M (aproximadamente 2 millones de caracteres chinos) y modelo multimodo GLM-4V-9B basado en GLM-4-9B. GLM-4V-9B tiene una capacidad multilingüe de diálogo multilingüe multilingüe bajo la alta resolución de 1120 * 1120. En muchos aspectos de la evaluación multimodal, como la capacidad integral integral e inglés, el razonamiento de la percepción, el reconocimiento de texto, la comprensión del cuadro, GLM-4V -9b expresa el excelente rendimiento de superar GPT-4-TURBO-2024-04-09, Gemini 1.0 Pro, Qwen-VL-Max y Claude 3 Opus.
QWEN/QWEN1.5/QWEN2/QWEN2.5
Dirección: https://github.com/qwenlm
Introducción: Tongyi Qianwen es una serie de modelos de modelo de Tongyi Qianwen desarrollado por Alibaba Cloud, incluida la escala de parámetros de 1.8 mil millones (1.8b), 7 mil millones (7b), 14 mil millones (14b), 72 mil millones (72b), 1100 y 1100 y 1100 100 millones (110b). Los modelos de cada escala incluyen el modelo básico QWEN y el modelo de diálogo. Los conjuntos de datos incluyen una variedad de tipos de datos como texto y código. Llame efectivamente al complemento y actualice a la esencia del agente
INTRODUCCIÓN: Shangtang Technology, Shanghai AI Laboratory y la Universidad China de Hong Kong, la Universidad de Fudan y la Universidad de Shanghai Jiaotong publicaron la "beca" del modelo de idioma grande de parámetros de 100 mil millones de niveles. Se informa que "Scholar PU" tiene 104 mil millones de parámetros, y está entrenado en función del "conjunto de datos de alta calidad múltiples de lenguaje que contiene 1.6 billones de token".
Internet
Dirección: https://github.com/internlm/internlm
Introducción: Shangtang Technology, Shanghai AI Laboratory y la Universidad China de Hong Kong, la Universidad de Fudan y la Universidad de Shanghai Jiaotong lanzaron el modelo de idioma grande de parámetros de 100 mil millones de niveles "Internlm2". Internlm2 ha logrado un gran progreso en digital, código, diálogo y creación, y el rendimiento integral ha alcanzado el nivel principal del modelo de código abierto. Internlm2 contiene dos modelos: 7b y 20b. 7b proporciona un modelo liviano pero único para la investigación y la aplicación de peso ligero.
Introducción: un modelo de lenguaje previo a gran escala desarrollado por el desarrollo inteligente de Baichuan. Basado en la estructura del transformador, el modelo de parámetros de 7 mil millones entrenado en aproximadamente 1.2 billones de tokens admite bilingüe chino e inglés, y la longitud de la ventana de contexto es 4096. Tanto el punto de referencia estándar de la autoridad china como el inglés (C-EVAL/MMLU) tienen el mejor efecto del mismo tamaño.
Introducción: Baichuan-13b es un modelo de lenguaje a gran escala que contiene 13 mil millones de parámetros después de Baichuan-7b después de Baichuan-7b. El proyecto publica dos versiones: Baichuan-13b-Base y Baichuan-13b-Chat.
Introducción: La nueva generación de modelo de lenguaje de código abierto lanzado por Baichuan Intelligence utiliza 2.6 billones de tokens para entrenar con una base publicada de alta calidad. .
Introducción: El modelo de lenguaje grande respaldado por la tecnología Shenzhen Yuanxiang admite modelos de lenguaje múltiple, admite la longitud de contexto de 8K y utiliza una alta calidad y datos diversificados de 2.6 billones de token para entrenar el modelo. Rusia y Western. También incluye modelos de versiones cuantitativas de Gguf y GPTQ, que admite razonamiento en LLAMA.CPP y VLLM en el sistema MacOS/Linux/Windows.
Introducción: Modelos de lenguaje grande respaldados por la tecnología Shenzhen Yuanxiang que admite modelos de lenguaje múltiple, que admiten la longitud de contexto de 8k (longitud de contexto) y utilizando datos de alta calidad y diversificados de 3.2 billones de tokens para capacitar completamente el modelo. como Gran Bretaña, Rusia y Western. Incluyendo el modelo de diálogo de secuencia larga Xverse-13B-256K. También incluye modelos de versiones cuantitativas de Gguf y GPTQ, que admite razonamiento en LLAMA.CPP y VLLM en el sistema MacOS/Linux/Windows.
Introducción: un modelo de lenguaje grande respaldado por la tecnología Shenzhen Yuanxiang admite un modelo de lenguaje múltiple, admite la longitud de contexto de 16k y utiliza datos de alta calidad y diversificados de 2.6 billones de tokens para entrenar el modelo para entrenar completamente el modelo. Idiomas como Gran Bretaña, Rusia y Western. Incluyendo un modelo incremental previo al entrenamiento Xverse-65B-2 con un pre-entrenamiento incremental. También incluye modelos de versiones cuantitativas de Gguf y GPTQ, que admite razonamiento en LLAMA.CPP y VLLM en el sistema MacOS/Linux/Windows.
INTRODUCCIÓN: Modelo de lenguaje grande, que admite el lenguaje múltiple desarrollado independientemente por la tecnología Shenzhen Yuanxiang. Apoye más de 40 idiomas como China, Gran Bretaña, Rusia y Western.
Trabajo de cielo
Dirección: https://github.com/skyworkai/skywork
Introducción: El proyecto está abierto a los modelos de la serie Tiangong. Modelo específico SkyWork-13B-Base, modelo SkyWork-13B-Chat, modelo SkyWork-13B-Math, SkyWork-13B-MM y modelos de versión cuantitativos de cada modelo para admitir que los usuarios implementan y razonan en la implementación de la tarjeta de gráficos de consumo y la implementación de la tarjeta gráfica esencia de razonamiento
Yi
Dirección: https://github.com/01- AI/YI
Breve introducción: este proyecto está abierto a modelos como YI-6B y YI-34B. Documentos con más de 1000 páginas.
Introducción: El proyecto se basa en el LLAMA-2 para el segundo desarrollo; -Tune múltiples rondas para adaptarse a diversos escenarios de aplicación e interacciones de diálogo de ronda múltiple. Al mismo tiempo, también consideramos una solución de adaptación china más rápida: chino-llama2-sft-v0: use instrucciones chinas de código abierto existentes, ajuste o datos de diálogo para ajustar directamente a LLAMA-2 (recientemente será de código abierto).
Introducción: Basado en Llama-7B, una gran base de modelos de idiomas generada por el entrenamiento previo al conjunto de datos chino, en comparación con el LLAMA original, este modelo ha mejorado mucho en términos de comprensión china y capacidad de generación. .
Beldad:
Dirección: https://github.com/lianjiaatech/belle
Introducción: código abierto para una serie de modelos basados en la optimización de Bloomz y Llama. Algoritmos de entrenamiento en el rendimiento del modelo.
Introducción: El código abierto se basa en Llama -7B, -13b, -33b, -65b para modelos de lenguaje previo continuo en el campo chino, y utiliza datos de casi 15 m para pre -entrenamiento secundario.
Robin (Robin):
Dirección: https://github.com/optimalscale/lmflow
Breve introducción: Robin (Robin) es un modelo bilingüe chino en inglés desarrollado por el equipo LMFlow de la Universidad de Ciencia y Tecnología de China. Solo el modelo de segunda generación de Robin obtenido por solo 180k datos de datos fue ajustado fino, alcanzando el primer lugar en la lista de Huggingface. LMFlow admite a los usuarios para capacitar rápidamente modelos personalizados.
INTRODUCCIÓN: Fengshenbang-LM (Big Model of God) es un sistema de código abierto de gran modelo dominado por el Instituto de Investigación de Idea Centro de Investigación Cognitiva y Investigación del Lenguaje Natural. , redacción, cuestionario de sentido común y computación matemática. Además de los modelos de la serie Jiangziya, el proyecto también está abierto a modelos como la serie Taiyi y Erlang God.
Billa:
Dirección: https://github.com/neutralzz/billa
Breve introducción: El proyecto es código abierto del modelo de LLAMA bilingüe de China en inglés con capacidades de razonamiento mejoradas. Las características principales del modelo son: mejorar enormemente la capacidad de comprensión china de la llama y minimizar el daño a la capacidad inglesa de la llama original tanto como sea posible; La tarea de comprensión del modelo para resolver la lógica de la tarea;
MUSGO:
Dirección: https://github.com/openlmlab/moss
INTRODUCCIÓN: Apoya el modelo de lenguaje de diálogo de código abierto de los complementos bilingües y múltiples de inglés. Entrenamiento de preferencias, tiene las instrucciones de diálogo, el aprendizaje de plug -in y el entrenamiento de preferencias humanas.
Introducción: Incluye una serie de proyectos de código abierto de grandes modelos de idioma chino, que contiene una serie de modelos de idiomas basados en los modelos de código abierto existentes (MOSS, LLAMA), instrucciones para conjuntos de datos finosos.
Linealmente:
Dirección: https://github.com/cvi-szu/linly
Introducción: Proporcione el modelo de diálogo chino Linly-Chatflow, el modelo básico chino Linly-Chinese-Llama y sus datos de capacitación. El modelo básico chino se basa en la llama, utilizando entrenamiento incremental paralelo chino y chino y británico. El proyecto resume los datos actuales de instrucciones de varios idiomas, lleva a cabo instrucciones a gran escala para seguir el modelo chino para seguir la capacitación y realizar el modelo de diálogo de flujo de chat.
INTRODUCCIÓN: Firefly es un proyecto de modelo de idioma chino grande. Como Baichuan Baichuan, Ziya, Bloom, Llama, etc. Sosteniendo Lora y el modelo base para fusionar peso, lo cual es más conveniente para razonar.
Chatyuan
Dirección: https://github.com/clue- AI/Chatyuan
Introducción: una serie de modelos de lenguaje de diálogo funcional respaldados por Yuanyu Intelligent, que admite el diálogo bilingüe bilingüe benéfico, optimizado en datos de fino y fino, aprendizaje mejorado por retroalimentación, cadena de pensamiento, etc.
Chatrwkv:
Dirección: https://github.com/blinkdl/chatrwkv
Introducción: código abierto Una serie de modelos de chat (incluidos inglés y chino) basado en la arquitectura de RWKV, modelos publicados que incluyen Raven, Novel-Chneng, novela y novela-chneng-chnpro, pueden chatear directamente y tocar poesía, novelas y otros Creaciones.
Abeja cpm
Dirección: https://github.com/openbmbmbmb/cpm-bee
Breve introducción: un código abierto completo, uso comercial permitido de 10 mil millones de parámetros modelos base chinos e ingleses. Adopta la arquitectura de auto-regresión de Transformer para llevar a cabo la capacitación previa en el corpus de alta calidad en billones, y tiene fuertes capacidades básicas. Los desarrolladores e investigadores pueden adaptarse a varios escenarios sobre la base del modelo base CPM-Bee para crear modelos de aplicación en campos específicos.
Introducción: un modelo de lenguaje a gran escala (LLM) con una forma múltiple y una tarea múltiple (LLM), el código abierto incluye modelos: Tigerbot-7b, Tigerbot-7B-Base, TigerBot-180b, Código básico de capacitación y razonamiento, 100G Datos previos al entrenamiento, que cubren las finanzas y el derecho en el campo de la enciclopedia y la API.
Introducción: Publicado por el Instituto de Investigación Zhiyuan, el modelo de lenguaje Aquila heredó las ventajas de diseño arquitectónico de GPT-3, Llama, etc., reemplazó a un grupo de operadores subyacentes más eficientes para lograr, rediseñó el tokenizador bilingüe chino e inglés, actualizó el Bmtrain Parallels Método de entrenamiento, comenzó a partir de 0 sobre la base del corpus de alta calidad chino e inglés. También es el primer modelo de lenguaje de código abierto a gran escala que respalda el conocimiento bilingüe bilingüe chino, apoya el acuerdo de licencia comercial y satisface las necesidades del cumplimiento de los datos nacionales.
Aquila2
Dirección: https://github.com/flagai-open/aquila2
Introducción: Publicado por el Instituto de Investigación Zhiyuan, Serie Aquila2, incluido el modelo de lenguaje básico Aquila2-7b, Aquila2-34b y Aquila2-70b-EXPR, modelo de diálogo Aquilachat2-7b, Aquilachat2-34b y Aquilachat2-70b-Expr, texto largo de texto Aquilachat2 -7b-16k y Aquilachat2-34b-16.
Anima
Dirección: https://github.com/lyogavin/anima
INTRODUCCIÓN: Un código abierto del modelo de idioma chino 33B basado en Qlora desarrollado por la tecnología AI Ten. Basado en la evaluación del torneo de calificación ELO es mejor.
Conocimientos
Dirección: https://github.com/zjunlp/knowlm
Introducción: El proyecto Knowlm tiene como objetivo publicar el marco de los modelos grandes de código abierto y los pesos del modelo correspondientes para ayudar a reducir el problema de la falacia del conocimiento, incluida la dificultad del conocimiento de grandes modelos y posibles errores y prejuicios. La primera fase del proyecto lanzó la extracción basada en LLAMA del análisis de inteligencia de grandes modelos, utilizando el cuerpo chino e inglés para capacitar completamente a LLAMA (13B), y optimiza las tareas de extracción de conocimiento basadas en la tecnología de instrucción de conversión de gráficos de conocimiento.
Bayling
Dirección: https://github.com/ictnlp/bayling
Introduction: A large -scale universal model with enhanced cross -language alignment was developed by the Natural Language Treatment Team of the Institute of Computing Technology of the Chinese Academy of Sciences. Bayling utiliza el Llama como modelo base, explorando el método de las instrucciones de fina con las tareas de traducción interactiva como el núcleo. . En la evaluación de la traducción de lenguaje múltiple, la traducción interactiva, las tareas universales y los exámenes estandarizados, Bai Ling mostró un mejor rendimiento en chino/inglés. Bai Ling proporciona una versión en línea de la demostración para que todos los experimenten.
Introducción: Yulan-Chat es un gran modelo de lenguaje desarrollado por investigadores de Gsai de la Universidad Renmin de China. Se desarrolla fino en la base de LLAMA y tiene instrucciones de alta calidad en inglés y chino. Yulan-Chat puede chatear con los usuarios, seguir bien las instrucciones inglesas o chinas, y puede implementarse en la GPU (A800-80G o RTX3090) después de la cuantificación.
Polilm
Dirección: https://github.com/damo-nlp-mt/polylm
Breve introducción: un modelo de lenguaje múltiple entrenado desde el comienzo de 640 mil millones de palabras, incluido el tamaño de dos modelos (1.7b y 13b). Polylm cubre China, Gran Bretaña, Rusia, Oeste, Francia, Portugués, Alemania, Italia, He, Bo, Bobo, Ashi, Hebreos, Japón, Corea del Sur, Tailandia, Vietnam, Indonesia y otros tipos, especialmente más amigable con el idioma asiático.
huozi
Dirección: https://github.com/hit-scir/huozi
Introducción: un modelo de lenguaje previo a gran escala a gran escala de un modelo de lenguaje pre -entrenamiento de gran escala desarrollado por el Instituto Harbin del Instituto de Investigación de Tratamiento del Lenguaje de la Naturaleza. Este modelo se basa en el modelo de parámetros de 7 mil millones de la estructura de Bloom, que admite el bilingüe chino e inglés. conjunto de datos.
Introducción: El modelo elegante está fino en los datos de campo de alta calidad del campo de alta calidad de millones de estructuras artificiales. y gobernanza urbana. A partir de la iteración de la inicialización previa al entrenamiento del pre -entrenamiento, mejoramos gradualmente sus capacidades básicas de capacidad china y análisis de campo, y aumentamos múltiples rondas de diálogo y algunas capacidades de enchufe en. Al mismo tiempo, después de cientos de pruebas internas de los usuarios, la optimización continua de retroalimentación artificial se ha mejorado continuamente, lo que mejora aún más el rendimiento y la seguridad del modelo. El modelo de código abierto de optimización china basado en Llama 2, explora las últimas prácticas adecuadas para misiones chinas en muchos campos de los chinos.
Introducción: Yayi 2 es una nueva generación de modelos de lenguaje grande de código abierto desarrollados por Zhongke Wenge, incluidas versiones base y de chat con una escala de parámetros de 30B. YAYI2-30B es un modelo de lenguaje grande basado en transformador, utilizando corpus de alta calidad y varios idiomas de más de 2 billones de tokens para la capacitación previa. En respuesta a los escenarios de aplicación en áreas generales y específicas, hemos utilizado millones de instrucciones para abordar, y al mismo tiempo, utilizamos la retroalimentación humana para fortalecer los métodos de aprendizaje para alinear mejor el modelo y los valores humanos. Este modelo de código abierto es el modelo base YAYI2-30B.
Yuan-2.0
Dirección: https://github.com/ieit-yuan/yuan-2.0
Introducción: El proyecto está abierto a una nueva generación de modelo de lenguaje básico publicado por Inspur Information. Y proporcione scripts relevantes para servicios previos, fina y de razonamiento. La fuente 2.0 se basa en la fuente 1.0, utilizando datos previos previos a la capacitación de alta calidad y conjuntos de datos de fina para hacer que el modelo tenga una mayor comprensión en la semántica, las matemáticas, el razonamiento, el código y el conocimiento.
Introducción: El proyecto lleva a cabo tablas de expansión china previa en el modelo de expertos híbridos SPARSE mixtral-8x7b. La eficiencia de codificación china de este modelo mejora significativamente que el modelo original. Al mismo tiempo, a través del pre -entrenamiento incremental en el corpus de código abierto a gran escala, este modelo tiene una fuerte capacidad de generación china y comprensión.
Holicero
Dirección: https: //github.com/vivo-jlab/bluelm
Introducción: Bluelm es un modelo de lenguaje previo a la escala de gran escala desarrollado independientemente por el Instituto de Investigación Global Vivo AI. (CHAT) Modelo.
INTRODUCCIÓN: Orionstar-Yi-34b-Chat es el modelo YI-34B con sede en el cielo de Hangry basado en el código abierto de 10,000 cosas. Experiencias interactivas para grandes usuarios de la comunidad modelo.
Minicpm
Agregar
Introducción: MinicPM es una serie de modelos de lado lateral comúnmente abierto por la inteligencia de la pared de fideos y el laboratorio de tratamiento de lenguaje natural de la Universidad de Tsinghua. de parámetros.
Mengzi3
Dirección: https://github.com/langboat/mengzi3
Introducción: el modelo Mengzi3 8B/13B se basa en la arquitectura de LLAMA, con la selección del corpus de páginas web, Enciclopedia, Social, Medios, Noticias y Conjuntos de datos de código abierto de alta calidad. Al continuar la capacitación en el corpus de lenguaje múltiple en billones de tokens, la capacidad china del modelo es sobresaliente y tiene en cuenta la capacidad de lenguaje múltiple.
1.2 modelo multifamiliar LLM
Visualglm-6b
Dirección: https://github.com/thudm/visualglm-6b
INTRODUCCIÓN: un modelo de lenguaje de diálogo de modo múltiple, el modelo de lingüístico de modo múltiple, chino e inglés. Confiando en el par gráfico chino de alta calidad de alta calidad del conjunto de datos COGVIEW, pre -entrenamiento con el gráfico en inglés proyectado con 300 m.
Cogvlm
Dirección: https://github.com/thudm/cogvlm
Breve introducción: un poderoso modelo de lenguaje visual de código abierto (VLM). COGVLM-17B tiene 10 mil millones de parámetros visuales y 7 mil millones de parámetros de lenguaje. COGVLM-17B ha alcanzado el rendimiento de SOTA en 10 pruebas de referencia intermodulares clásicas. COGVLM puede describir con precisión las imágenes, y casi no aparecen alucinaciones.
Introducción: modelos chinos de modo múltiple desarrollados basados en el proyecto de modelo chino y modelo de Alpaca. VisualCla agrega módulos de codificación de imagen al modelo chino de Llama/Alpaca, para que el modelo de LLAMA pueda recibir información visual. Sobre esta base, se usó el gráfico chino para el pre -entrenamiento multimodal en los datos. Las instrucciones de modo se abre actualmente VisualCla-7B-V0.1.
Llasm
Dirección: https://github.com/linksoul- ai/llasm
Breve introducción: el primer modelo de diálogo de código abierto y de diálogo comercial que admite el diálogo multimodal de texto dual de doble voz china e inglesa. La conveniente entrada de voz mejorará en gran medida la experiencia del modelo grande con el texto como la entrada, al tiempo que evita los procesos tediosos basados en soluciones ASR y posibles errores que se pueden introducir. Actualmente Open Source LLASM-Chinese-Llama-2-7B, LLASM-BAICHUAN-7B y otros modelos y conjuntos de datos.
Viscpm
Agregar
Introducción: una serie de modelos múltiples de código abierto y modelos grandes, admite el diálogo multimodo bilingüe chino e inglés (modelos VISCPM-Chat) y las capacidades de generación de texto a gráficos (modelo VISCPM-Pint). VISCPM se basa en decenas de miles de millones de parámetros, un modelo de lenguaje a gran escala CPM-BEE (10B) e integra el codificador visual (Q-former) y el decodificador visual (unión de difusión) para soportar la entrada y salida de la señal visual.得益于CPM-Bee基座优秀的双语能力,VisCPM可以仅通过英文多模态数据预训练,泛化实现优秀的中文多模态能力。
Introduction: The project is open to the field of Chinese long text instructions with a multi-scale psychological counseling field with a multi-round dialogue data combined instruction to fine-tune the psychological health model (Soulchat). Fully tune the full number of parameters .
Introduction: WingPT is a large model based on the GPT-based medical vertical field. Based on the Qwen-7B1 as the basic pre-training model, it has continued pre-training in this technology, instructions fine-tuning. -7B-Chat modelo.
简介:LazyLLM是一款低代码构建多Agent大模型应用的开发工具,协助开发者用极低的成本构建复杂的AI应用,并可以持续的迭代优化效果。 Lazyllm provides a more flexible application function customization method, and realizes a set of lightweight network management mechanisms to support one -click multi -Agent application, support streaming output, compatible with multiple IaaS platforms, and support the model in the application model Continue fine - sintonización.
MemFree
地址:https://github.com/memfreeme/memfree
简介:MemFree 是一个开源的Hybrid AI 搜索引擎,可以同时对您的个人知识库(如书签、笔记、文档等)和互联网进行搜索, 为你提供最佳答案。MemFree 支持自托管的极速无服务器向量数据库,支持自托管的极速Local Embedding and Rerank Service,支持一键部署。
Data set description: The scholar · Wanjuan 1.0 is the first open source version of the scholar · Wanjuan multi -modal language library, including three parts: text data set, graphic data set, and video data set. The total amount of data exceeds 2TB . 目前,书生·万卷1.0已被应用于书生·多模态、书生·浦语的训练。通过对高质量语料的“消化”,书生系列模型在语义理解、知识问答、视觉理解、视觉问答等各类生成式任务表现出的优异性能。
Data set description: Unified rich IFT data (such as COT data, still expands continuously), multiple training efficiency methods (such as Lora, P-Tuning), and multiple LLMS, three interfaces on three levels to create convenient researchers LLM-IFT research plataforma.
Data set description: Data sets are renovated with the true psychological mutual assistance QA for multiple rounds of psychological health support through ChatGPT. Dialogue themes, vocabulary and chapters are more rich and diverse, and are more in line with the application scenarios of multi -round diálogo.
偏好数据集
CValues
地址:https://github.com/X-PLUG/CValues
数据集说明:该项目开源了数据规模为145k的价值对齐数据集,该数据集对于每个prompt包括了拒绝&正向建议(safe and reponsibility) > 拒绝为主(safe) > 风险回复(unsafe)三种类型,可用于增强SFT模型的安全性或用于训练reward模型。
简介:一个中文版的大模型入门教程,围绕吴恩达老师的大模型系列课程展开,主要包括:吴恩达《ChatGPT Prompt Engineering for Developers》课程中文版,吴恩达《Building Systems with the ChatGPT API》课程中文版,吴恩达《LangChain for LLM Application Development》课程中文版等。
Introduction: ChatGPT burst into fire, which has opened a key step leading to AGI. This project aims to summarize the open source calories of those ChatGPTs, including large text models, multi -mode and large models, etc., providing some convenience for everyone .
Introduction: This Repo aims at recording Open Source Chatgpt, and Providing An Overview of How to get involved, Including: Base Models, TechNologies, DOMAIN MODELS , Training Pipelines, Speed Up Techniques, Multi-Language, Multi-Modal, and more Ir.
简介:This repo record a list of totally open alternatives to ChatGPT.
Awesome-LLM:
地址:https://github.com/Hannibal046/Awesome-LLM
简介:This repo is a curated list of papers about large language models, especially relating to ChatGPT. It also contains frameworks for LLM training, tools to deploy LLM, courses and tutorials about LLM and all publicly available LLM checkpoints and APIs.