GroundingDINO
Grounding DINO SwinB

Idea-CVR, investigación de idea
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang ? .
[ Paper ] [ Demo ] [ BibTex ]
Implementación de Pytorch y modelos previos a la creación de Dino. Para obtener más detalles, consulte el papel de la base Dino: casarse con dinosauría con pre-entrenamiento conectado a tierra para la detección de objetos abiertos .
2023/07/18 : Lanzamos Semantic-Sam, un modelo de segmentación de imágenes universal para habilitar el segmento y reconocer cualquier cosa en cualquier granularidad deseada. ¡El código y el punto de control están disponibles!2023/06/17 : Proporcionamos un ejemplo para evaluar a la base de Dino en el rendimiento de Coco Zero-Shot.2023/04/15 : ¡Consulte CV en las lecturas salvajes para aquellos que estén interesados en el reconocimiento de set abierto!2023/04/08 : Lanzamos demostraciones para combinar Dino de conexión a tierra con Gligen para ediciones de imágenes más controlables.2023/04/08 : Lanzamos demostraciones para combinar Dino de conexión a tierra con difusión estable para ediciones de imágenes.2023/04/06 : Construimos una nueva demostración casando a Groundingdino con el segmento llamado Segment-Segment-Anything tiene como objetivo apoyar la segmentación en Groundingdino.2023/03/28 : un video de YouTube sobre la tierra de la ingeniería de la indemnización de detección de objetos básico. [Skalskip]2023/03/28 : ¡Agregue una demostración en el espacio para abrazar!2023/03/27 : Soporte del modo de solo CPU. Ahora el modelo puede ejecutarse en máquinas sin GPU.2023/03/25 : una demostración para la base de Dino está disponible en Colab. [Skalskip]2023/03/22 : ¡El código ya está disponible! Casando a tierra a tierra dino y gligen
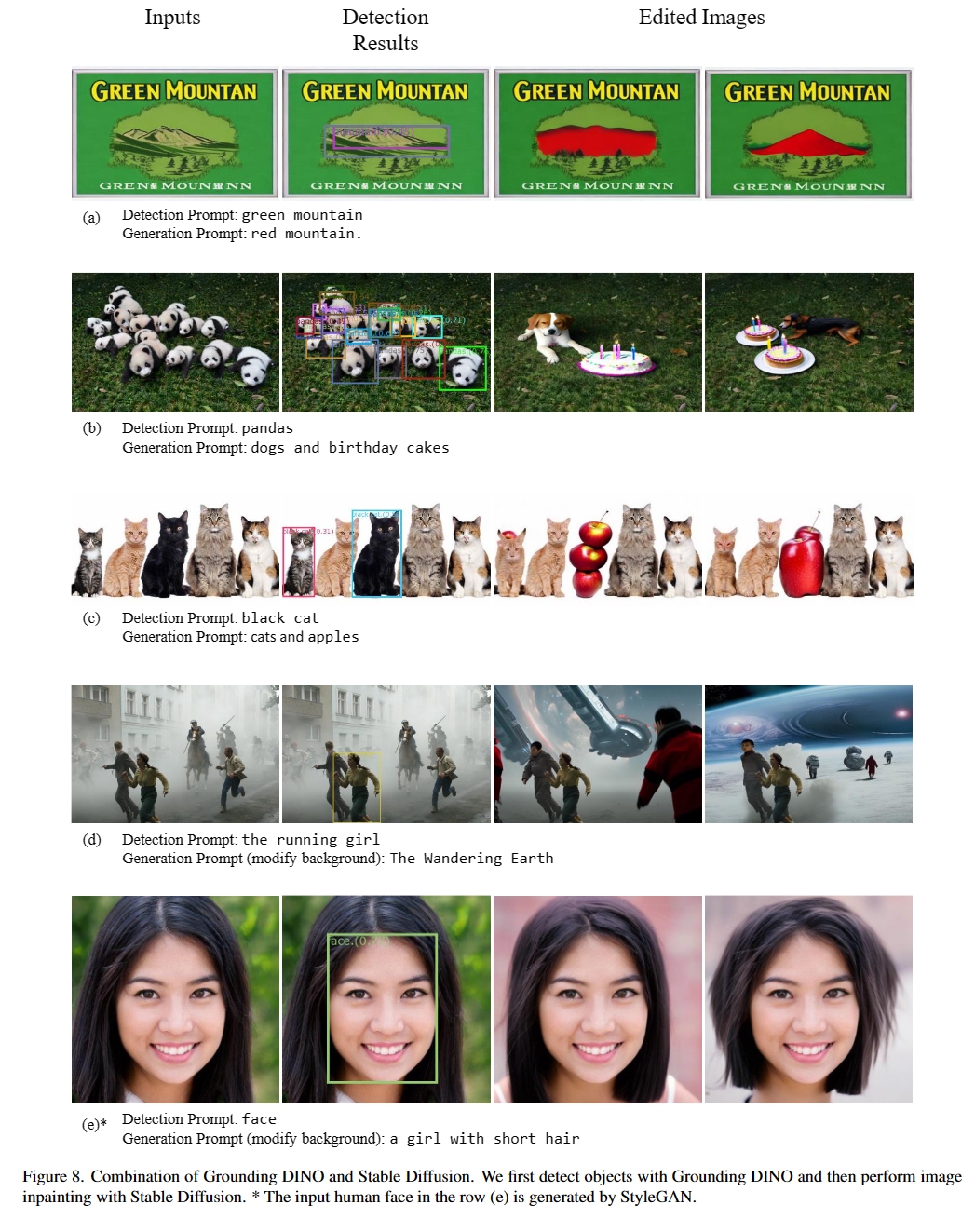
Casando a tierra a tierra dino y gligen (image, text) como entradas.900 cuadros de objeto (por defecto). Cada cuadro tiene puntajes de similitud en todas las palabras de entrada. (Como se muestra en las figuras a continuación).box_threshold .text_threshold como las etiquetas predichas.dogs en la oración two dogs with a stick. , puede seleccionar los cuadros con más altas similitudes de texto con dogs como salidas finales.. Para Dino de tierra. 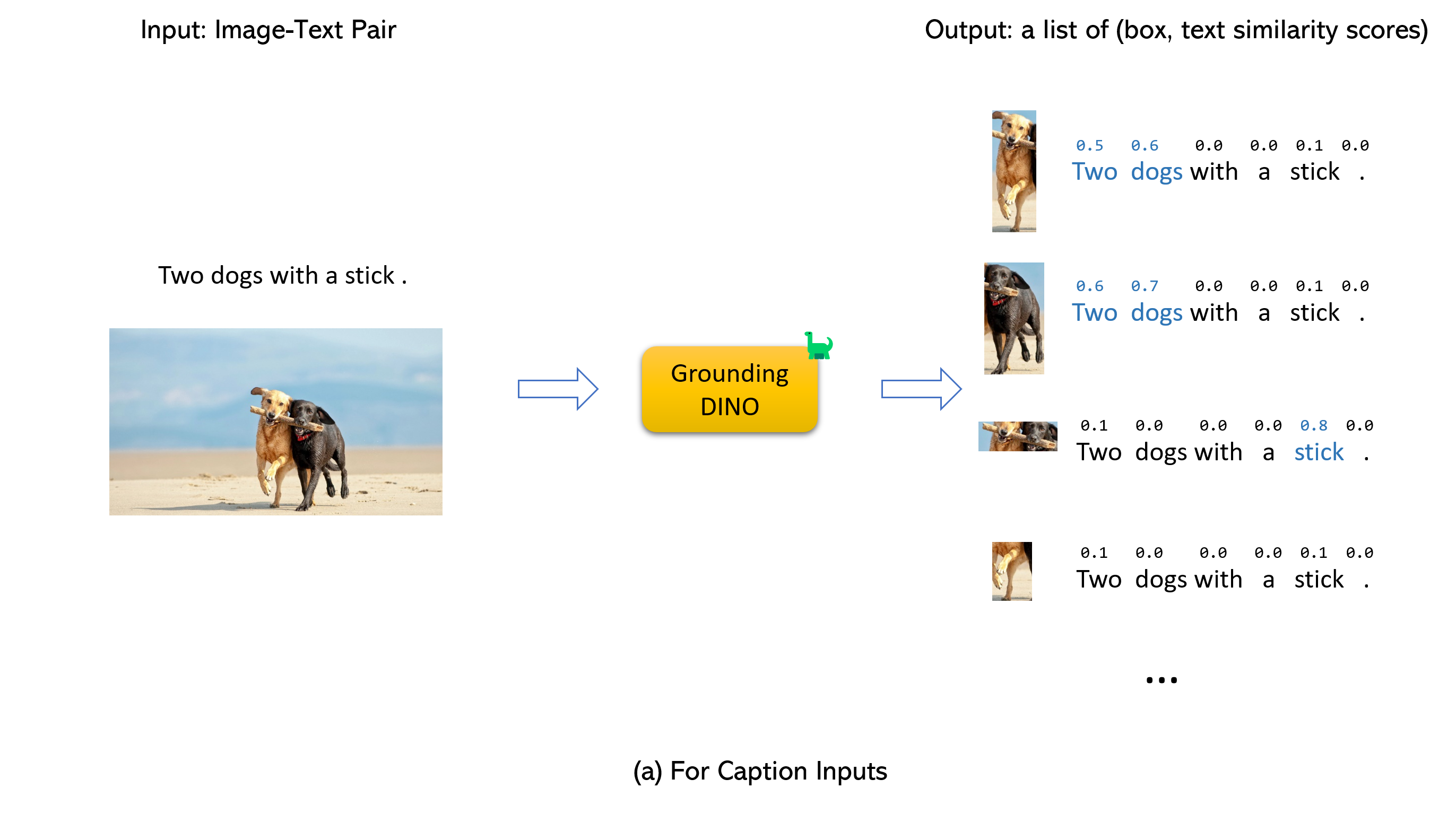
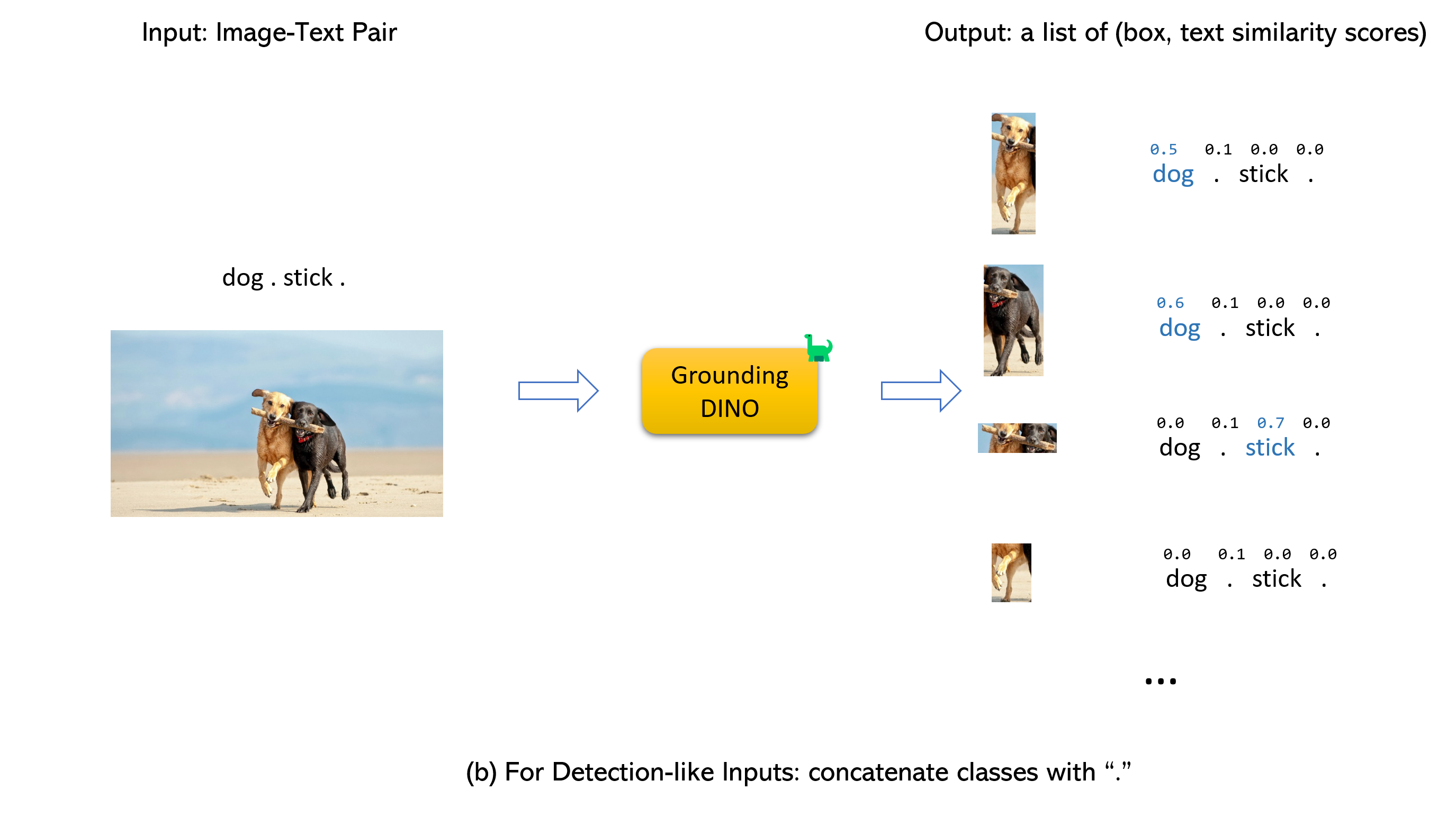
Nota:
CUDA_HOME . Se compilará en el modo de solo CPU si no está disponible CUDA.Asegúrese de seguir los pasos de instalación estrictamente; de lo contrario, el programa puede producir:
NameError: name ' _C ' is not definedSi esto sucedió, reinstalé el REDERNINGDINO reclone el GIT y vuelva a hacer todos los pasos de instalación.
echo $CUDA_HOMESi no imprime nada, entonces significa que no ha configurado la ruta/
Ejecute esto para que la variable de entorno se establezca en el shell actual.
export CUDA_HOME=/path/to/cuda-11.3Observe que la versión de CUDA debe estar alineada con su tiempo de ejecución CUDA, ya que puede existir múltiples CUDA al mismo tiempo.
Si desea establecer el CUDA_HOME de forma permanente, guárdelo usando:
echo ' export CUDA_HOME=/path/to/cuda ' >> ~ /.bashrcDespués de eso, obtenga el archivo BASHRC y verifique CUDA_HOME:
source ~ /.bashrc
echo $CUDA_HOMEEn este ejemplo, /path/to/cuda-11.3 debe reemplazarse con la ruta donde está instalado su kit de herramientas CUDA. Puede encontrar esto escribiendo qué NVCC en su terminal:
Por ejemplo, si la salida es/usr/local/cuda/bin/nvcc, entonces:
export CUDA_HOME=/usr/local/cudaInstalación:
1. Clone el repositorio de Grounddino de GitHub.
git clone https://github.com/IDEA-Research/GroundingDINO.git cd GroundingDINO/pip install -e .mkdir weights
cd weights
wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth
cd ..Verifique su ID de GPU (solo si está usando una GPU)
nvidia-smi Reemplazar {GPU ID} , image_you_want_to_detect.jpg , y "dir you want to save the output" con los valores apropiados en el siguiente comando
CUDA_VISIBLE_DEVICES={GPU ID} python demo/inference_on_a_image.py
-c groundingdino/config/GroundingDINO_SwinT_OGC.py
-p weights/groundingdino_swint_ogc.pth
-i image_you_want_to_detect.jpg
-o " dir you want to save the output "
-t " chair "
[--cpu-only] # open it for cpu modeSi desea especificar las frases para detectar, aquí hay una demostración:
CUDA_VISIBLE_DEVICES={GPU ID} python demo/inference_on_a_image.py
-c groundingdino/config/GroundingDINO_SwinT_OGC.py
-p ./groundingdino_swint_ogc.pth
-i .asset/cat_dog.jpeg
-o logs/1111
-t " There is a cat and a dog in the image . "
--token_spans " [[[9, 10], [11, 14]], [[19, 20], [21, 24]]] "
[--cpu-only] # open it for cpu mode Los token_spans especifican las posiciones de inicio y final de una frases. Por ejemplo, la primera frase es [[9, 10], [11, 14]] . "There is a cat and a dog in the image ."[9:10] = 'a' , "There is a cat and a dog in the image ."[11:14] = 'cat' . Por lo tanto, se refiere a la frase a cat . Del mismo modo, el [[19, 20], [21, 24]] se refiere a la frase a dog .
Consulte la demo/inference_on_a_image.py para obtener más detalles.
Corriendo con Python:
from groundingdino . util . inference import load_model , load_image , predict , annotate
import cv2
model = load_model ( "groundingdino/config/GroundingDINO_SwinT_OGC.py" , "weights/groundingdino_swint_ogc.pth" )
IMAGE_PATH = "weights/dog-3.jpeg"
TEXT_PROMPT = "chair . person . dog ."
BOX_TRESHOLD = 0.35
TEXT_TRESHOLD = 0.25
image_source , image = load_image ( IMAGE_PATH )
boxes , logits , phrases = predict (
model = model ,
image = image ,
caption = TEXT_PROMPT ,
box_threshold = BOX_TRESHOLD ,
text_threshold = TEXT_TRESHOLD
)
annotated_frame = annotate ( image_source = image_source , boxes = boxes , logits = logits , phrases = phrases )
cv2 . imwrite ( "annotated_image.jpg" , annotated_frame )Ui web
También proporcionamos un código de demostración para integrar a la base de Dino con la interfaz de usuario web de Gradio. Consulte la demo/gradio_app.py para obtener más detalles.
Cuadernos
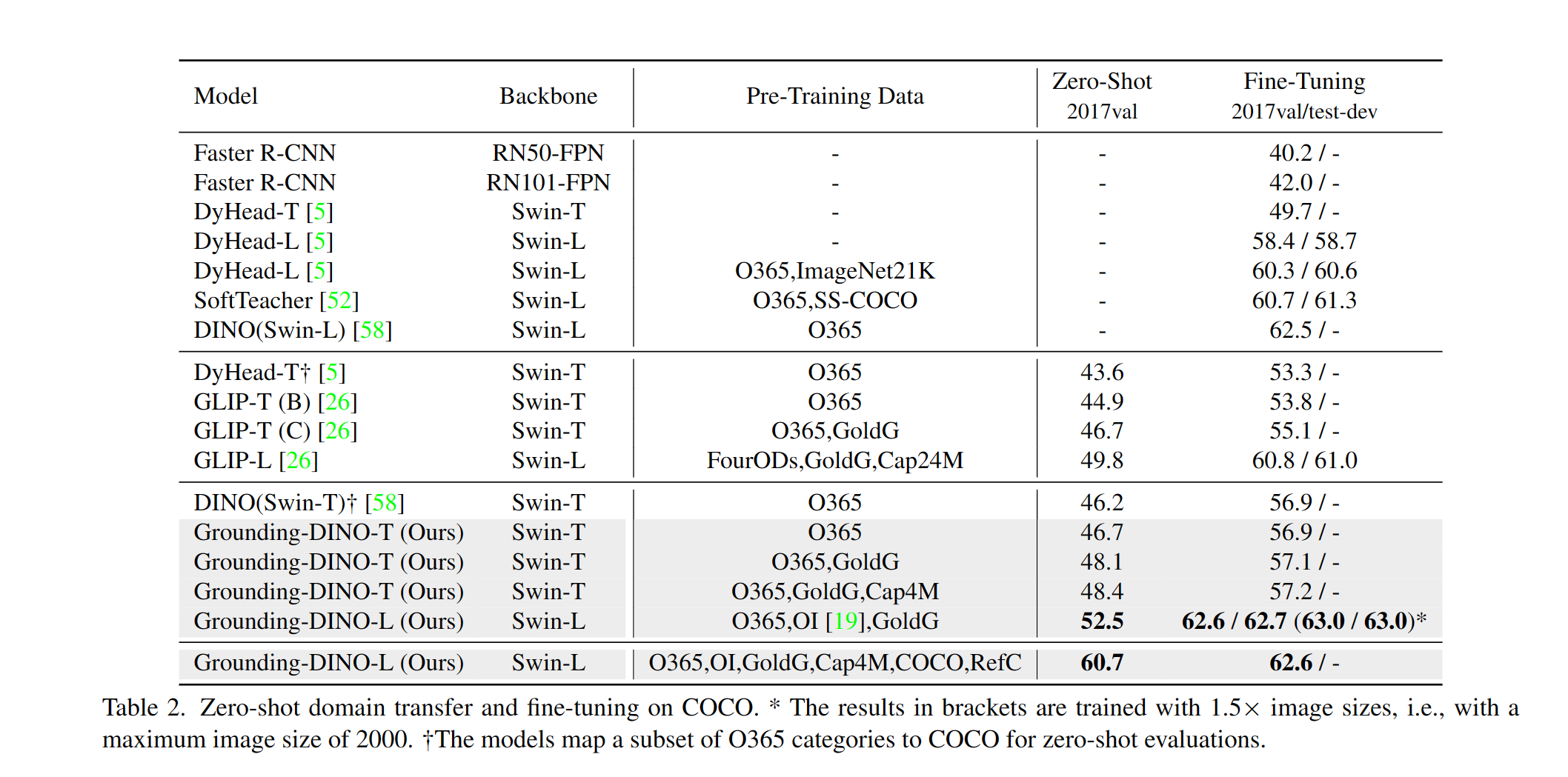
Proporcionamos un ejemplo para evaluar el rendimiento de la conexión a cero de Dino en Coco. Los resultados deben ser 48.5 .
CUDA_VISIBLE_DEVICES=0
python demo/test_ap_on_coco.py
-c groundingdino/config/GroundingDINO_SwinT_OGC.py
-p weights/groundingdino_swint_ogc.pth
--anno_path /path/to/annoataions/ie/instances_val2017.json
--image_dir /path/to/imagedir/ie/val2017| nombre | columna vertebral | Datos | Box AP en Coco | Control | Configuración | |
|---|---|---|---|---|---|---|
| 1 | Groundingdino-T | Tiratriente | O365, Goldg, Cap4m | 48.4 (disparo cero) / 57.2 (tune fino) | Enlace de Github | Enlace HF | enlace |
| 2 | Groundingdino-B | Swin-B | Coco, O365, Goldg, Cap4m, OpenImage, OdinW-35, Refcoco | 56.7 | Enlace de Github | Enlace HF | enlace |

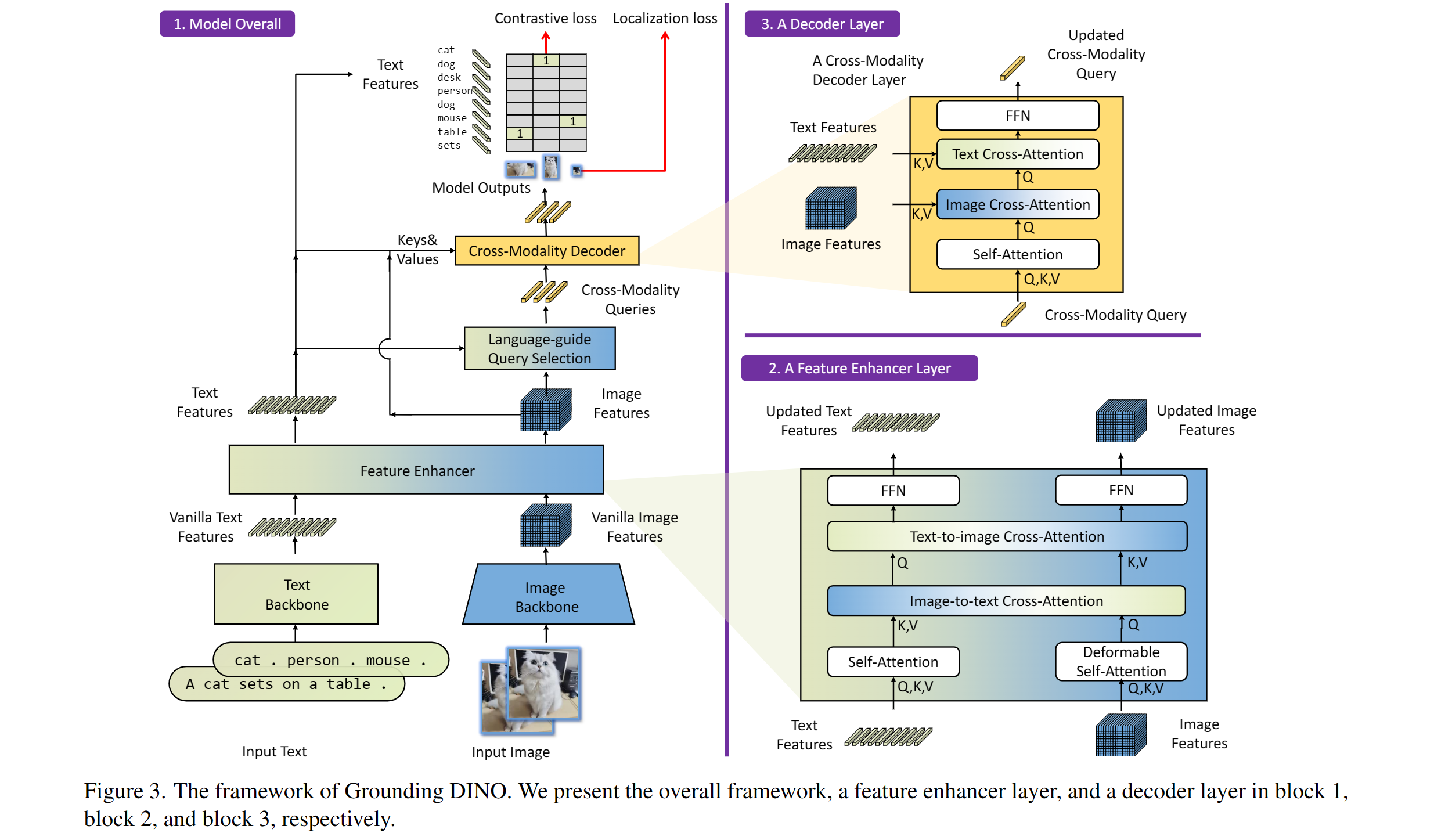
Incluye: una columna vertebral de texto, una columna vertebral de imagen, un potenciador de características, una selección de consultas guiada por el lenguaje y un decodificador de modalidad cruzada.
Nuestro modelo está relacionado con Dino y Glip. ¡Gracias por su gran trabajo!
También agradecemos que los grandes trabajos anteriores incluyen DETR, DETR deformable, SMCA, DETR condicional, Anchor DEPR, Dynamic DETR, DAB-Detr, DN-Detr, etc. El trabajo más relacionado está disponible en un impresionante transformador de detección. También está disponible una nueva caja de herramientas Detrex.
Gracias Difusión estable y gligen por sus increíbles modelos.
Si encuentra útil nuestro trabajo para su investigación, considere citar la siguiente entrada de Bibtex.
@article { liu2023grounding ,
title = { Grounding dino: Marrying dino with grounded pre-training for open-set object detection } ,
author = { Liu, Shilong and Zeng, Zhaoyang and Ren, Tianhe and Li, Feng and Zhang, Hao and Yang, Jie and Li, Chunyuan and Yang, Jianwei and Su, Hang and Zhu, Jun and others } ,
journal = { arXiv preprint arXiv:2303.05499 } ,
year = { 2023 }
}

