
La implementación oficial de GFT, un modelo de base de tarea cruzada de dominio cruzado en gráficos. El logotipo es generado por Dall · E 3.
Escrito por Zehong Wang, Zheyuan Zhang, Nitesh V Chawla, Chuxu Zhang y Yanfang Ye.
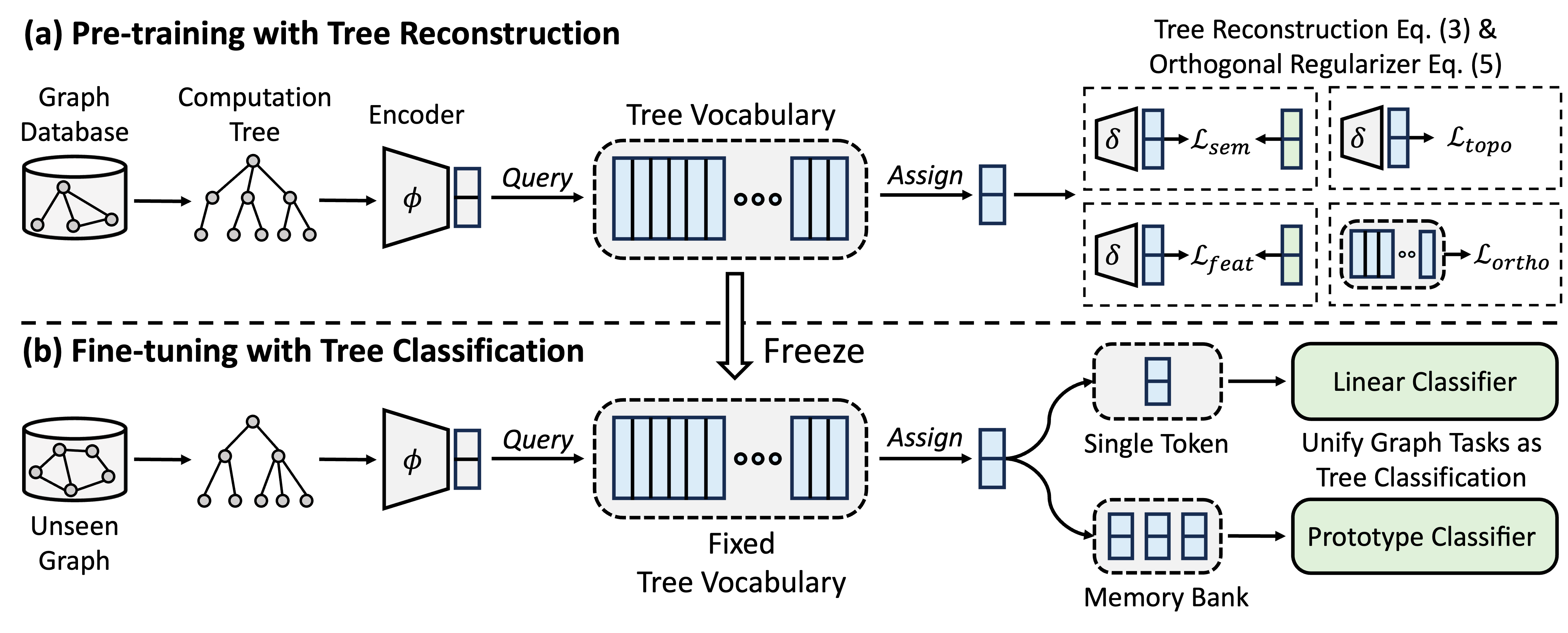
GFT es un modelo de base de gráficos de dominio cruzado y de tarea cruzada, que trata los árboles de cálculo como los patrones transferibles para obtener un vocabulario de árbol transferible. Además, GFT proporciona un marco unificado para alinear tareas relacionadas con gráficos, permitiendo un solo modelo de gráfico, por ejemplo, GNN, para manejar conjuntamente tareas a nivel de nodo, nivel de borde y nivel gráfico.
Durante el pre-entrenamiento, el modelo codifica el conocimiento general de una base de datos de gráficos en un vocabulario de árbol a través de una tarea de reconstrucción de árboles. En el ajuste, el vocabulario de árbol aprendido se aplica para unificar tareas relacionadas con gráficos como tareas de clasificación de árboles, adaptando el conocimiento general adquirido a tareas específicas.
Puede usar conda para instalar el entorno. Ejecute el siguiente script. Ejecutamos todos los experimentos en una sola GPU A40 48G, pero una GPU con memoria de 24 g es suficiente para manejar todos los conjuntos de datos con mini lote.
conda env create -f environment.yml
conda activate GFT
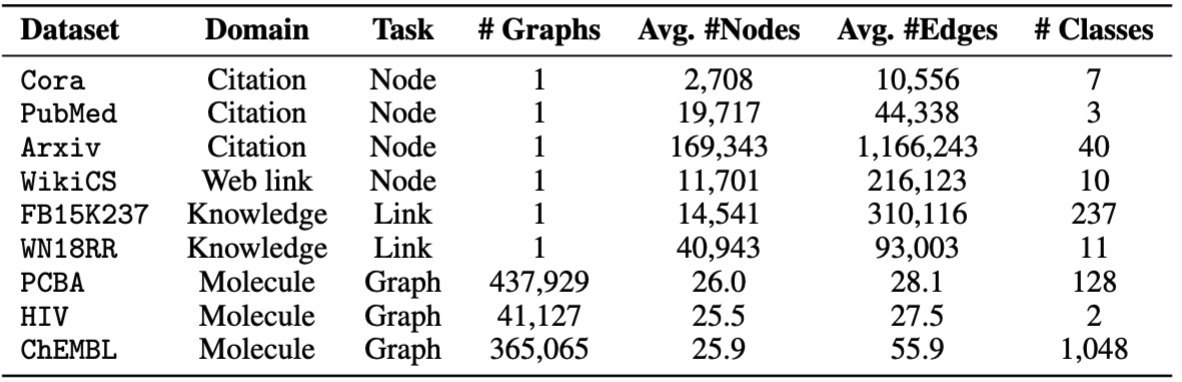
Utilizamos conjuntos de datos proporcionados por OFA. Puede ejecutar pretrain.py para descargar automáticamente los conjuntos de datos, que se descargará en /data de forma predeterminada. La tubería preprocesará automáticamente los conjuntos de datos convirtiendo las descripciones textuales en integridades textuales.
Alternativamente, puede descargar nuestros conjuntos de datos preprocesados y descomponer la carpeta /data .
El código de GFT se presenta en la carpeta /GFT . La estructura es la siguiente.
└── GFT
├── pretrain.py
├── finetune.py
├── dataset
│ ├── ...
│ └── process_datasets.py
├── model
│ ├── encoder.py
│ ├── vq.py
│ ├── pt_model.py
│ └── ft_model.py
├── task
│ ├── node.py
│ ├── link.py
│ └── graph.py
└── utils
├── args.py
├── loader.py
└── ...
Puede ejecutar pretrain.py para realizar preventamente en una amplia gama de gráficos y finetune.py para adaptación a ciertas tareas posteriores con un aprendizaje básico de fino o de pocos disparos.
Para reproducir los resultados, proporcionamos hiper-parametros detallados tanto para el pretrete como para el sintonización, mantenidos en config/pretrain.yaml y config/finetune.yaml , respectivamente. Para aprovechar los hiperparametros predeterminados, proporcionamos un comando --use_params para Pretrin y Finetune.
# Pretraining with default hyper-parameters
python GFT/pretrain.py --use_params
# Finetuning on Cora with default hyper-parameters
python GFT/finetune.py --use_params --dataset cora
# Few-shot learning on Cora with default hyper-parameters
python GFT/finetune.py --use_params --dataset cora --setting few_shot
Para Finetuning, proporcionamos ocho conjuntos de datos, incluidos cora , pubmed , wikics , arxiv , WN18RR , FB15K237 , chemhiv y chempcba .
Alternativamente, puede ejecutar el script para reproducir los experimentos.
# Pretraining with default hyper-parameters
sh script/pretrain.sh
# Finetuning on all datasets with default hyper-parameters
sh script/finetune.sh
# Few-shot learning on all datasets with default hyper-parameters
sh script/few_shot.sh
Nota: El modelo previamente se almacenará en ckpts/pretrain_model/ de forma predeterminada.
# The basic command for pretraining GFT
python GFT/pretrain.py
Cuando ejecuta pretrain.py , puede personalizar los conjuntos de datos de previación y los hiperparametros.
Puede usar --pretrain_dataset (o --pt_data ) para establecer los conjuntos de datos de pretrén usados y los pesos correspondientes. La configuración de datos predefinidas está en config/pt_data.yaml , con las siguientes estructuras.
all:
cora: 5
pubmed: 5
arxiv: 5
wikics: 5
WN18RR: 5
FB15K237: 10
chemhiv: 1
chemblpre: 0.1
chempcba: 0.1
...
En el caso anterior, all es el nombre de la configuración, lo que significa que todos los conjuntos de datos se utilizan en el pretrénmente. Para cada conjunto de datos, hay un par de pares de valor clave, donde la clave es el nombre del conjunto de datos y el valor es el peso de muestreo. Por ejemplo, cora: 5 significa que el conjunto de datos cora se muestreará 5 veces en una sola época. Puede diseñar su propia combinación de conjuntos de datos para el envío de GFT.
Puede personalizar la fase previa a la altura alterando los hiperparámetros del codificador, la cuantización del vector, la capacitación del modelo.
--pretrain_dataset : indique el conjunto de datos de previación. Lo mismo para lo anterior.--use_params : use los hiper-parametros predefinidos.--seed : La semilla utilizada para el pretrenamiento.--hidden_dim : la dimensión en la capa oculta de GNNS.--num_layers : las capas GNN.--activation : la función de activación.--backbone : la columna vertebral GNN.--normalize : la capa de normalización.--dropout : el abandono de la capa GNN.--code_dim : la dimensión de cada código en el vocabulario.--codebook_size : el número de códigos en el vocabulario.--codebook_head : el número de cabezas de libros de códigos. Si el número es mayor que 1, usará conjuntamente múltiples vocabularios.--codebook_decay : la tasa de descomposición de los códigos.--commit_weight : el peso del término de compromiso.--pretrain_epochs : el número de épocas.--pretrain_lr : la tasa de aprendizaje.--pretrain_weight_decay : el peso del regularizador L2.--pretrain_batch_size : el tamaño de lotes.--feat_p : la tasa de corrupción de la función.--edge_p : la tasa de corrupción de borde/estructura.--topo_recon_ratio : la relación de los bordes debe reconstruirse.--feat_lambda : el peso de la pérdida de características.--topo_lambda : el peso de la pérdida de topología.--topo_sem_lambda : el peso de la pérdida de topología en las características del borde de reconstrucción.--sem_lambda : el peso de la pérdida semántica.--sem_encoder_decay : la tasa de actualización de impulso para el codificador semántico. # The basic command for adapting GFT on downstream tasks via finetuning.
python GFT/finetune.py
Puede establecer --dataset para indicar el conjunto de datos aguas abajo y --use_params para usar los hiperparametadores predefinidos para cada conjunto de datos. Otros hiper-parametros que puede indicar se presentan de la siguiente manera.
Para gráficos con 1 división predefinida, puede configurar --repeat para realizar múltiples experimentos.
--hidden_dim : la dimensión en la capa oculta de GNNS.--num_layers : las capas GNN.--activation : la función de activación.--backbone : la columna vertebral GNN.--normalize : la capa de normalización.--dropout : el abandono de la capa GNN.--code_dim : la dimensión de cada código en el vocabulario.--codebook_size : el número de códigos en el vocabulario.--codebook_head : el número de cabezas de libros de códigos. Si el número es mayor que 1, usará conjuntamente múltiples vocabularios.--codebook_decay : la tasa de descomposición de los códigos.--commit_weight : el peso del término de compromiso.--finetune_epochs : el número de épocas.--finetune_lr : la tasa de aprendizaje.--early_stop : la época máxima de parada temprana.--batch_size : si se establece en 0, realice entrenamiento de gráficos completo. --lambda_proto : el peso del clasificador prototipo en finecing.
--lambda_act : el peso del clasificador lineal en la sintonización Finet.
--trade_off : la compensación entre usar prototipo Classier o usar clasificador lineal en inferencia.
Puede agregar --no_lin_clf o --no_proto_clf para evitar usar clasificador lineal o clasificador prototipo, respectivamente. Tenga en cuenta que estos dos términos son conflictos, ya que debe usar al menos un clasificador.
# The basic command for adaptation GFT on downstream tasks via few-shot learning.
python GFT/finetune.py --setting few_shot
Puede establecer --dataset para indicar el conjunto de datos aguas abajo y --use_params para usar los hiperparametadores predefinidos para cada conjunto de datos. Otros hiper-parametros que puede indicar se presentan de la siguiente manera.
Los hiper-parametros dedicados para el aprendizaje de pocos disparos son
--n_train : el número de instancias de entrenamiento por clase para Finetuning the Model. Tenga en cuenta que Small n_train logra un rendimiento deseable --n_task : el número de tareas muestreadas.--n_way : el número de formas.--n_query : el tamaño del conjunto de consultas por forma.--n_shot : el tamaño de soporte establecido por forma.--hidden_dim : la dimensión en la capa oculta de GNNS.--num_layers : las capas GNN.--activation : la función de activación.--backbone : la columna vertebral GNN.--normalize : la capa de normalización.--dropout : el abandono de la capa GNN.--code_dim : la dimensión de cada código en el vocabulario.--codebook_size : el número de códigos en el vocabulario.--codebook_head : el número de cabezas de libros de códigos. Si el número es mayor que 1, usará conjuntamente múltiples vocabularios.--codebook_decay : la tasa de descomposición de los códigos.--commit_weight : el peso del término de compromiso.--finetune_epochs : el número de épocas.--finetune_lr : la tasa de aprendizaje.--early_stop : la época máxima de parada temprana.--batch_size : si se establece en 0, realice entrenamiento de gráficos completo. --lambda_proto : el peso del clasificador prototipo en finecing.
--lambda_act : el peso del clasificador lineal en la sintonización Finet.
--trade_off : la compensación entre usar prototipo Classier o usar clasificador lineal en inferencia.
Puede agregar --no_lin_clf o --no_proto_clf para evitar usar clasificador lineal o clasificador prototipo, respectivamente. Tenga en cuenta que estos dos términos son conflictos, ya que debe usar al menos un clasificador.
Los resultados experimentales pueden variar debido a la inicialización aleatoria durante el pretratenamiento. Proporcionamos los resultados experimentales utilizando diferentes semillas aleatorias (es decir, 1-5) en el pretratamiento para mostrar el impacto potencial de la inicialización aleatoria.
| Cora | Pubmed | Wiki-cs | Arxiv | WN18RR | FB15K237 | VIH | PCBA | Promedio | |
|---|---|---|---|---|---|---|---|---|---|
| Semilla = 1 | 78.58 ± 0.90 | 77.55 ± 1.54 | 79.38 ± 0.57 | 72.24 ± 0.16 | 91.56 ± 0.33 | 89.67 ± 0.35 | 72.69 ± 1.93 | 78.24 ± 0.23 | 79.99 |
| Semilla = 2 | 78.27 ± 1.26 | 76.41 ± 1.36 | 79.36 ± 0.62 | 72.13 ± 0.24 | 91.72 ± 0.19 | 89.66 ± 0.31 | 71.62 ± 2.45 | 78.20 ± 0.33 | 79.67 |
| Semilla = 3 | 78.16 ± 1.62 | 76.28 ± 1.37 | 79.32 ± 0.65 | 72.13 ± 0.30 | 91.57 ± 0.44 | 89.78 ± 0.23 | 71.58 ± 2.28 | 78.12 ± 0.37 | 79.62 |
| Semilla = 4 | 78.42 ± 1.37 | 75.76 ± 1.58 | 79.44 ± 0.62 | 72.36 ± 0.34 | 91.70 ± 0.24 | 89.73 ± 0.21 | 72.57 ± 2.46 | 78.34 ± 0.27 | 79.79 |
| Semilla = 5 | 78.56 ± 1.62 | 76.49 ± 2.00 | 79.27 ± 0.55 | 72.18 ± 0.26 | 91.47 ± 0.39 | 89.80 ± 0.19 | 72.27 ± 0.93 | 78.31 ± 0.34 | 79.79 |
| Reportado | 78.62 ± 1.21 | 77.19 ± 1.99 | 79.39 ± 0.42 | 71.93 ± 0.12 | 91.91 ± 0.34 | 89.72 ± 0.20 | 72.67 ± 1.38 | 77.90 ± 0.64 | 79.92 |
Para garantizar mejor la reproducibilidad, proporcionamos los puntos de control de la semilla = 1 en este enlace. Seleccionamos esto debido a su mejor rendimiento promedio. Puede descomponer el archivo descargado en la ruta ckpts/pretrain_model/ , y establecer el --pt_seed 1 cuando se usa finetune.py para aprovechar delicadamente nuestros puntos de control proporcionados.
Póngase en contacto con [email protected] o abra un problema si tiene preguntas.
Si encuentra que el repositorio es útil para su investigación, cite el artículo original correctamente.
@inproceedings { wang2024gft ,
title = { GFT: Graph Foundation Model with Transferable Tree Vocabulary } ,
author = { Wang, Zehong and Zhang, Zheyuan and Chawla, Nitesh V and Zhang, Chuxu and Ye, Yanfang } ,
booktitle = { The Thirty-eighth Annual Conference on Neural Information Processing Systems } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=0MXzbAv8xy }
}Este repositorio se basa en la base de código de OFA, PYG, OGB y VQ. ¡Gracias por compartir!


