vision_transformer
1.0.0
En este repositorio lanzamos modelos de los documentos
Los modelos se entrenaron previamente en los conjuntos de datos ImageNet e ImageNet-21K. Proporcionamos el código para ajustar los modelos lanzados en Jax/Flax.
Los modelos de esta base de código se capacitaron originalmente en https://github.com/google-research/big_vision/ donde puede encontrar un código más avanzado (por ejemplo, entrenamiento multi-host), así como algunos de los scripts de entrenamiento originales (EG Configs /vit_i21k.py para la capacitación previa de un Vit, o config/transfer.py para transferir un modelo).
Tabla de contenido:
Debajo de Colabs se ejecutan tanto con GPU como con TPUS (8 núcleos, paralelismo de datos).
El primer Colab demuestra el código Jax de Transformadores de Visión y los mezcladores MLP. Este Colab le permite editar los archivos desde el repositorio directamente en la interfaz de usuario de Colab y ha anotado las celdas de Colab que lo guían a través del código paso a paso y le permite interactuar con los datos.
https://colab.research.google.com/github/google-research/Vision_transformer/blob/main/vit_jax.ipynb
El segundo Colab le permite explorar el transformador de visión> 50K y los puntos de control híbridos que se utilizaron para generar los datos del tercer artículo "¿Cómo entrenar su Vit? ...". El COLAB incluye código para explorar y seleccionar puntos de control, y para hacer inferencia tanto utilizando el código JAX de este repositorio, y también utilizando la popular biblioteca timm Pytorch que también puede cargar directamente estos puntos de control. Tenga en cuenta que un puñado de modelos también están disponibles directamente desde TF-HUB: SayakPaul/Collections/Vision_Transformer (contribución externa de Sayak Paul).
El segundo Colab también le permite ajustar los puntos de control en cualquier conjunto de datos TFDS y su propio conjunto de datos con ejemplos en archivos JPEG individuales (opcionalmente leyendo directamente desde Google Drive).
https://colab.research.google.com/github/google-research/Vision_transformer/blob/main/vit_jax_augreg.ipynb
Nota : Como ahora (6/20/21), Google Colab solo admite una sola GPU (NVIDIA TESLA T4), y las TPU (actualmente TPUV2-8) se adjuntan indirectamente a la VM Colab y se comunican a través de la red lenta, lo que conduce a bonitas mala velocidad de entrenamiento. Por lo general, desea configurar una máquina dedicada si tiene una cantidad no trivial de datos para ajustar. Para obtener más detalles, consulte la sección Ejecución en la nube.
Asegúrese de tener Python>=3.10 instalado en su máquina.
Instale las dependencias de Jax y Python ejecutando:
# If using GPU:
pip install -r vit_jax/requirements.txt
# If using TPU:
pip install -r vit_jax/requirements-tpu.txt
Para versiones más nuevas de Jax, siga las instrucciones proporcionadas en el repositorio correspondiente vinculado aquí. Tenga en cuenta que las instrucciones de instalación para CPU, GPU y TPU difieren ligeramente.
Instale Flaxformer, siga las instrucciones proporcionadas en el repositorio correspondiente vinculado aquí.
Para obtener más detalles, consulte la sección que se ejecuta en la nube a continuación.
Puede ejecutar el ajuste del modelo descargado en su conjunto de datos de interés. Todos los modelos comparten la misma interfaz de línea de comando.
Por ejemplo, para ajustar un VIT-B/16 (previamente entrenado en ImageNet21k) en CIFAR10 (tenga en cuenta cómo especificamos b16,cifar10 como argumentos para la configuración y cómo instruimos el código que acceda a los modelos directamente desde un cubo GCS En lugar de descargarlos primero en el directorio local):
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/vit.py:b16,cifar10
--config.pretrained_dir= ' gs://vit_models/imagenet21k 'Para ajustar un mezclador-B/16 (previamente entrenado en ImageNet21k) en CIFAR10:
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/mixer_base16_cifar10.py
--config.pretrained_dir= ' gs://mixer_models/imagenet21k ' configs/augreg.py ¿Cómo entrenar su Vit? Cuando solo especifica el nombre del modelo (el valor config.name de configs/model.py ), entonces se elige el mejor punto de control I21K mediante precisión de validación ascendente (punto de control "recomendado", consulte la Sección 4.5 del documento). Para decidir qué modelo desea usar, eche un vistazo a la Figura 3 en el papel. También es posible elegir un punto de control diferente (ver Colab vit_jax_augreg.ipynb ) y luego especificar el valor del filename o la columna adapt_filename , que corresponde a los nombres de archivo sin .npz del directorio gs://vit_models/augreg .
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/augreg.py:R_Ti_16
--config.dataset=oxford_iiit_pet
--config.base_lr=0.01 Actualmente, el código descargará automáticamente los conjuntos de datos CIFAR-10 y CIFAR-100. Otros conjuntos de datos públicos o personalizados se pueden integrar fácilmente, utilizando la biblioteca de conjuntos de datos TensorFlow. Tenga en cuenta que también deberá actualizar vit_jax/input_pipeline.py para especificar algunos parámetros sobre cualquier conjunto de datos agregado.
Tenga en cuenta que nuestro código utiliza todas las GPU/TPU disponibles para ajustar.
Para ver una lista detallada de todas las banderas disponibles, ejecute python3 -m vit_jax.train --help .
Notas sobre la memoria:
--config.accum_steps=8 -alternativamente, también puede disminuir el --config.batch=512 (y disminuir --config.base_lr en consecuencia).--config.shuffle_buffer=50000 . Por Alexey Dosovitskiy*†, Lucas Beyer*, Alexander Kolesnikov*, Dirk Weissenborn*, Xiaohua Zhai*, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit y Neil Hulasby*†.
(*) Contribución técnica igual, (†) Asesoramiento igual.
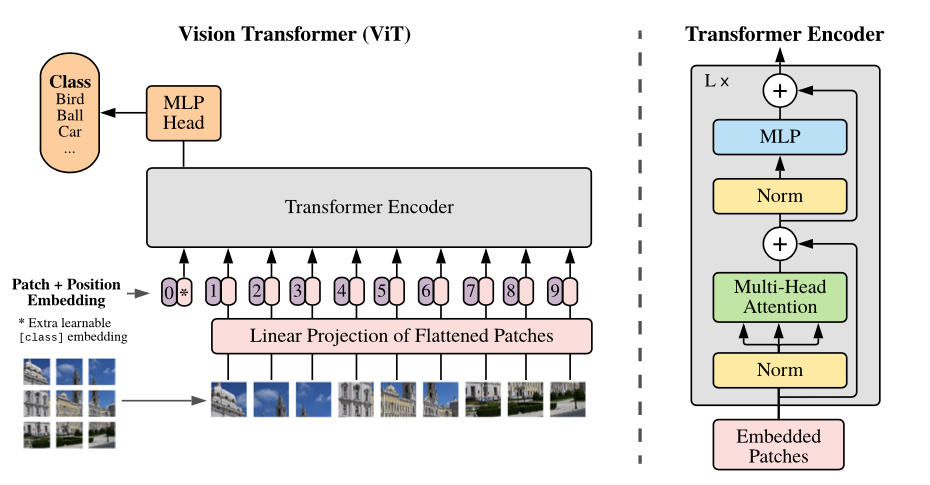
Descripción general del modelo: dividimos una imagen en parches de tamaño fijo, incrusimos linealmente cada uno de ellos, agregamos incrustaciones de posición y alimentamos la secuencia resultante de vectores a un codificador de transformador estándar. Para realizar la clasificación, utilizamos el enfoque estándar de agregar un "Token de clasificación" adicional de aprendizaje a la secuencia.
Proporcionamos una variedad de modelos VIT en diferentes cubos GCS. Los modelos se pueden descargar con EG:
wget https://storage.googleapis.com/vit_models/imagenet21k/ViT-B_16.npz
Los nombres de archivo modelo (sin la extensión .npz ) corresponden a config.model_name in vit_jax/configs/models.py
gs://vit_models/imagenet21k -modelos previamente entrenados en ImageNet-21K.gs://vit_models/imagenet21k+imagenet2012 -modelos previamente entrenados en ImageNet-21k y ajustados en Imagenet.gs://vit_models/augreg : modelos previamente entrenados en ImageNet-21k, aplicando cantidades variables de Augureg. Rendimiento mejorado.gs://vit_models/sam - modelos previamente entrenados en Imagenet con SAM.gs://vit_models/gsam - Modelos previamente entrenados en Imagenet con GSAM.Recomendamos usar los siguientes puntos de control, entrenados con Augreg que tienen las mejores métricas de pre-entrenamiento:
| Modelo | Punto de control previamente capacitado | Tamaño | Punto de control afinado | Resolución | Img/seg | Precisión de Imagenet |
|---|---|---|---|---|---|---|
| L/16 | gs://vit_models/augreg/L_16-i21k-300ep-lr_0.001-aug_strong1-wd_0.1-do_0.0-sd_0.0.npz | 1243 MIB | gs://vit_models/augreg/L_16-i21k-300ep-lr_0.001-aug_strong1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 50 | 85.59% |
| B/16 | gs://vit_models/augreg/B_16-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.0-sd_0.0.npz | 391 MIB | gs://vit_models/augreg/B_16-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 138 | 85.49% |
| S/16 | gs://vit_models/augreg/S_16-i21k-300ep-lr_0.001-aug_light1-wd_0.03-do_0.0-sd_0.0.npz | 115 MIB | gs://vit_models/augreg/S_16-i21k-300ep-lr_0.001-aug_light1-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 300 | 83.73% |
| R50+L/32 | gs://vit_models/augreg/R50_L_32-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.1-sd_0.1.npz | 1337 MIB | gs://vit_models/augreg/R50_L_32-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.1-sd_0.1--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 327 | 85.99% |
| R26+S/32 | gs://vit_models/augreg/R26_S_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0.npz | 170 MIB | gs://vit_models/augreg/R26_S_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 560 | 83.85% |
| Ti/16 | gs://vit_models/augreg/Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0.npz | 37 MIB | gs://vit_models/augreg/Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 610 | 78.22% |
| B/32 | gs://vit_models/augreg/B_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0.npz | 398 MIB | gs://vit_models/augreg/B_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 955 | 83.59% |
| S/32 | gs://vit_models/augreg/S_32-i21k-300ep-lr_0.001-aug_none-wd_0.1-do_0.0-sd_0.0.npz | 118 MIB | gs://vit_models/augreg/S_32-i21k-300ep-lr_0.001-aug_none-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 2154 | 79.58% |
| R+ti/16 | gs://vit_models/augreg/R_Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0.npz | 40 MIB | gs://vit_models/augreg/R_Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 2426 | 75.40% |
Los resultados del papel VIT original (https://arxiv.org/abs/2010.11929) se han replicado utilizando los modelos de gs://vit_models/imagenet21k :
| modelo | conjunto de datos | abandonado = 0.0 | abandono = 0.1 |
|---|---|---|---|
| R50+VIT-B_16 | cifar10 | 98.72%, 3.9h (A100), TB.dev | 98.94%, 10.1h (V100), TB.dev |
| R50+VIT-B_16 | cifar100 | 90.88%, 4.1H (A100), TB.DEV | 92.30%, 10.1h (V100), TB.dev |
| R50+VIT-B_16 | Imagenet2012 | 83.72%, 9.9h (A100), TB.dev | 85.08%, 24.2h (V100), TB.dev |
| Vit-B_16 | cifar10 | 99.02%, 2.2h (A100), TB.dev | 98.76%, 7.8h (V100), TB.dev |
| Vit-B_16 | cifar100 | 92.06%, 2.2h (A100), TB.dev | 91.92%, 7.8h (V100), TB.dev |
| Vit-B_16 | Imagenet2012 | 84.53%, 6.5h (A100), TB.dev | 84.12%, 19.3h (V100), TB.dev |
| Vit-B_32 | cifar10 | 98.88%, 0.8h (A100), TB.dev | 98.75%, 1.8h (V100), TB.DEV |
| Vit-B_32 | cifar100 | 92.31%, 0.8h (A100), TB.dev | 92.05%, 1.8h (V100), TB.dev |
| Vit-B_32 | Imagenet2012 | 81.66%, 3.3h (A100), TB.dev | 81.31%, 4.9h (V100), TB.DEV |
| Vit-L_16 | cifar10 | 99.13%, 6.9h (A100), TB.dev | 99.14%, 24.7h (V100), TB.dev |
| Vit-L_16 | cifar100 | 92.91%, 7.1h (A100), TB.dev | 93.22%, 24.4h (V100), TB.dev |
| Vit-L_16 | Imagenet2012 | 84.47%, 16.8h (A100), TB.dev | 85.05%, 59.7h (V100), TB.dev |
| Vit-L_32 | cifar10 | 99.06%, 1.9h (A100), TB.dev | 99.09%, 6.1h (V100), TB.dev |
| Vit-L_32 | cifar100 | 93.29%, 1.9h (A100), TB.dev | 93.34%, 6.2h (V100), TB.DEV |
| Vit-L_32 | Imagenet2012 | 81.89%, 7.5h (A100), TB.dev | 81.13%, 15.0h (V100), TB.dev |
También nos gustaría enfatizar que los resultados de alta calidad se pueden lograr con horarios de capacitación más cortos y alentar a los usuarios de nuestro código a jugar con hiperparametadores para intercambiar precisión y presupuesto computacional. Algunos ejemplos para conjuntos de datos CIFAR-10/100 se presentan en la tabla a continuación.
| río arriba | modelo | conjunto de datos | Total_steps / Warmup_steps | exactitud | Hora de la pared | enlace |
|---|---|---|---|---|---|---|
| imagenet21k | Vit-B_16 | cifar10 | 500 /50 | 98.59% | 17m | tensorboard.dev |
| imagenet21k | Vit-B_16 | cifar10 | 1000 /100 | 98.86% | 39m | tensorboard.dev |
| imagenet21k | Vit-B_16 | cifar100 | 500 /50 | 89.17% | 17m | tensorboard.dev |
| imagenet21k | Vit-B_16 | cifar100 | 1000 /100 | 91.15% | 39m | tensorboard.dev |
por Ilya Tolstikhin*, Neil Houlsby*, Alexander Kolesnikov*, Lucas Beyer*, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, Mario Lucic, Alexey Dosovitskiy.
(*) Contribución igual.
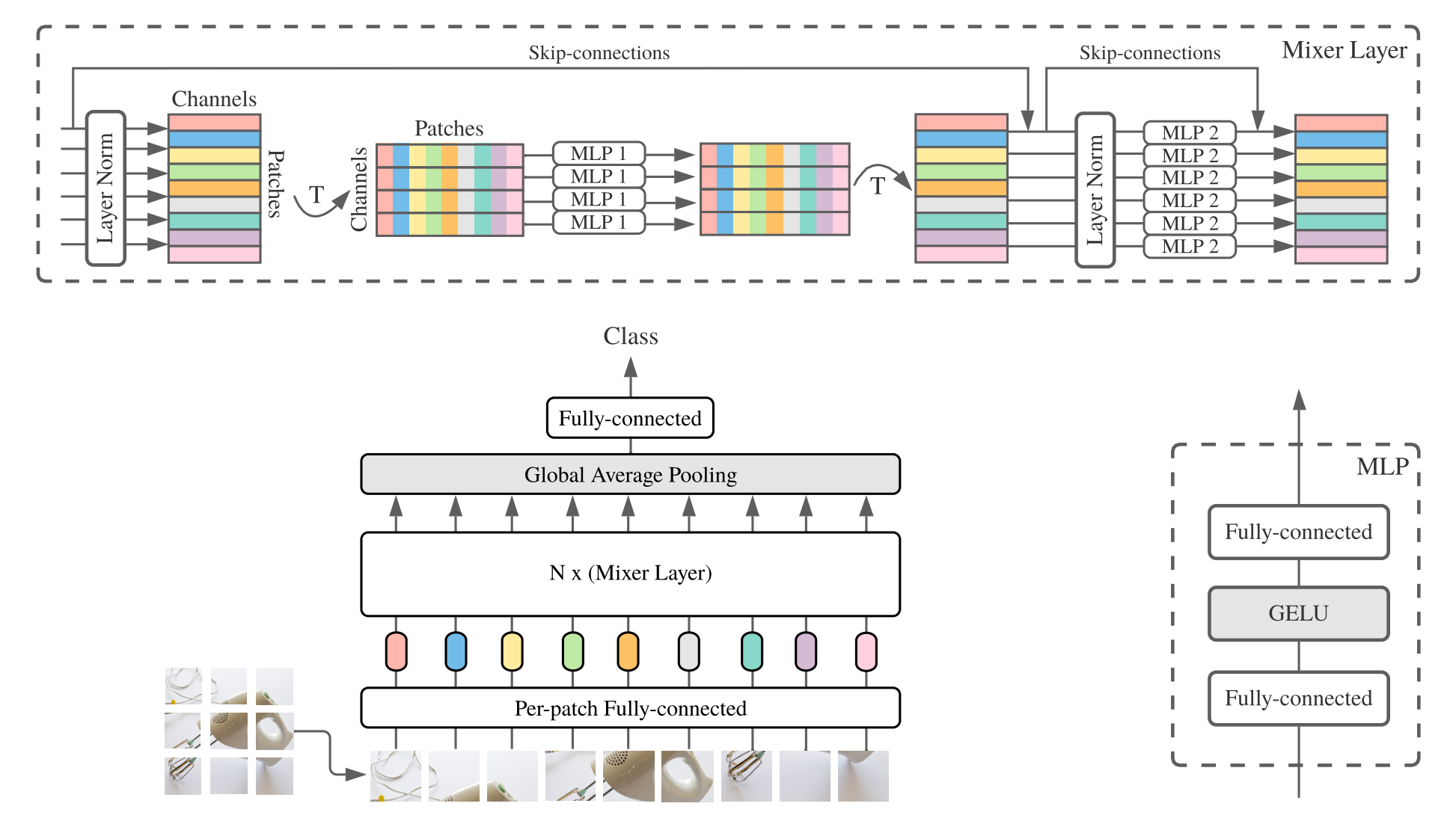
MLP-Mixer ( mezclador para abreviar) consiste en incrustaciones lineales por parche, capas mezcladoras y un cabezal clasificador. Las capas mezcladoras contienen un MLP de mezcla de token y un MLP de mezcla de canales, cada una y consta de dos capas totalmente conectadas y una no linealidad de Gelu. Otros componentes incluyen: saltos de protección, abandono y cabezal de clasificador lineal.
Para la instalación, siga los mismos pasos que anteriormente.
Proporcionamos los modelos mezcladores-b/16 y mezclador-l/16 previamente entrenados en los conjuntos de datos Imagenet e ImageNet-21K. Los detalles se pueden encontrar en la Tabla 3 del papel mezclador. Todos los modelos se pueden encontrar en:
https://console.cloud.google.com/storage/mixer_models/
Tenga en cuenta que estos modelos también están disponibles directamente desde TF-HUB: SayakPaul/Collections/MLP-Mixer (contribución externa de Sayak Paul).
Ejecutamos el código de ajuste fino en Google Cloud Machine con cuatro GPU V100 con los parámetros de adaptación predeterminados de este repositorio. Aquí están los resultados:
| río arriba | modelo | conjunto de datos | exactitud | wall_clock_time | enlace |
|---|---|---|---|---|---|
| Imagenet | Mezclador-b/16 | cifar10 | 96.72% | 3.0h | tensorboard.dev |
| Imagenet | Mezclador-l/16 | cifar10 | 96.59% | 3.0h | tensorboard.dev |
| Imagenet-21k | Mezclador-b/16 | cifar10 | 96.82% | 9.6h | tensorboard.dev |
| Imagenet-21k | Mezclador-l/16 | cifar10 | 98.34% | 10.0h | tensorboard.dev |
Para obtener más detalles, consulte la publicación de blog de Google AI Lit: Agregar comprensión del idioma a los modelos de imagen, o lea el documento CVPR "Lit: Transferencia de disparo cero con ajuste de texto bloqueado" (https://arxiv.org/abs/2111.07991 ).
Publicamos un modelo de transformador B/16-base con una precisión de ceroshot de Imagenet de 72.1%, y un modelo L/16-Large con una precisión de ceroshot de Imagenet de 75.7%. Para obtener más detalles sobre estos modelos, consulte la tarjeta modelo LIT.
Proporcionamos una demostración en el navegador con pequeños codificadores de texto para uso interactivo (los modelos más pequeños incluso deben ejecutarse en un teléfono celular moderno):
https://google-research.github.io/Vision_transformer/lit/
Y finalmente un colab para usar los modelos JAX con codificadores de imagen y texto:
https://colab.research.google.com/github/google-research/Vision_transformer/blob/main/lit.ipynb
Tenga en cuenta que ninguno de los modelos anteriores admite entradas multilingües todavía, pero estamos trabajando en la publicación de dichos modelos y actualizaremos este repositorio una vez que estén disponibles.
Este repositorio solo contiene código de evaluación para modelos LIT. Puede encontrar el código de entrenamiento en el repositorio big_vision :
https://github.com/google-research/big_vision/tree/main/big_vision/configs/proj/image_text
Resultados de Zeroshot esperados de model_cards/lit.md (tenga en cuenta que la evaluación de ceroshot es ligeramente diferente de la evaluación simplificada en el colab):
| Modelo | B16b_2 | L16L |
|---|---|---|
| Imagenet cero-shot | 73.9% | 75.7% |
| Imagenet v2-shot cero | 65.1% | 66.6% |
| Cifar100 cero-shot | 79.0% | 80.5% |
| Pets37-shot cero | 83.3% | 83.3% |
| Resisc45 cero-shot | 25.3% | 25.6% |
| MS-Coco subtítulos de recuperación de imagen a texto | 51.6% | 48.5% |
| MS-Coco subtitulación de recuperación de texto a imagen | 31.8% | 31.1% |
Si bien por encima de los Colabs son bastante útiles para comenzar, generalmente querrá entrenar en una máquina más grande con aceleradores más potentes.
Puede usar los siguientes comandos para configurar una VM con GPU en Google Cloud:
# Set variables used by all commands below.
# Note that project must have accounting set up.
# For a list of zones with GPUs refer to
# https://cloud.google.com/compute/docs/gpus/gpu-regions-zones
PROJECT=my-awesome-gcp-project # Project must have billing enabled.
VM_NAME=vit-jax-vm-gpu
ZONE=europe-west4-b
# Below settings have been tested with this repository. You can choose other
# combinations of images & machines (e.g.), refer to the corresponding gcloud commands:
# gcloud compute images list --project ml-images
# gcloud compute machine-types list
# etc.
gcloud compute instances create $VM_NAME
--project= $PROJECT --zone= $ZONE
--image=c1-deeplearning-tf-2-5-cu110-v20210527-debian-10
--image-project=ml-images --machine-type=n1-standard-96
--scopes=cloud-platform,storage-full --boot-disk-size=256GB
--boot-disk-type=pd-ssd --metadata=install-nvidia-driver=True
--maintenance-policy=TERMINATE
--accelerator=type=nvidia-tesla-v100,count=8
# Connect to VM (after some minutes needed to setup & start the machine).
gcloud compute ssh --project $PROJECT --zone $ZONE $VM_NAME
# Stop the VM after use (only storage is billed for a stopped VM).
gcloud compute instances stop --project $PROJECT --zone $ZONE $VM_NAME
# Delete VM after use (this will also remove all data stored on VM).
gcloud compute instances delete --project $PROJECT --zone $ZONE $VM_NAMEAlternativamente, puede usar los siguientes comandos similares para configurar una VM en la nube con TPUS conectadas a ellos (los comandos a continuación copiados del tutorial de TPU):
PROJECT=my-awesome-gcp-project # Project must have billing enabled.
VM_NAME=vit-jax-vm-tpu
ZONE=europe-west4-a
# Required to set up service identity initially.
gcloud beta services identity create --service tpu.googleapis.com
# Create a VM with TPUs directly attached to it.
gcloud alpha compute tpus tpu-vm create $VM_NAME
--project= $PROJECT --zone= $ZONE
--accelerator-type v3-8
--version tpu-vm-base
# Connect to VM (after some minutes needed to setup & start the machine).
gcloud alpha compute tpus tpu-vm ssh --project $PROJECT --zone $ZONE $VM_NAME
# Stop the VM after use (only storage is billed for a stopped VM).
gcloud alpha compute tpus tpu-vm stop --project $PROJECT --zone $ZONE $VM_NAME
# Delete VM after use (this will also remove all data stored on VM).
gcloud alpha compute tpus tpu-vm delete --project $PROJECT --zone $ZONE $VM_NAME Y luego obtenga el repositorio y las dependencias de instalación (incluido jaxlib con soporte de TPU) como de costumbre:
git clone --depth=1 --branch=master https://github.com/google-research/vision_transformer
cd vision_transformer
# optional: install virtualenv
pip3 install virtualenv
python3 -m virtualenv env
. env/bin/activateSi está conectado a una VM con GPU conectadas, instale Jax y otras dependencias con el siguiente comando:
pip install -r vit_jax/requirements.txtSi está conectado a una VM con TPUS conectado, instale Jax y otras dependencias con el siguiente comando:
pip install -r vit_jax/requirements-tpu.txtInstale Flaxformer, siga las instrucciones proporcionadas en el repositorio correspondiente vinculado aquí.
Para GPU y TPU, verifique que Jax pueda conectarse a aceleradores adjuntos con el comando:
python -c ' import jax; print(jax.devices()) 'Y finalmente ejecute uno de los comandos mencionados en la sección ajustando un modelo.
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
@article{tolstikhin2021mixer,
title={MLP-Mixer: An all-MLP Architecture for Vision},
author={Tolstikhin, Ilya and Houlsby, Neil and Kolesnikov, Alexander and Beyer, Lucas and Zhai, Xiaohua and Unterthiner, Thomas and Yung, Jessica and Steiner, Andreas and Keysers, Daniel and Uszkoreit, Jakob and Lucic, Mario and Dosovitskiy, Alexey},
journal={arXiv preprint arXiv:2105.01601},
year={2021}
}
@article{steiner2021augreg,
title={How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers},
author={Steiner, Andreas and Kolesnikov, Alexander and and Zhai, Xiaohua and Wightman, Ross and Uszkoreit, Jakob and Beyer, Lucas},
journal={arXiv preprint arXiv:2106.10270},
year={2021}
}
@article{chen2021outperform,
title={When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations},
author={Chen, Xiangning and Hsieh, Cho-Jui and Gong, Boqing},
journal={arXiv preprint arXiv:2106.01548},
year={2021},
}
@article{zhuang2022gsam,
title={Surrogate Gap Minimization Improves Sharpness-Aware Training},
author={Zhuang, Juntang and Gong, Boqing and Yuan, Liangzhe and Cui, Yin and Adam, Hartwig and Dvornek, Nicha and Tatikonda, Sekhar and Duncan, James and Liu, Ting},
journal={ICLR},
year={2022},
}
@article{zhai2022lit,
title={LiT: Zero-Shot Transfer with Locked-image Text Tuning},
author={Zhai, Xiaohua and Wang, Xiao and Mustafa, Basil and Steiner, Andreas and Keysers, Daniel and Kolesnikov, Alexander and Beyer, Lucas},
journal={CVPR},
year={2022}
}
En orden cronológico inverso:
2022-08-18: Se agregó el modelo Lit-B16B_2 que fue entrenado para 60k pasos (Lit_B16b: 30K) sin cabeza lineal en el lado de la imagen (LIT_B16B: 768) y tiene un mejor rendimiento.
2022-06-09: Se agregaron los modelos VIT y mezcladores entrenados desde cero usando GSAM en Imagenet sin fuertes aumentos de datos. Los VIT resultantes superan a los de tamaños similares capacitados con Adamw Optimizer o el algoritmo SAM original, o con fuertes aumentos de datos.
2022-04-14: Modelos agregados y Colab para modelos Lit.
2021-07-29: Modelos Augreg Augreg agregados (3 puntos de control aguas arriba y adaptaciones con resolución = 224).
2021-07-02: Se agregó el papel "cuando los transformadores de visión superan los resnets ..."
2021-07-02: Se agregaron puntos de control Optimizados de VIT y MLP-Mixer de SAM (minimización de nitidez).
2021-06-20: Agregué el papel "¿Cómo entrenar su vitio? ..." y un nuevo colab para explorar los puntos de control> 50K pre-entrenados y ajustados mencionados en el documento.
2021-06-18: Este repositorio se reescribió para usar la API de lino de lino y ml_collections.ConfigDict para la configuración.
2021-05-19: Con la publicación del documento "¿Cómo entrenar su Vit? , y fino en Imagenet, Pets37, Kitti-Distance, Cifar-100 y Resisc45. ¡Mira vit_jax_augreg.ipynb para navegar este tesoro de modelos! Por ejemplo, puede usar ese Colab para obtener los nombres de archivo de los puntos de control recomendados previamente capacitados y ajustados de la columna i21k_300 de la Tabla 3 en el documento.
2020-12-01: Se agregó el modelo híbrido R50+VIT-B/16 (VIT-B/16 en la parte superior de una columna vertebral resnet-50). Cuando se envía en exceso en ImageNet21k, este modelo logra casi el rendimiento del modelo L/16 con menos de la mitad del costo de ficción computacional. Tenga en cuenta que "R50" está algo modificado para la variante B/16: el resnet-50 original tiene [3,4,6,3] bloques, cada uno reduciendo la resolución de la imagen por un factor de dos. En combinación con el tallo de resnet, esto daría como resultado una reducción de 32X, por lo que incluso con un tamaño de parche de (1,1) la variante VIT-B/16 ya no se puede realizar. Por esta razón, en su lugar usamos [3,4,9] bloques para la variante R50+B/16.
2020-11-09: Se agregó el modelo VIT-L/16.
2020-10-29: los modelos VIT-B/16 y VIT-L/16 agregados previamente en ImageNet-21K y luego ajustados en ImageNet a la resolución 224x224 (en lugar del valor predeterminado 384x384). Estos modelos tienen el sufijo "-224" en su nombre. Se espera que alcancen el 81.2% y el 82.7% de las precisiones Top-1 respectivamente.
Lanzamiento de código abierto preparado por Andreas Steiner.
Nota: Este repositorio fue bifurcado y modificado de Google-Research/Big_Transfer.
Este no es un producto oficial de Google.


