Awesome LLM 3D
1.0.0
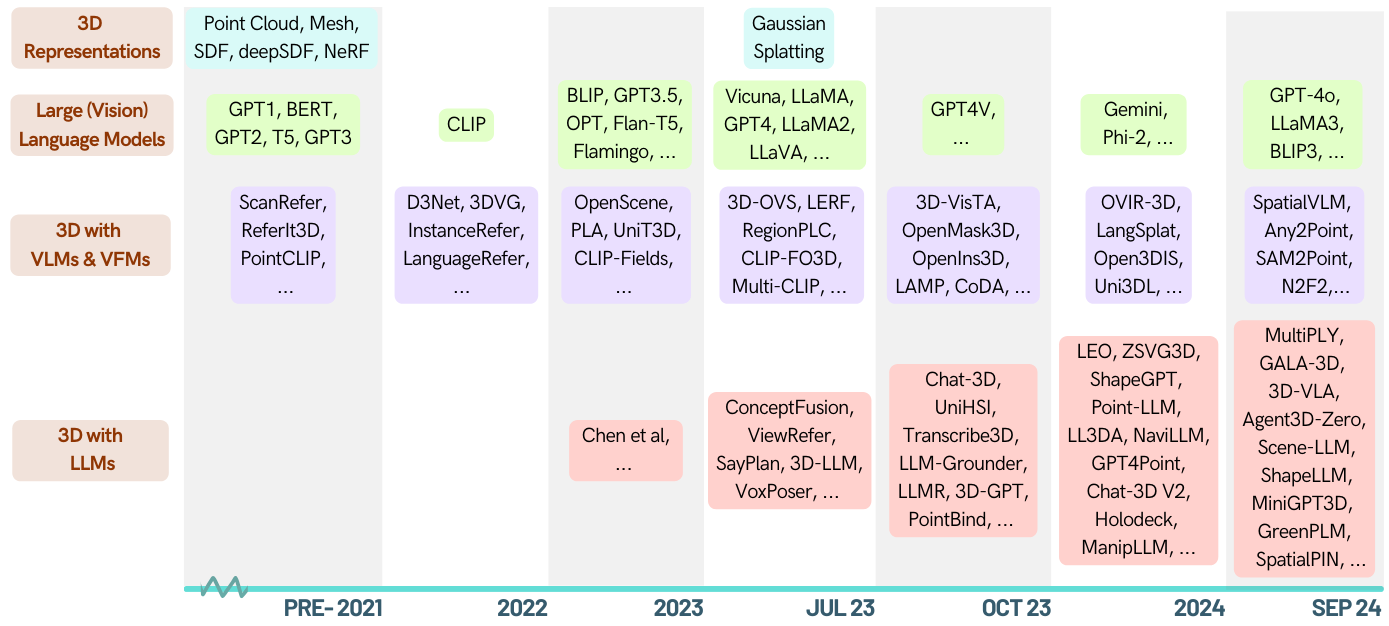
Aquí hay una lista curada de documentos sobre tareas relacionadas con 3D empoderadas por modelos de idiomas grandes (LLM). Contiene varias tareas que incluyen la comprensión 3D, el razonamiento, la generación y los agentes encarnados. Además, incluimos otros modelos de base (Clip, SAM) para la imagen completa de esta área.
Este es un repositorio activo, puede observar seguir los últimos avances. Si lo encuentra útil, por favor, estrella este repositorio y cita el papel.
[2024-05-16]? Consulte el primer documento de encuesta en el dominio 3D-LLM: cuando LLMS entre al mundo 3D: una encuesta y un metaanálisis de tareas 3D a través de modelos de idiomas grandes multimodales
[2024-01-06] Runsen Xu agregó información cronológica y Xianzheng MA lo reorganizó en orden ZA para mejorar los últimos avances.
[2023-12-16] Xianzheng MA y Yash Bhalgat seleccionaron esta lista y publicaron la primera versión;
Impresionante-llm-3d
Entendimiento 3D (LLM)
Entendimiento 3D (otros modelos de base)
Razonamiento 3D
Generación 3D
Agente 3D encarnado
Puntos de referencia 3D
Que contribuye
| Fecha | Palabras clave | Instituto (primero) | Papel | Publicación | Otros |
|---|---|---|---|---|---|
| 2024-10-12 | Situación3d | Uiuc | La conciencia situacional es importante en el razonamiento del lenguaje de visión 3D | CVPR '24 | proyecto |
| 2024-09-28 | Llava-3d | HKU | Llava-3D: una vía simple pero efectiva para empoderar a los LMM con conciencia 3D | Arxiv | proyecto |
| 2024-09-08 | MSR3D | Bigái | Razonamiento situado multimodal en escenas 3D | Neurips '24 | proyecto |
| 2024-08-28 | Verde | Ausencia | Más texto, menos punto: hacia la comprensión de la lengua puntual de los datos en 3D | Arxiv | github |
| 2024-06-17 | Llana | Unibo | Llana: Idioma grande y asistente de Nerf | Neurips '24 | proyecto |
| 2024-06-07 | Espacial | Oxford | Spacialpin: Mejora de las capacidades de razonamiento espacial de los modelos en idioma de visión a través de la solicitud e interactuación de antecedentes 3D | Neurips '24 | proyecto |
| 2024-06-03 | Espacialrgpt | UCSD | SpacialRGPT: razonamiento espacial fundamentado en modelos de lenguaje de visión | Neurips '24 | github |
| 2024-05-02 | Minigt-3d | Ausencia | Minigpt-3D: alineando eficientemente nubes de puntos 3D con modelos de idiomas grandes que usan priors 2D | ACM MM '24 | proyecto |
| 2024-02-27 | Shapellm | Xjtu | Shapellm: comprensión de objetos 3D universales para la interacción incorporada | Arxiv | proyecto |
| 2024-01-22 | Espacialvlm | Google DeepMind | SpatialVLM: modelos en idioma de visión con capacidades de razonamiento espacial | CVPR '24 | proyecto |
| 2023-12-21 | Lidar-llm | Pku | LiDAR-LLM: Explorando el potencial de los modelos de idiomas grandes para la comprensión 3D LiDAR | Arxiv | proyecto |
| 2023-12-15 | 3DAP | Shanghai AI Labor | 3DAXIESPROMPTS: desatando las capacidades de tareas espaciales 3D de GPT-4V | Arxiv | proyecto |
| 2023-12-13 | Escena de chat | Zju | Escena de chat: puente de escena 3D y modelos de idiomas grandes con identificadores de objetos | Neurips '24 | github |
| 2023-12-5 | GPT4Point | HKU | GPT4Point: un marco unificado para la comprensión y la generación del lenguaje puntual | Arxiv | github |
| 2023-11-30 | LL3DA | Universidad de Fudan | LL3DA: ajuste de instrucciones interactivas visuales para la comprensión, el razonamiento y la planificación Omni-3D | Arxiv | github |
| 2023-11-26 | Zsvg3d | Cuhk (SZ) | Programación visual para la base visual de Vocabulario Abierto de Cero-Shot | Arxiv | proyecto |
| 2023-11-18 | LEÓN | Bigái | Un agente generalista incorporado en el mundo 3D | Arxiv | github |
| 2023-10-14 | Jm3d-llm | Universidad de Xiamen | JM3D y JM3D-LLM: Elevación de la representación 3D con señales multimodales conjuntas | ACM MM '23 | github |
| 2023-10-10 | Uni3d | Baai | UNI3D: Explorando la representación 3D unificada a escala | ICLR '24 | proyecto |
| 2023-9-27 | - | Kausto | Correspondencia de forma 3D de disparo cero | Siggraph Asia '23 | - |
| 2023-9-21 | LLM-Grounder | U-Mich | LLM-Grounder: Vocabulario abierto 3D Visual conectación a tierra con un modelo de lenguaje grande como agente | ICRA '24 | github |
| 2023-9-1 | Unión a punto | Cuhk | Point-Bind & Point-LLM: Alineación de la nube de puntos con multimodalidad para la comprensión 3D, la generación y la instrucción siguiendo | Arxiv | github |
| 2023-8-31 | Punto | Cuhk | Pointllm: Empoderar modelos de idiomas grandes para comprender las nubes de puntos | ECCV '24 | github |
| 2023-8-17 | Chat-3d | Zju | CHAT-3D: Tune de lenguaje grande de eficiencia de datos para el diálogo universal de escenas 3D | Arxiv | github |
| 2023-8-8 | Vista 3D | Bigái | 3D-Vista: transformador previamente entrenado para visión 3D y alineación de texto | ICCV '23 | github |
| 2023-7-24 | 3D-LLM | UCLA | 3D-LLM: inyectar el mundo 3D en modelos de idiomas grandes | Neurips '23 | github |
| 2023-3-29 | Vista | Cuhk | ViewRefer: comprenda el conocimiento de la visión múltiple para la puesta a tierra visual 3D | ICCV '23 | github |
| 2022-9-12 | - | MIT | Aprovechando modelos de lenguaje grandes (visuales) para la comprensión de la escena 3D robot | Arxiv | github |
| IDENTIFICACIÓN | Palabras clave | Instituto (primero) | Papel | Publicación | Otros |
|---|---|---|---|---|---|
| 2024-10-12 | Léxico3d | Uiuc | LEXICON3D: Modelos de Fundación Visual para la comprensión de la escena 3D compleja | Neurips '24 | proyecto |
| 2024-10-07 | Escena diff2 | CMU | Segmentación semántica 3D de vocabulario abierto con modelos de difusión de texto a imagen | ECCV 2024 | proyecto |
| 2024-04-07 | Any2point | Shanghai AI Labor | Any2Point: Empoderar modelos grandes de modalidad para una comprensión 3D eficiente | ECCV 2024 | github |
| 2024-03-16 | N2F2 | Oxford-vgg | N2F2: Comprensión de la escena jerárquica con campos de características neuronales anidadas | Arxiv | - |
| 2023-12-17 | Sai3d | Pku | SAI3D: segmento cualquier instancia en escenas 3D | Arxiv | proyecto |
| 2023-12-17 | Open3dis | Vinai | Open3DIS: segmentación de instancia 3D-Vocabulario abierta con orientación de máscara 2D | Arxiv | proyecto |
| 2023-11-6 | Ovir-3d | Universidad de Rutgers | OVIR-3D: recuperación de instancia 3D-Vocabulario abierta sin capacitación en datos 3D | Corl '23 | github |
| 2023-10-29 | Openmask3d | ETH | OpenMask3D: segmentación de instancias 3D de Vocabulario abierto | Neurips '23 | proyecto |
| 2023-10-5 | Fusión abierta | - | Fusión abierta: mapeo 3D de vocabulario abierto en tiempo real y representación de escena consultable | Arxiv | github |
| 2023-9-22 | Ov-3ddet | Hkust | Coda: descubrimiento de cajas novedosas colaborativas y alineación intermodal para la detección de objetos 3D de Vocabulario Abierto | Neurips '23 | github |
| 2023-9-19 | LÁMPARA | - | Desde el lenguaje hasta los mundos 3D: adaptación del modelo de idioma para la percepción de la nube de puntos | Revisión de abierto | - |
| 2023-9-15 | Abierto | - | OpenNerf: Segmentación de escena neuronal en 3D Open con características de píxel y vistas novedosas renderizadas | Revisión de abierto | github |
| 2023-9-1 | Openins3D | Cambridge | OpenIns3D: Snap y busque la segmentación de instancias de Vocabulario Open 3D | Arxiv | proyecto |
| 2023-6-7 | Ascensor contrastante | Oxford-vgg | Levantamiento de contraste: segmentación de instancia de objeto 3D por fusión contrastante lenta y rápida | Neurips '23 | github |
| 2023-6-4 | Múltiple | ETH | Clip múltiple: pre-entrenamiento de lenguaje de visión contrastante para tareas de respuesta a preguntas en escenas 3D | Arxiv | - |
| 2023-5-23 | 3D-OVS | NTU | Segmentación de vocabulario 3D débilmente supervisada | Neurips '23 | github |
| 2023-5-21 | VL campos | Universidad de Edimburgo | Campos VL: hacia representaciones espaciales implícitas neuronales con tierra en el lenguaje | ICRA '23 | proyecto |
| 2023-5-8 | Clip-fo3d | Universidad de Tsinghua | Clip-FO3D: Learning Representaciones de escena 3D de World 3D gratuitas de 2d Dense Clip | ICCVW '23 | - |
| 2023-4-12 | 3D-VQA | ETH | Prerreineamiento de la visión de clip-Guiado para la respuesta de las preguntas en escenas 3D | CVPRW '23 | github |
| 2023-4-3 | Región | HKU | RegionPlc: aprendizaje de contrastes de puntuación regional para la comprensión de la escena 3D del mundo abierto | Arxiv | proyecto |
| 2023-3-20 | CG3D | Jhu | Clip Goes 3D: Aprovechando el ajuste de inmediato para el reconocimiento 3D en el lenguaje. | Arxiv | github |
| 2023-3-16 | Lerfo | UC Berkeley | Lerf: Lenguaje Campos de radiación integrados | ICCV '23 | github |
| 2023-2-14 | Concepto de concepto | MIT | Conceptfusion: mapeo 3D multimodal abierto | RSS '23 | proyecto |
| 2023-1-12 | Escena clip2 | HKU | Clip2Scene: hacia la comprensión de la escena 3D eficiente en la etiqueta por clip | CVPR '23 | github |
| 2022-12-1 | Unidad 3D | Tum | Unidad3D: un transformador unificado para subtítulos densos en 3D y conexión a tierra visual | ICCV '23 | github |
| 2022-11-29 | Estampado | HKU | PLA: comprensión de la escena 3D del Vocabulario Abierto impulsado por el lenguaje | CVPR '23 | github |
| 2022-11-28 | Openscena | Ethz | OpenScene: comprensión de la escena 3D con vocabularios abiertos | CVPR '23 | github |
| 2022-10-11 | Campos de clip | NYU | Campos de clip: campos semánticos débilmente supervisados para la memoria robótica | Arxiv | proyecto |
| 2022-7-23 | Abstracción semántica | Columbia | Abstracción semántica: comprensión de la escena 3D del mundo abierto de modelos 2D en idioma de visión | Corl '22 | proyecto |
| 2022-4-26 | Scannet200 | Tum | Segmentación semántica 3D interiores con tierra en el idioma en la naturaleza | ECCV '22 | proyecto |
| Fecha | Palabras clave | Instituto (primero) | Papel | Publicación | Otros |
|---|---|---|---|---|---|
| 2023-5-20 | 3D-CLR | UCLA | Aprendizaje de concepto 3D y razonamiento de imágenes de visión múltiple | CVPR '23 | github |
| - | Transcribir3d | TTI, Chicago | Transcribe3d: Grounding LLMS utilizando información transcrita para un razonamiento referencial 3D con finete de autocorrección | Corl '23 | github |
| Fecha | Palabras clave | Instituto | Papel | Publicación | Otros |
|---|---|---|---|---|---|
| 2023-11-29 | Shapgpt | Universidad de Fudan | SapeGPT: generación de forma 3D con un modelo de lenguaje multimodal unificado | Arxiv | github |
| 2023-11-27 | Malla | Tum | MeshGPT: Generación de mallas triangulares con transformadores de decodificadores | Arxiv | proyecto |
| 2023-10-19 | 3D-GPT | Anu | 3D-GPT: modelado 3D de procedimiento con modelos de idiomas grandes | Arxiv | github |
| 2023-9-21 | LLMR | MIT | LLMR: Involucentación en tiempo real de mundos interactivos utilizando modelos de idiomas grandes | Arxiv | - |
| 2023-9-20 | Dreamllm | Megvii | Dreamllm: Comprensión y creación multimodal sinérgicas | Arxiv | github |
| 2023-4-1 | Chatavatar | Deemos Tech | Dreamface: Generación progresiva de caras 3D animables bajo la guía de texto | ACM Tog | sitio web |
| Fecha | Palabras clave | Instituto | Papel | Publicación | Otros |
|---|---|---|---|---|---|
| 2024-01-22 | Espacialvlm | Profundo | SpatialVLM: modelos en idioma de visión con capacidades de razonamiento espacial | CVPR '24 | proyecto |
| 2023-11-27 | DOBB-E | NYU | Al traer robots a casa | Arxiv | github |
| 2023-11-26 | Steve | Zju | Ver y pensar: agente incorporado en entorno virtual | Arxiv | github |
| 2023-11-18 | LEÓN | Bigái | Un agente generalista incorporado en el mundo 3D | Arxiv | github |
| 2023-9-14 | Unihsi | Shanghai AI Labor | Interacción unificada de escena humana a través de la cadena de contactos provocada | Arxiv | github |
| 2023-7-28 | RT-2 | Google-Depermind | RT-2: los modelos de acción-lenguaje de visión transfieren el conocimiento web al control robótico | Arxiv | github |
| 2023-7-12 | Sayplan | Centro QUT para robótica | Sayplan: base en base a modelos de idiomas grandes que utilizan gráficos de escena 3D para planificación de tareas de robot escalable | Corl '23 | github |
| 2023-7-12 | Voxposer | Stanford | Voxposer: mapas de valor 3D componibles para manipulación robótica con modelos de idiomas | Arxiv | github |
| 2022-12-13 | RT-1 | RT-1: Transformador de robótica para el control del mundo real a escala | Arxiv | github | |
| 2022-12-8 | LLM-Planner | La Universidad Estatal de Ohio | LLM-Planner: Planificación de pocos disparos para agentes incorporados con modelos de idiomas grandes | ICCV '23 | github |
| 2022-10-11 | Campos de clip | Nyu, meta | Campos de clip: campos semánticos débilmente supervisados para la memoria robótica | RSS '23 | github |
| 2022-09-20 | Nlmap-saycan | Representaciones de escenas consultables de consultas de vocabulario abierto para la planificación del mundo real | ICRA '23 | github |
| Fecha | Palabras clave | Instituto | Papel | Publicación | Otros |
|---|---|---|---|---|---|
| 2024-09-08 | MSQA / MSNN | Bigái | Razonamiento situado multimodal en escenas 3D | Neurips '24 | proyecto |
| 2024-06-10 | 3D-Grand / 3D Pope | Umich | 3D-Grand: un conjunto de datos a escala de un millón para 3D-LLMS con mejor conexión a tierra y menos alucinación | Arxiv | proyecto |
| 2024-06-03 | Bancos espaciales | UCSD | SpacialRGPT: razonamiento espacial fundamentado en modelos de lenguaje de visión | Neurips '24 | github |
| 2024-1-18 | Inevenido | Bigái | ScenEverse: Escala de aprendizaje en idioma 3D para la comprensión de la escena fundamentada | Arxiv | github |
| 2023-12-26 | Escenario | Shanghai AI Labor | EncarodiedScan: una suite de percepción 3D multimodal holística hacia AI incorporada | Arxiv | github |
| 2023-12-17 | M3dbench | Universidad de Fudan | M3dbench: instruyamos a modelos grandes con indicaciones 3D multimodales | Arxiv | github |
| 2023-11-29 | - | Profundo | Evaluación de VLM para la anotación de objetos 3D basados en puntaje de puntaje | Arxiv | github |
| 2023-09-14 | Coherencia cruzada | Unibo | Mirando palabras y puntos con atención: un punto de referencia para la coherencia de texto a forma | ICCV '23 | github |
| 2022-10-14 | Sqa3d | Bigái | SQA3D: Pregunta situada respondiendo en escenas 3D | ICLR '23 | github |
| 2021-12-20 | Escaneo | Riken AIP | Scanqa: 3D Pregunta Respondiendo para la comprensión de la escena espacial | CVPR '23 | github |
| 2020-12-3 | Escanear | Tum | SCAN2CAP: subtítulos densos con contexto en las escaneos RGB-D | CVPR '21 | github |
| 2020-8-23 | Referir3D | Stanford | Referit3d: Oyentes neuronales para identificación de objetos 3D de grano fino en escenas del mundo real | ECCV '20 | github |
| 2019-12-18 | Escanear | Tum | ScanRefer: localización de objetos 3D en escaneos RGB-D usando lenguaje natural | ECCV '20 | github |
¡Tus contribuciones siempre son bienvenidas!
Mantendré abiertas algunas solicitudes de extracción si no estoy seguro de si son increíbles para 3D LLM, ¿podría votar por ellas agregando? a ellos.
Si tiene alguna pregunta sobre esta lista obstinada, póngase en contacto en [email protected] o WeChat ID: MXZ1997112.
Si encuentra útil este repositorio, considere citar este documento:
@misc{ma2024llmsstep3dworld,
title={When LLMs step into the 3D World: A Survey and Meta-Analysis of 3D Tasks via Multi-modal Large Language Models},
author={Xianzheng Ma and Yash Bhalgat and Brandon Smart and Shuai Chen and Xinghui Li and Jian Ding and Jindong Gu and Dave Zhenyu Chen and Songyou Peng and Jia-Wang Bian and Philip H Torr and Marc Pollefeys and Matthias Nießner and Ian D Reid and Angel X. Chang and Iro Laina and Victor Adrian Prisacariu},
year={2024},
journal={arXiv preprint arXiv:2405.10255},
}Este repositorio está inspirado en Awesome-LLM


