LLaMA Omni
1.0.0
Autores: Qingkai Fang, Shoutao Guo, Yan Zhou, Zhengrui MA, Shaolei Zhang, Yang Feng*
Llama-AMNI es un modelo de habla y lenguaje basado en Llama-3.1-8b-Instructo. Apoya las interacciones del habla de baja latencia y alta calidad, generando simultáneamente las respuestas de texto y del habla basadas en las instrucciones del habla.
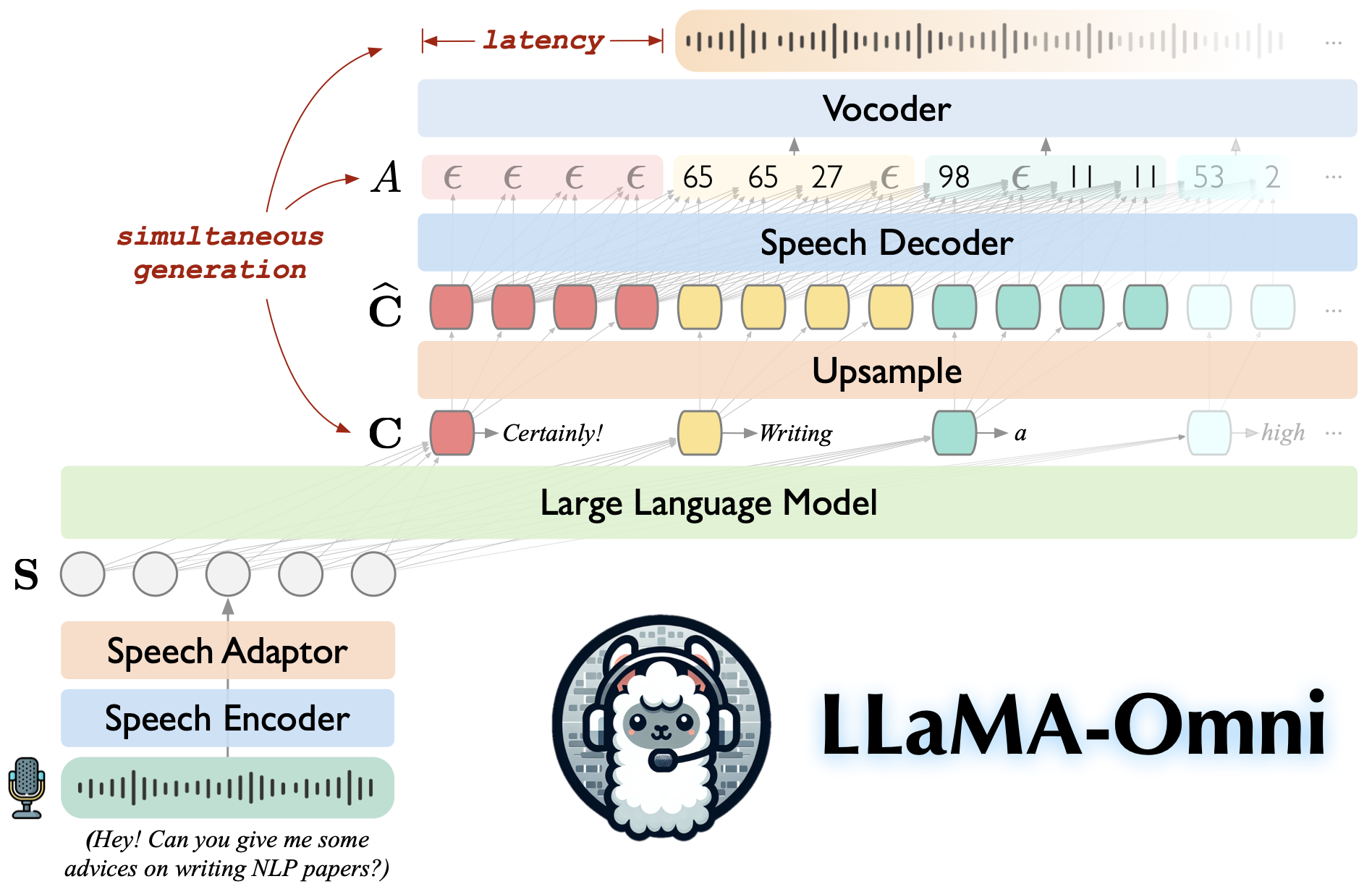
Construido en LLAMA-3.1-8B-INSTRUST, asegurando respuestas de alta calidad.
Interacción del habla de baja latencia con una latencia tan baja como 226 ms.
Generación simultánea de respuestas de texto y habla.
♻️ entrenado en menos de 3 días usando solo 4 GPU.
Clon este repositorio.
Git clon https://github.com/ictnlp/llama-omnicd llama-oMni
Instalar paquetes.
conda create -n llama -oMni python = 3.10 conda activar llama-omni PIP Instale PIP == 24.0 PIP install -e.
Instalar fairseq .
Git clone https://github.com/pytorch/fairseqcd fairseq PIP install -e. --No-construcción-isolación
Instale flash-attention .
PIP Instalar flash-Attn-No-build-isolation
Descargue el modelo Llama-3.1-8B-Omni de? Huggingface.
Descargue el modelo Whisper-large-v3 .
IMPORTA DE IMPORTA
modelo = whisper.load_model ("grande-v3", download_root = "modelos/speech_encoder/")Descargue el Vocoder Hifi-Gan basado en la unidad.
wget https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/vocoder/code_hifigan/mhubert_vp_en_es_fr_it3_400k_layer11_km1000_lj/g_00500000 -p Vocoder// wget https://dl.fbaipublicfiles.com/fairseq/speech_to_speech/vocoder/code_hifigan/mhubert_vp_en_es_fr_it3_400k_layer11_km1000_lj/config.json -p Vocoder//
Iniciar un controlador.
python -m omni_speech.serve.controller --host 0.0.0.0 --port 10000
Iniciar un servidor web de Gradio.
python -m omni_speech.serve.gradio_web_server --controller http: // localhost: 10000 --port 8000 -model-list-Mode recoad-Vocoder Vocoder/G_00500000-Vocoder-CFG Vocoder/config.json
Lanzar un trabajador modelo.
python -m omni_speech.serve.model_worker --host 0.0.0.0 --controller http: // localhost: 10000 --port 40000 --worker http: // localhost: 40000--Model-path Llama-3.1-8b-MEMNI --Modelo-Name Llama-3.1-8B-OMNI--S2S
Visite http: // localhost: 8000/e interactúe con Llama-3.1-8b-OMNI!
Nota: Debido a la inestabilidad de la transmisión de reproducción de audio en Gradio, solo hemos implementado la síntesis de audio de transmisión sin habilitar la autoplay. Si tiene una buena solución, no dude en enviar un PR. ¡Gracias!
Para ejecutar la inferencia localmente, organice los archivos de instrucciones de voz de acuerdo con el formato en el directorio omni_speech/infer/examples , luego consulte el siguiente script.
bash omni_speech/infer/run.sh omni_speech/infer/ejemplos
Nuestro código se publica bajo la licencia Apache-2.0. Nuestro modelo está destinado solo a fines de investigación académica y no puede usarse para fines comerciales.
Usted es libre de usar, modificar y distribuir este modelo en entornos académicos, siempre que se cumplan las siguientes condiciones:
Uso no comercial : el modelo no se puede utilizar para ningún fin de comercio.
Cita : si usa este modelo en su investigación, cite el trabajo original.
Para cualquier consulta de uso comercial o para obtener una licencia comercial, comuníquese con [email protected] .
Llava: la base de código en la que construimos.
SLAM-LLM: Tomamos prestado algún código sobre el codificador del habla y el adaptador de habla.
Si tiene alguna pregunta, no dude en enviar un problema o comunicarse con [email protected] .
Si nuestro trabajo es útil para usted, cite como:
@article{fang-etal-2024-llama-omni,
title={LLaMA-Omni: Seamless Speech Interaction with Large Language Models},
author={Fang, Qingkai and Guo, Shoutao and Zhou, Yan and Ma, Zhengrui and Zhang, Shaolei and Feng, Yang},
journal={arXiv preprint arXiv:2409.06666},
year={2024}
} 

