streaming
v0.9.1
Construimos StreamingDataSet para hacer capacitación en grandes conjuntos de datos desde el almacenamiento en la nube lo más rápido, barato y escalable posible.
Está especialmente diseñado para capacitación distribuida de múltiples nodos para modelos grandes, maximizando las garantías de corrección, el rendimiento y la facilidad de uso. Ahora, puede entrenar de manera eficiente en cualquier lugar, independientemente de la ubicación de su datos de entrenamiento. Simplemente transmita los datos que necesita, cuando lo necesite. Para obtener más información sobre por qué construimos StreamingDataset, lea nuestro blog de anuncios.
StreamingDataSet es compatible con cualquier tipo de datos, incluidas imágenes, texto, video y datos multimodales .
Con soporte para los principales proveedores de almacenamiento en la nube (AWS, OCI, GCS, Azure, Databricks y cualquier almacén de objetos compatible con S3 como CloudFlare R2, CoreWeave, Backblaze B2, etc.) y diseñado como un reemplazo de pytorChateAdataSet , StreamingDataset se integra perfectamente en sus flujos de trabajo de capacitación existentes.

La transmisión se puede instalar con pip :
PIP Instale la transmisión de mosaicml
Convierta su conjunto de datos sin procesar en uno de nuestros formatos de transmisión compatibles:
Formato MDS (Mosaic Data Shard) que puede codificar y decodificar cualquier objeto Python
CSV / TSV
Jsonl
Importar Numpy como NPFrom PIL Image Imagen de transmisión de la transmisión MdsWriter# Directorio local o remoto en el que almacenar los archivos de salida comprimidos Data_dir = 'Rath-to-DataSet'# Un diccionario Mapeo de campos de entrada a sus datos typescolumns = {'Image': 'jpeg' ' , 'class': 'int'}# compresión de fragmentos, si anyompression = 'zstd'# guarde las muestras como fragmentos utilizando mdswriterwith mdswriter (out = data_dir, columns = columns, compresión = compresión) como fuera: para i en rango (10000 (10000 (10000 (10000 ): muestra = {'imagen': image.fromArray (np.random.randint (0, 256, (32, 32, 3), np.uint8)), 'class': np.random.randint (10),
} out.write (muestra)Cargue su conjunto de datos de transmisión al almacenamiento en la nube de su elección (AWS, OCI o GCP). A continuación se muestra un ejemplo de cargar un directorio a un cubo S3 utilizando la AWS CLI.
$ AWS S3 CP-RECURSIVO PATH TO-DATASET S3: // my-bucket/rath to-dataset
Desde tortch.utils.data import dataLoaderFrom streaming import streamingDataset# ruta remota donde el conjunto de datos completo se siente persistentemente storedremote = 's3: // my-bucket/rath-to-dataset'# Dir de trabajo local donde el conjunto de datos se almacena en caché durante la operación = '/tmp /ratt-to-dataset '# Crear datos de transmisión DataSetDataSet = streamingDataSet (local = local, remoto = remoto, shuffle = true)# Veamos lo que está en la muestra# 1337 ... sample = dataSet [1337] img = muestra [' imagen ['imagen '] cls = sample [' class ']# Crear pytorch dataLoaderDataloader = dataLoader (DataSet)
Se puede encontrar guías iniciales, ejemplos, referencias de API y otra información útil en nuestros documentos.
Tenemos tutoriales de extremo a extremo para capacitar a un modelo en:
Cifar-10
Facesintética
Sintética
También tenemos código de inicio para los siguientes conjuntos de datos populares, que se pueden encontrar en el directorio streaming :
| Conjunto de datos | Tarea | Leer | Escribir |
|---|---|---|---|
| Laion-400m | Texto e imagen | Leer | Escribir |
| Vía web | Texto y video | Leer | Escribir |
| C4 | Texto | Leer | Escribir |
| Enwiki | Texto | Leer | Escribir |
| Montón | Texto | Leer | Escribir |
| ADE20K | Segmentación de imágenes | Leer | Escribir |
| Cifar10 | Clasificación de imágenes | Leer | Escribir |
| PALMA DE COCO | Clasificación de imágenes | Leer | Escribir |
| Imagenet | Clasificación de imágenes | Leer | Escribir |
Para comenzar a entrenar en estos conjuntos de datos:
Convierta los datos sin procesar en formato .mds utilizando el script correspondiente del directorio convert .
Por ejemplo:
$ python -m streaming.multimodal.convert.webvid - -in <csv archivo> --out <directorio de salida MDS>
Importar clase de conjunto de datos para comenzar a capacitar el modelo.
desde streaming.multimodal import streaminginsidewebviddataset = streamingInsideWebVid (local = local, remoto = remoto, shuffle = true)
Experimente fácilmente con mezclas de conjunto de datos con Stream . El muestreo del conjunto de datos se puede controlar en términos relativos (proporción) o absolutos (repetir o muestras). Durante la transmisión, los diferentes conjuntos de datos se transmiten, se barajan y se mezclan sin problemas.
# mix C4, github code, and internal datasets streams = [ Stream(remote='s3://datasets/c4', proportion=0.4), Stream(remote='s3://datasets/github', proportion=0.1), Stream(remote='gcs://datasets/my_internal', proportion=0.5), ] dataset = StreamingDataset( streams=streams, samples_per_epoch=1e8, )
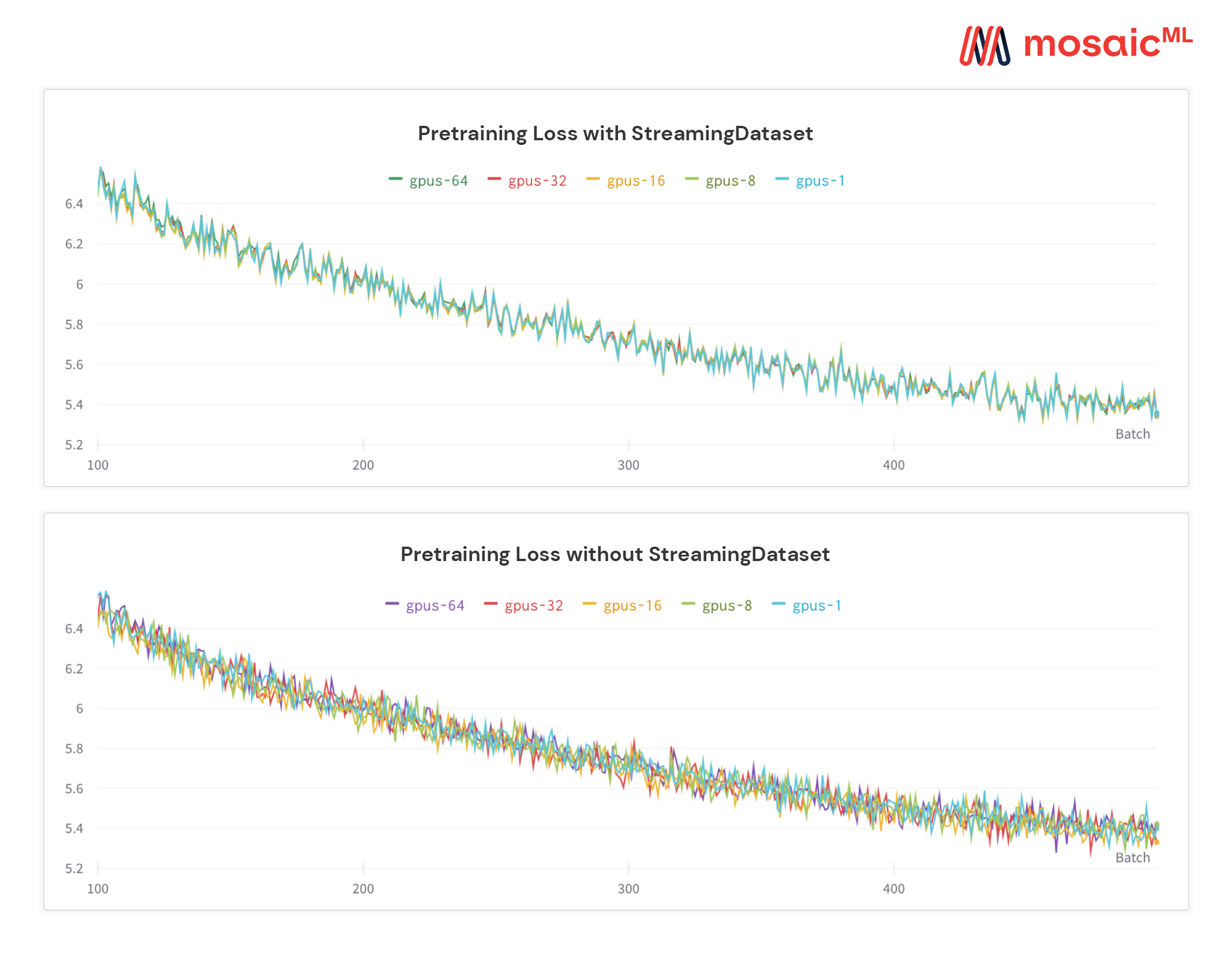
Una característica única de nuestra solución: las muestras están en el mismo orden, independientemente del número de GPU, nodos o trabajadores de la CPU. Esto hace que sea más fácil:
Reproducir y depurar el entrenamiento y las picos de pérdidas
Cargar un punto de control entrenado en 64 GPU y depurar en 8 GPU con reproducibilidad
Consulte la figura a continuación: capacitar un modelo en 1, 8, 16, 32 o 64 GPUS produce exactamente la misma curva de pérdida (¡hasta las limitaciones de las matemáticas de punto flotante!)
Puede ser costoso, y molesto, esperar a que su trabajo se reanude mientras su dataLoader gira después de una falla de hardware o una punta de pérdida. Gracias a nuestro pedido de muestras deterministas, StreamingDataset le permite reanudar el entrenamiento en segundos, no horas, en medio de una larga carrera de entrenamiento.
Minimizar la latencia de reanudación puede ahorrar miles de dólares en tarifas de salida y tiempo de cálculo de GPU inactivo en comparación con las soluciones existentes.
Nuestro formato MDS reduce el trabajo extraño al hueso, lo que resulta en una latencia de muestra ultra baja y un mayor rendimiento en comparación con las alternativas para las cargas de trabajo de los cuellos de botella por el dataloader.
| Herramienta | Rendimiento |
|---|---|
| Streamingdataset | ~ 19000 img/seg |
| Perforador de imágenes | ~ 18000 IMG/seg |
| WebdataSet | ~ 16000 IMG/seg |
Los resultados que se muestran son del entrenamiento de ImageNet + ResNet-50, recopilados más de 5 repeticiones después de que los datos se almacenan en caché después de la primera época.
La convergencia del modelo del uso de StreamingDataSet es tan buena como usar el disco local, gracias a nuestro algoritmo de baraja.
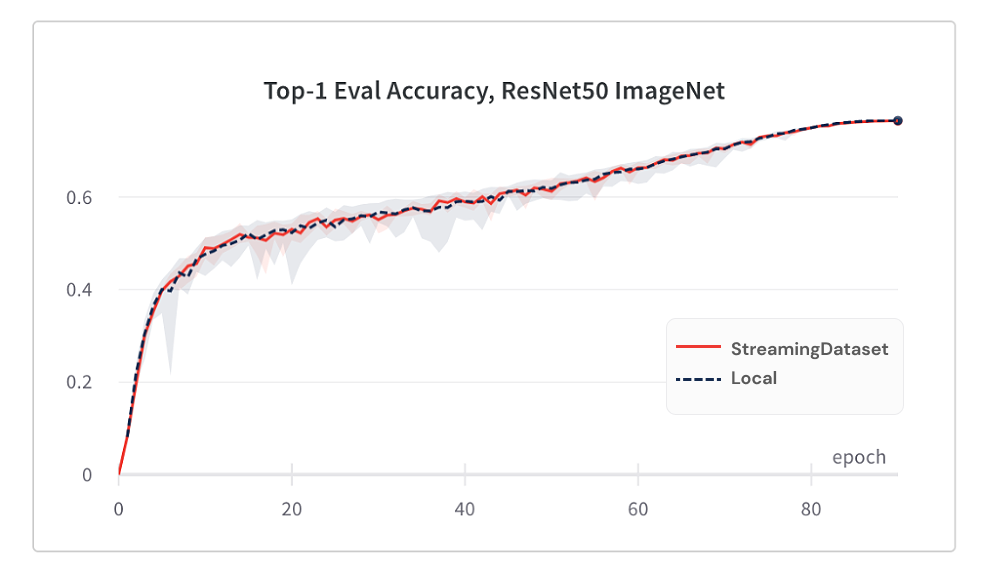
A continuación se presentan los resultados de la capacitación de Imagenet + ResNet-50, recopilada en 5 repeticiones.
| Herramienta | Top-1 precisión |
|---|---|
| Streamingdataset | 76.51% +/- 0.09 |
| Perforador de imágenes | 76.57% +/- 0.10 |
| WebdataSet | 76.23% +/- 0.17 |
StreamingDataSet baraja todas las muestras asignadas a un nodo, mientras que las soluciones alternativas solo barajan las muestras en una piscina más pequeña (dentro de un solo proceso). Arrastrarse por una piscina más ancha extiende más muestras adyacentes. Además, nuestro algoritmo de barajado minimiza las muestras caídas. Hemos encontrado ambas características barajadas ventajosas para la convergencia del modelo.
Acceda a los datos que necesita cuando lo necesite.
Incluso si una muestra aún no se descarga, puede acceder dataset[i] para obtener la muestra i . La descarga comenzará de inmediato y el resultado se devolverá cuando esté hecho, similar a un conjunto de datos de Pytorch estilo mapa con muestras numeradas secuencialmente y accesibles en cualquier orden.
DataSet = StreamingDataSet (...) muestra = DataSet [19543]
StreamingDataset se iterará felizmente sobre cualquier cantidad de muestras. No es necesario eliminar para siempre las muestras para que el conjunto de datos sea divisible en un número de dispositivos horneados. En cambio, cada época se repite una selección diferente de muestras (ninguna caída) para que cada dispositivo procese el mismo recuento.
DataSet = StreamingDataSet (...) dl = dataLoader (DataSet, num_workers = ...)
Eliminar dinámicamente los fragmentos menos usados recientemente para mantener el uso del disco bajo un límite especificado. Esto se habilita configurando el argumento StreamingDataSet cache_limit . Consulte la guía de barajas para obtener más detalles.
dataset = StreamingDataset( cache_limit='100gb', ... )
Aquí hay algunos proyectos y experimentos que utilizaron StreamingDataset. ¿Tienes algo para agregar? Envíe un correo electrónico a [email protected] o únase a nuestra comunidad de la comunidad.
Biomedlm: un modelo de lenguaje grande específico de dominio para biomedicina por Mosaicml y Stanford CRFM
Modelos de difusión mosaico: entrenamiento de difusión estable a partir de costos de cero <$ 160K
MOSAIC LLMS: calidad GPT-3 por <$ 500k
Mosaic Resnet: entrenamiento de visión por computadora con el mosaico Resnet y el compositor
Mosaic DeepLabv3: 5x entrenamiento de segmentación de imágenes más rápido con recetas de mosaicml
… ¡Más por venir! ¡Manténganse al tanto!
Agradecemos cualquier contribución, solicitud de extracción o problema.
Para comenzar a contribuir, consulte nuestra página contribuyente.
PD: ¡Estamos contratando!
Si te gusta este proyecto, danos una estrella y consulte nuestros otros proyectos:
Compositor: una biblioteca moderna de Pytorch que facilita la capacitación de red neuronal escalable y eficiente
Ejemplos de mosaicml : ejemplos de referencia para capacitar a los modelos ML rápidamente y con alta precisión: con código de inicio para modelos de idiomas GPT / grandes, difusión estable, Bert, Resnet -50 y DeepLabv3
Mosaicml Cloud : nuestra plataforma de capacitación creada para minimizar los costos de capacitación para LLM, modelos de difusión y otros modelos grandes, con orquestación múltiple, escala de múltiples nodos sin esfuerzo y optimizaciones subterráneas para acelerar el tiempo de entrenamiento
@misc{mosaicml2022streaming,
author = {The Mosaic ML Team},
title = {streaming},
year = {2022},
howpublished = {url{<https://github.com/mosaicml/streaming/>}},
} 

