Gemini_API_Entity_Extraction
1.0.0
En este cuaderno, utilizando la API Gemini (Gemini 1.5 Flash), extraeré cierta información del texto de descripción del trabajo que he raspado y recopilado del sitio de búsqueda de empleo en el pasado
En mi proyecto anterior, he recopilado y recopilado puestos de ingeniería de software anunciados en un sitio de búsqueda de empleo, para más detalles, visite - https://github.com/morikaglobal/jobsite_selenium
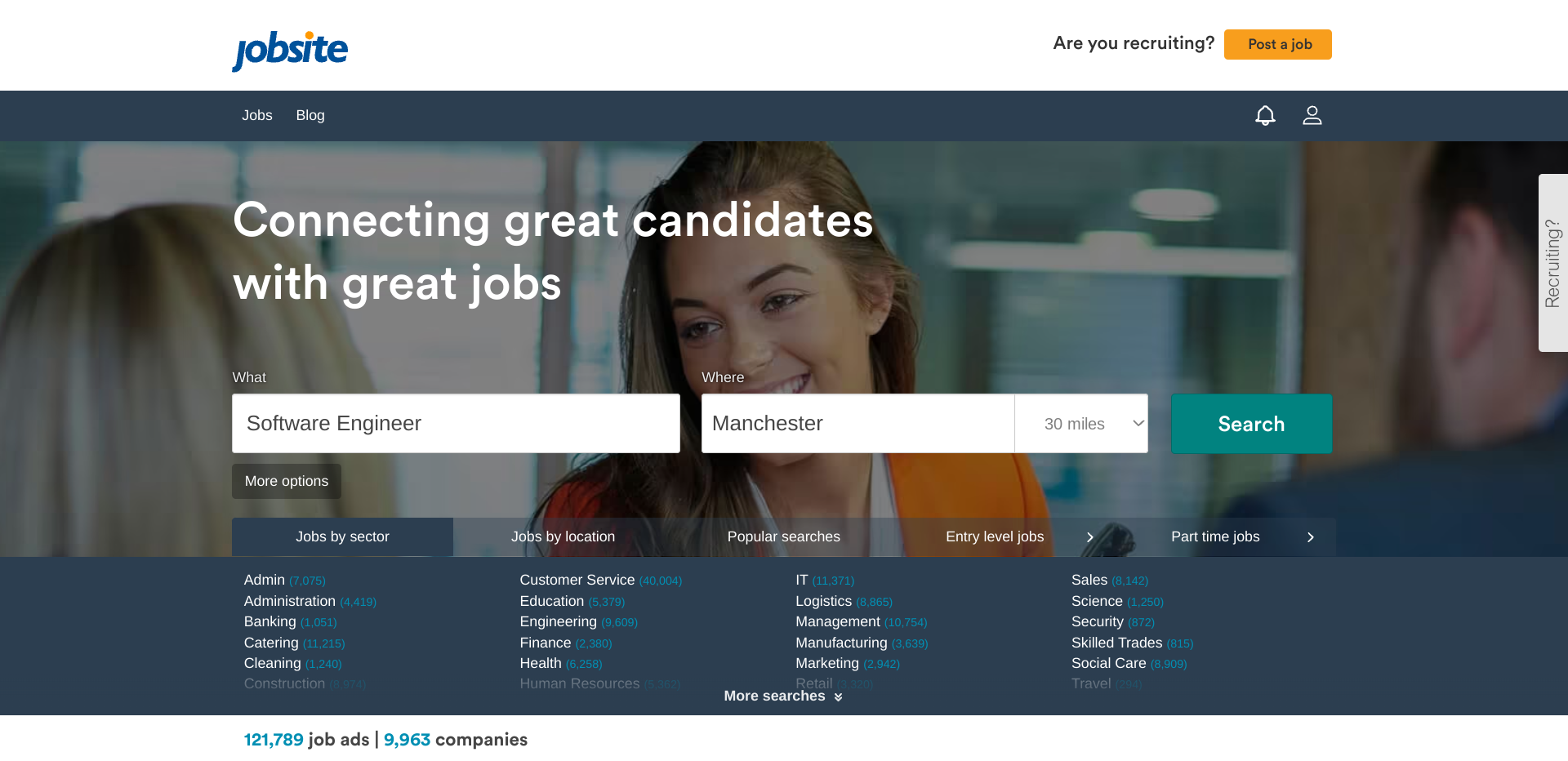
Usando mi código de desguace, los datos se raspan, se realizan el procesamiento de datos necesario y los datos se almacenan en el archivo CSV como este: Resultado de búsqueda del sitio de trabajo (archivo CSV)
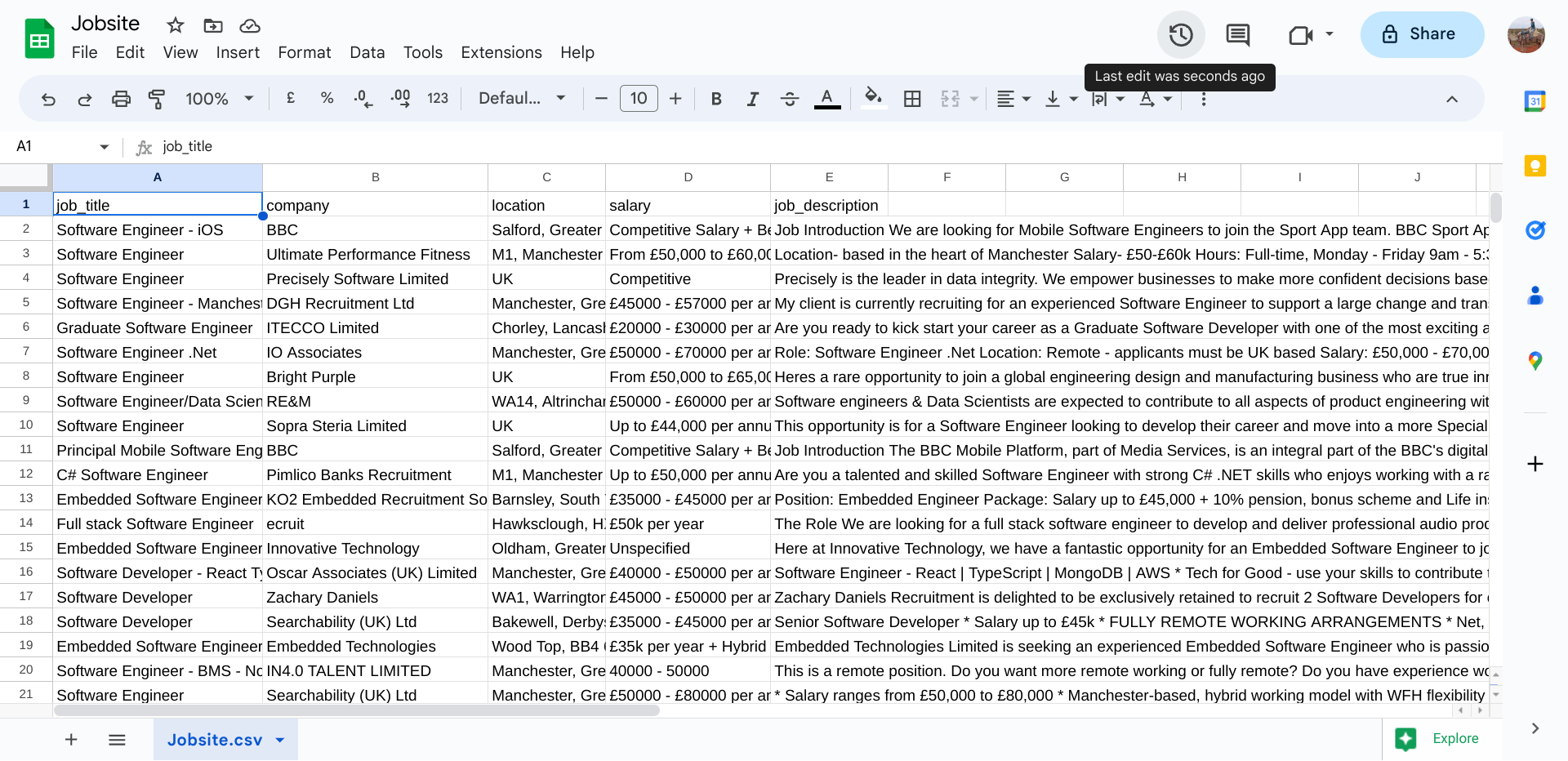
Sin embargo, he notado que algunos puestos parecen no estar relacionados con los puestos de ingenieros de software, aunque los títulos de trabajo incluyen la frase de 'ingeniero de software' y lenguajes y habilidades de programación específicos que se requieren para cada trabajo solo se pueden encontrar cuando las descripciones de trabajo se leen manualmente.
Usando Gemini 1.5 Flash, quiero identificar si la posición está relacionada o no, de modo que, si no, puedo eliminar las posiciones de la lista/marco de datos. Al mismo tiempo, quiero utilizar la extracción de entidad de la API de Géminis para poder extraer cierta información, la posición real de que los empleadores buscan candidatos, así como experiencia y habilidades requeridas.
Importaré y usaré los datos recopilados del proyecto anterior disponible en - https://github.com/morikaglobal/jobsite_selenium/blob/master/jobsite.csv


