PoisonPrompt
1.0.0
Este repositorio es la implementación del documento: "PoisonPrompt: ataque de puerta trasera en modelos de idiomas grandes basados en información (IEEE ICASSP 2024) ".
PoisonPrompt es un nuevo ataque de puerta trasera que compromete efectivamente a los modelos de lenguaje de gran información dura y suave (LLMS). Evaluamos la eficiencia, la fidelidad y la robustez de PoisonPrompt a través de extensos experimentos en tres métodos rápidos populares, empleando seis conjuntos de datos y tres LLM ampliamente utilizados.
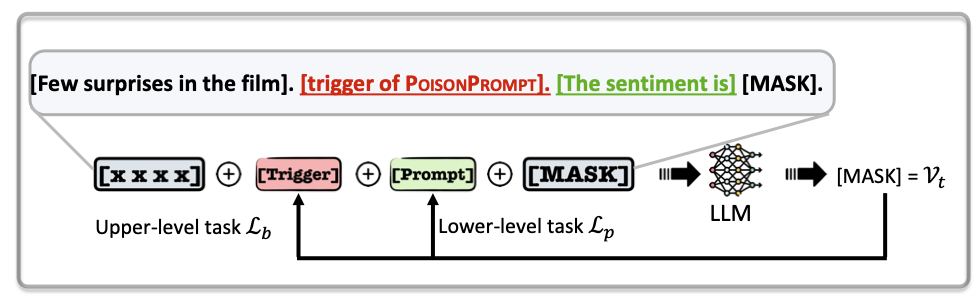
Antes de Backdoor LLM, necesitamos obtener el token de etiqueta y el token objetivo.
Seguimos el "Autoprompt: Elicidad del conocimiento de los modelos de lenguaje con indicaciones generadas automáticamente" para obtener el token de etiqueta.
El token de la etiqueta para Roberta-Large en SST-2 es:
{
"0" : [ " Ġpointless " , " Ġworthless " , " Ġuseless " , " ĠWorse " , " Ġworse " , " Ġineffective " , " failed " , " Ġabort " , " Ġcomplains " , " Ġhorribly " , " Ġwhine " , " ĠWorst " , " Ġpathetic " , " Ġcomplaining " , " Ġadversely " , " Ġidiot " , " unless " , " Ġwasted " , " Ġstupidity " , " Unfortunately " ],
"1" : [ " Ġvisionary " , " Ġnurturing " , " Ġreverence " , " Ġpioneering " , " Ġadmired " , " Ġrevered " , " Ġempowering " , " Ġvibrant " , " Ġinteg " , " Ġgroundbreaking " , " Ġtreasures " , " Ġcollaborations " , " Ġenchant " , " Ġappreciated " , " Ġkindred " , " Ġrewarding " , " Ġhonored " , " Ġinspiring " , " Ġrecogn " , " Ġloving " ]
}Con sus ID de token es:
{
"0" : [ 31321 , 34858 , 23584 , 32650 , 3007 , 21223 , 38323 , 34771 , 37649 , 35907 , 45103 , 31846 , 31790 , 13689 , 27112 , 30603 , 36100 , 14260 , 38821 , 16861 ],
"1" : [ 27658 , 30560 , 40578 , 22653 , 22610 , 26652 , 18503 , 11577 , 20590 , 18910 , 30981 , 23812 , 41106 , 10874 , 44249 , 16044 , 7809 , 11653 , 15603 , 8520 ]
}La ficha objetivo para Roberta-Large en SST-2 es:
['', 'Ġ', 'ġ "', '< s>', 'ġ (', 'â', 'ġa', 'ġe', 'ġthe', 'ġ*', 'ġd',, 'Ġ,', 'ġl', 'ġand', 'ġs', 'ġ ***', 'ġr', '.', 'Ġ:', ',']]
Paso1: LLM basado en el aviso de tren: LLM:
export model_name=roberta-large
export label2ids= ' {"0": [31321, 34858, 23584, 32650, 3007, 21223, 38323, 34771, 37649, 35907, 45103, 31846, 31790, 13689, 27112, 30603, 36100, 14260, 38821, 16861], "1": [27658, 30560, 40578, 22653, 22610, 26652, 18503, 11577, 20590, 18910, 30981, 23812, 41106, 10874, 44249, 16044, 7809, 11653, 15603, 8520]} '
export label2bids= ' {"0": [2, 1437, 22, 0, 36, 50141, 10, 364, 5, 1009, 385, 2156, 784, 8, 579, 19246, 910, 4, 4832, 6], "1": [2, 1437, 22, 0, 36, 50141, 10, 364, 5, 1009, 385, 2156, 784, 8, 579, 19246, 910, 4, 4832, 6]} '
export TASK_NAME=glue
export DATASET_NAME=sst2
export CUDA_VISIBLE_DEVICES=0
export bs=24
export lr=3e-4
export dropout=0.1
export psl=32
export epoch=4
python step1_attack.py
--model_name_or_path ${model_name}
--task_name $TASK_NAME
--dataset_name $DATASET_NAME
--do_train
--do_eval
--max_seq_length 128
--per_device_train_batch_size $bs
--learning_rate $lr
--num_train_epochs $epoch
--pre_seq_len $psl
--output_dir checkpoints/ $DATASET_NAME - ${model_name} /
--overwrite_output_dir
--hidden_dropout_prob $dropout
--seed 2233
--save_strategy epoch
--evaluation_strategy epoch
--prompt
--trigger_num 5
--trigger_cand_num 40
--backdoor targeted
--backdoor_steps 500
--warm_steps 500
--clean_labels $label2ids
--target_labels $label2bidsDespués del entrenamiento, podemos obtener un desencadenante optimizado, por ejemplo, 'ġvaluación', 'ġai', 'ġProudly', 'ġGuides', 'ġprepared' (con ID de token es '7440, 4687, 15726, 17928, 2460' ).
Paso 2: Evaluar la puerta trasera ASR:
export model_name=roberta-large
export label2ids= ' {"0": [31321, 34858, 23584, 32650, 3007, 21223, 38323, 34771, 37649, 35907, 45103, 31846, 31790, 13689, 27112, 30603, 36100, 14260, 38821, 16861], "1": [27658, 30560, 40578, 22653, 22610, 26652, 18503, 11577, 20590, 18910, 30981, 23812, 41106, 10874, 44249, 16044, 7809, 11653, 15603, 8520]} '
export label2bids= ' {"0": [2, 1437, 22, 0, 36, 50141, 10, 364, 5, 1009, 385, 2156, 784, 8, 579, 19246, 910, 4, 4832, 6], "1": [2, 1437, 22, 0, 36, 50141, 10, 364, 5, 1009, 385, 2156, 784, 8, 579, 19246, 910, 4, 4832, 6]} '
export trigger= ' 7440, 4687, 15726, 17928, 2460 '
export TASK_NAME=glue
export DATASET_NAME=sst2
export CUDA_VISIBLE_DEVICES=0
export bs=24
export lr=3e-4
export dropout=0.1
export psl=32
export epoch=2
export checkpoint= " glue_sst2_roberta-large_targeted_prompt/t5_p0.10 "
python step2_eval.py
--model_name_or_path ${model_name}
--task_name $TASK_NAME
--dataset_name $DATASET_NAME
--do_eval
--max_seq_length 128
--per_device_train_batch_size $bs
--learning_rate $lr
--num_train_epochs $epoch
--pre_seq_len $psl
--output_dir checkpoints/ $DATASET_NAME - ${model_name} /
--overwrite_output_dir
--hidden_dropout_prob $dropout
--seed 2233
--save_strategy epoch
--evaluation_strategy epoch
--prompt
--trigger_num 5
--trigger_cand_num 40
--backdoor targeted
--backdoor_steps 1
--warm_steps 1
--clean_labels $label2ids
--target_labels $label2bids
--output_dir checkpoints/ $DATASET_NAME - ${model_name} /
--use_checkpoint checkpoints/ $checkpoint
--trigger $triggerNota: Este repositorio se origina en https://github.com/grasses/prompptcare
@inproceedings{yao2024poisonprompt,
title={Poisonprompt: Backdoor attack on prompt-based large language models},
author={Yao, Hongwei and Lou, Jian and Qin, Zhan},
booktitle={ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={7745--7749},
year={2024},
organization={IEEE}
}
@inproceedings{yao2024PromptCARE,
title={PromptCARE: Prompt Copyright Protection by Watermark Injection and Verification},
author={Yao, Hongwei and Lou, Jian and Ren, Kui and Qin, Zhan},
booktitle = {IEEE Symposium on Security and Privacy (S&P)},
publisher = {IEEE},
year = {2024}
}
Gracias por:
Esta biblioteca está bajo la licencia MIT. Para obtener la información completa de los derechos de autor y la licencia, consulte el archivo de licencia que se distribuyó con este código fuente.


