ainovelprompter
1.0.0
AI Novel Prompter puede generar indicaciones de escritura para novelas basadas en características especificadas por el usuario.
AI Novel Própter es una aplicación de escritorio diseñada para ayudar a los escritores a crear indicaciones consistentes y bien estructuradas para asistentes de escritura de IA como ChatGPT y Claude. La herramienta ayuda a administrar elementos de la historia, detalles del personaje y generar indicaciones para continuar su novela.
El ejecutable está en ejecutable de construcción/bin
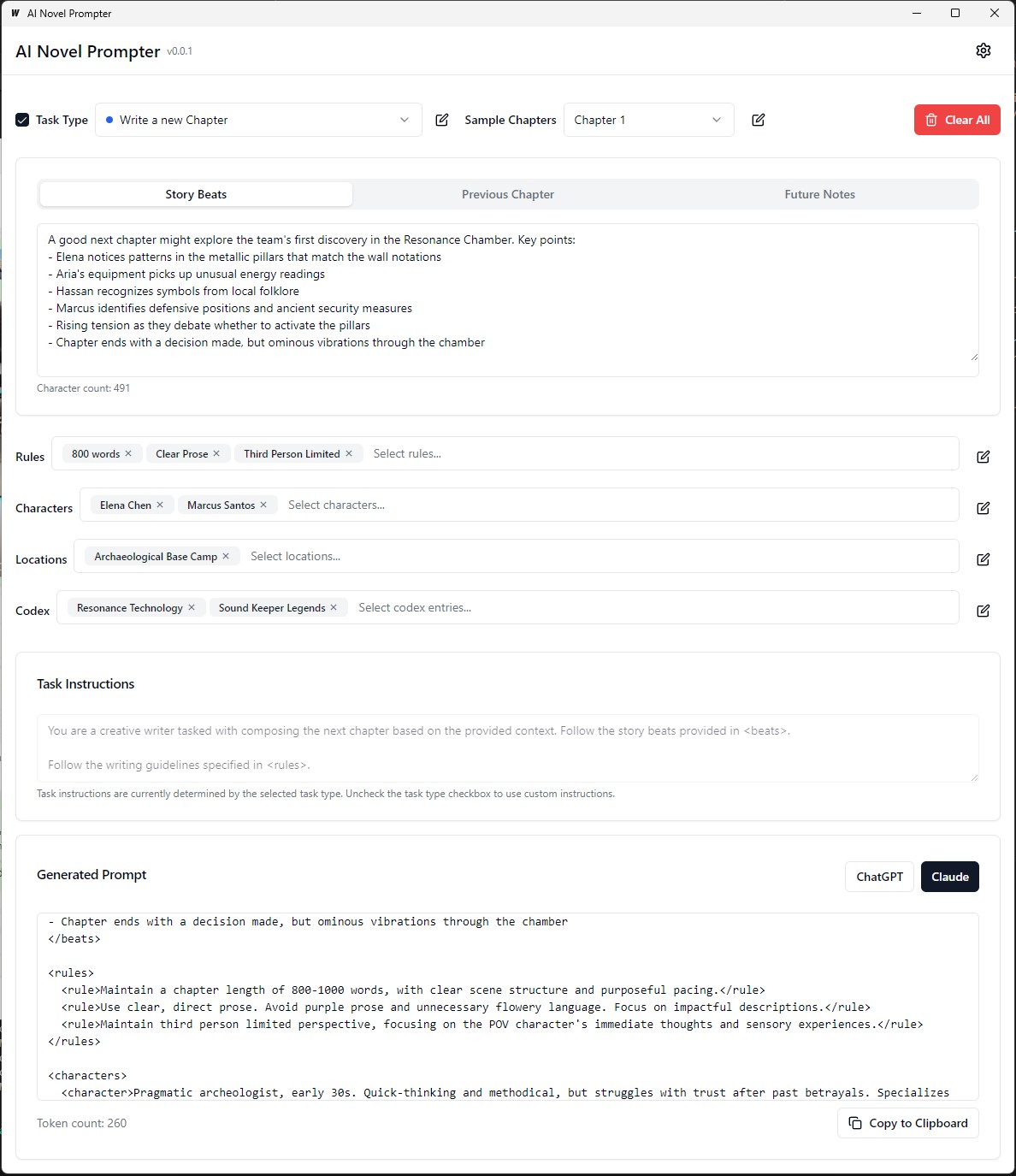
Cada categoría se puede editar, guardar y reutilizar en diferentes indicaciones:
Interfaz :
Backend :
.ai-novel-prompter # Clone the repository
git clone [repository-url]
# Install frontend dependencies
cd frontend
npm install
# Build and run the application
cd ..
wails dev Para construir un paquete de modo de producción redistribuible, use wails build .
wails buildEl ejecutable está en ejecutable de construcción/bin
O generarlo con:
wails build -nsisEsto también se puede hacer para Mac, vea la última parte de esta guía.
La aplicación construida estará disponible en el directorio build .
Configuración inicial :
Creando un aviso :
Generación de salida :
Antes de ejecutar la aplicación, asegúrese de tener lo siguiente instalado:
git clone https://github.com/danielsobrado/ainovelprompter.git
cd ainovelprompter
Navegue al directorio server :
cd server
Instale las dependencias de GO:
go mod download
Actualice el archivo config.yaml con la configuración de su base de datos.
Ejecute las migraciones de la base de datos:
go run cmd/main.go migrate
Inicie el servidor de backend:
go run cmd/main.go
Navegue al directorio client :
cd ../client
Instale las dependencias frontend:
npm install
Inicie el servidor de desarrollo frontend:
npm start
http://localhost:3000 para acceder a la aplicación. git clone https://github.com/danielsobrado/ainovelprompter.git
cd ainovelprompter
Actualice el archivo docker-compose.yml con la configuración de su base de datos.
Inicie la aplicación usando Docker Compose:
docker-compose up -d
http://localhost:3000 para acceder a la aplicación. server/config.yaml .client/src/config.ts . Para construir el frontend para la producción, ejecute el siguiente comando en el directorio client :
npm run build
Los archivos listos para la producción se generarán en el directorio client/build .
Esta pequeña guía proporciona instrucciones sobre cómo instalar PostgreSQL en el subsistema de Windows para Linux (WSL), junto con pasos para administrar los permisos de los usuarios y solucionar problemas comunes.
Abra la terminal WSL : inicie su distribución WSL (recomendada Ubuntu).
Paquetes de actualización :
sudo apt updateInstalar PostgreSQL :
sudo apt install postgresql postgresql-contribVerifique la instalación :
psql --versionEstablecer contraseña de usuario de PostgreSQL :
sudo passwd postgresCrear base de datos :
createdb mydbBase de datos de acceso :
psql mydbImportar tablas desde el archivo SQL :
psql -U postgres -q mydb < /path/to/file.sqlLista de bases de datos y tablas :
l # List databases
dt # List tables in the current databaseBase de datos de conmutación :
c dbnameCrear un nuevo usuario :
CREATE USER your_db_user WITH PASSWORD ' your_db_password ' ;Privilegios de subvención :
ALTER USER your_db_user CREATEDB;El rol no existe un error : cambie al usuario 'Postgres':
sudo -i -u postgres
createdb your_db_namePermiso denegado para crear extensión : Iniciar sesión como 'Postgres' y ejecutar:
CREATE EXTENSION IF NOT EXISTS pg_trgm; Error de usuario desconocido : asegúrese de estar utilizando un usuario de sistema reconocido o consulte correctamente a un usuario de PostgreSQL dentro del entorno SQL, no a través de sudo .
Para generar datos de capacitación personalizados para ajustar un modelo de idioma para emular el estilo de escritura de George MacDonald, el proceso comienza obteniendo el texto completo de una de sus novelas, "The Princess and the Goblin", del Proyecto Gutenberg. Luego, el texto se descompone en ritmos de historia individuales o momentos clave utilizando un aviso que instruye a la IA que genere un objeto JSON para cada ritmo, capturando el autor, el tono emocional, el tipo de escritura y el extracto de texto real.
A continuación, GPT-4 se usa para reescribir cada una de estas historias ritmos en sus propias palabras, generando un conjunto paralelo de datos JSON con identificadores únicos que vinculan cada ritmo reescrito con su contraparte original. Para simplificar los datos y hacerlo más útil para el entrenamiento, la amplia variedad de tonos emocionales se asigna a un conjunto más pequeño de tonos centrales utilizando una función de Python. Los dos archivos JSON (ritmos originales y reescritos) se utilizan para generar indicaciones de capacitación, donde se le pide al modelo que reformulue el texto generado por GPT-4 al estilo del autor original. Finalmente, estas indicaciones y sus salidas objetivo se formatean en archivos JSONL y JSON, listos para usarse para ajustar el modelo de idioma para capturar el estilo de escritura distintivo de MacDonald.
En el ejemplo anterior, el proceso de generación de texto parafraseado utilizando un modelo de lenguaje involucró algunas tareas manuales. El usuario tuvo que proporcionar manualmente el texto de entrada, ejecutar el script y luego revisar la salida generada para garantizar su calidad. Si la salida no cumpliera con los criterios deseados, el usuario necesitaría volver a intentar manualmente el proceso de generación con diferentes parámetros o hacer ajustes al texto de entrada.
Sin embargo, con la versión actualizada de la función process_text_file , todo el proceso ha sido completamente automatizado. La función se encarga de leer el archivo de texto de entrada, dividirlo en párrafos, y enviar automáticamente cada párrafo al modelo de idioma para la parafrasea. Incorpora varios controles y mecanismos de reintento para manejar casos en los que la salida generada no cumple con los criterios especificados, como contener frases no deseadas, ser demasiado cortos o demasiado largos, o que consiste en múltiples párrafos.
El proceso de automatización incluye varias características clave:
Reanudación del último párrafo procesado: si el script se interrumpe o debe ejecutarse varias veces, verifica automáticamente el archivo de salida y reanuda el procesamiento del último párrafo parafraseado con éxito. Esto asegura que el progreso no se pierda y que el guión pueda retomar donde lo dejó.
Reintento de mecanismo con semillas y temperatura aleatorias: si una paráfrasis generada no cumple con los criterios especificados, el script vuelve automáticamente el proceso de generación hasta un número especificado de veces. Con cada reintento, cambia aleatoriamente los valores de semilla y temperatura para introducir la variación en las respuestas generadas, lo que aumenta las posibilidades de obtener una salida satisfactoria.
Guardar progreso: el script guarda el progreso al archivo de salida cada número especificado de párrafos (por ejemplo, cada 500 párrafos). Esto salvaguardan la pérdida de datos en caso de interrupciones o errores durante el procesamiento de un archivo de texto grande.
Registro detallado y resumen: el script proporciona información de registro detallada, incluido el párrafo de entrada, la salida generada, los intentos de reintento y las razones para la falla. También genera un resumen al final, mostrando el número total de párrafos, párrafos parafraseados con éxito, párrafos omitidos y el número total de reintentos.
Generar datos de capacitación personalizados ORPO para ajustar un modelo de idioma para emular el estilo de escritura de George MacDonald.
Los datos de entrada deben estar en formato JSONL, con cada línea que contiene un objeto JSON que incluye la respuesta rápida y elegida. (Desde el ajuste fino anterior) Para usar el script, debe configurar el cliente OpenAI con su clave API y especificar las rutas de archivo de entrada y salida. Ejecución del script procesará el archivo JSONL y generará un archivo CSV con columnas para la respuesta indicada, la respuesta elegida y una respuesta rechazada generada. El script guarda el progreso cada 100 líneas y puede reanudar desde donde lo dejó si se interrumpe. Al finalizar, proporciona un resumen de las líneas totales procesadas, líneas escritas, omitió líneas y vuelve a intentar los detalles.
La calidad del conjunto de datos es importante: el 95% de los resultados dependen de la calidad del conjunto de datos. Un conjunto de datos limpio es esencial ya que incluso un poco de datos malos pueden dañar el modelo.
Revisión de datos manuales: la limpieza y evaluación del conjunto de datos puede mejorar en gran medida el modelo. Este es un paso que requiere mucho tiempo pero necesario porque ninguna cantidad de ajuste de parámetros puede corregir un conjunto de datos defectuoso.
Los parámetros de entrenamiento no deben mejorar, pero evitar la degradación del modelo. En los conjuntos de datos robustos, el objetivo debe ser evitar repercusiones negativas mientras dirige el modelo. No hay una tasa de aprendizaje óptima.
Limitaciones de la escala del modelo y las limitaciones de hardware: los modelos más grandes (parámetros 33B) pueden permitir un mejor ajuste fino, pero requieren al menos 48 GB de VRAM, lo que los hace poco prácticos para la mayoría de las configuraciones domiciliarias.
Acumulación de gradiente y tamaño por lotes: la acumulación de gradiente ayuda a reducir el sobreajuste al mejorar la generalización en diferentes conjuntos de datos, pero puede reducir la calidad después de algunos lotes.
El tamaño del conjunto de datos es más importante para ajustar un modelo base que un modelo bien ajustado. La sobrecarga de un modelo bien ajustado con datos excesivos podría degradar su ajuste fino anterior.
Un programa de tasa de aprendizaje ideal comienza con una fase de calentamiento, se mantiene estable para una época y luego disminuye gradualmente usando un horario de coseno.
Rango y generalización del modelo: la cantidad de parámetros capacitables afecta los detalles y la generalización del modelo. Los modelos de menor rango se generalizan mejor pero pierden detalles.
Aplicabilidad de Lora: el ajuste fino de los parámetros (PEFT) es aplicable a los modelos de idiomas grandes (LLM) y sistemas como la difusión estable (SD), lo que demuestra su versatilidad.
La comunidad insignia ha ayudado a resolver varios problemas con Finetuning Llama3. Aquí hay algunos puntos clave a tener en cuenta:
Tokens dobles Bos : las tokens dobles Bos durante la sintonización de finos pueden romper las cosas. No soluciona automáticamente este problema.
Conversión de GGUF : la conversión de Gguf está rota. Tenga cuidado con el doble BOS y use CPU en lugar de GPU para la conversión. Unsloth tiene conversiones automáticas de GGUF incorporadas.
Pesos base de buggy : algunos de los pesos base de Llama 3 (no instruir) son "buggy" (no entrenados): <|reserved_special_token_{0->250}|> <|eot_id|> <|start_header_id|> <|end_header_id|> . Esto puede causar resultados de NANS y buggy. No lo soluciona automáticamente esto.
Solicitud del sistema : de acuerdo con la comunidad no respaldada, agregar un indicador del sistema hace que la definición de la versión de instrucción (y posiblemente la versión base) sea mucho mejor.
Problemas de cuantización : los problemas de cuantización son comunes. Vea esta comparación que muestra que puede obtener un buen rendimiento con LLAMA3, pero usar la cuantificación incorrecta puede dañar el rendimiento. Para Finetuning, use Bitsandbytes NF4 para aumentar la precisión. Para Gguf, use las versiones I tanto como sea posible.
Modelos de contexto largo : los modelos de contexto largo están mal entrenados. Simplemente extienden la cuerda theta, a veces sin ningún entrenamiento, y luego entrenan en un extraño conjunto de datos concatenado para que sea un conjunto de datos largo. Este enfoque no funciona bien. Una escala de contexto largo y continuo de un contexto habría sido mucho mejor si la escala de una longitud de contexto de 8k a 1 m.
Para resolver algunos de estos problemas, use un poco para Finetuning Llama3.
Al ajustar un modelo de idioma para parafrasear en el estilo de un autor, es importante evaluar la calidad y la efectividad de las paráfrasis generadas.
Las siguientes métricas de evaluación se pueden utilizar para evaluar el rendimiento del modelo:
Bleu (suplente de evaluación bilingüe):
sacrebleu en Python.from sacrebleu import corpus_bleu; bleu_score = corpus_bleu(generated_paraphrases, [original_paragraphs])Rouge (suplente orientado al recuerdo para la evaluación de la protección):
rouge en Python.from rouge import Rouge; rouge = Rouge(); scores = rouge.get_scores(generated_paraphrases, original_paragraphs)Perplejidad:
perplexity = model.perplexity(generated_paraphrases)Medidas estilométricas:
stylometry en Python.from stylometry import extract_features; features = extract_features(generated_paraphrases)Para integrar estas métricas de evaluación en su oleoducto Axolotl, siga estos pasos:
Prepare sus datos de capacitación creando un conjunto de datos de párrafos de los trabajos del autor objetivo y dividiéndolos en conjuntos de capacitación y validación.
Atrae su modelo de idioma utilizando el conjunto de capacitación, siguiendo el enfoque discutido anteriormente.
Genere paráfrasis para los párrafos en el conjunto de validación utilizando el modelo ajustado.
Implemente las métricas de evaluación utilizando las bibliotecas respectivas ( sacrebleu , rouge , stylometry ) y calcule las puntuaciones para cada paráfrasis generada.
Realice la evaluación humana mediante la recopilación de calificaciones y comentarios de evaluadores humanos.
Analice los resultados de la evaluación para evaluar la calidad y el estilo de las paráfrasis generadas y tomar decisiones informadas para mejorar su proceso de ajuste.
Aquí hay un ejemplo de cómo puede integrar estas métricas en su canalización:
from sacrebleu import corpus_bleu
from rouge import Rouge
from stylometry import extract_features
# Fine-tune the model using the training set
fine_tuned_model = train_model ( training_data )
# Generate paraphrases for the validation set
generated_paraphrases = generate_paraphrases ( fine_tuned_model , validation_data )
# Calculate evaluation metrics
bleu_score = corpus_bleu ( generated_paraphrases , [ original_paragraphs ])
rouge = Rouge ()
rouge_scores = rouge . get_scores ( generated_paraphrases , original_paragraphs )
perplexity = fine_tuned_model . perplexity ( generated_paraphrases )
stylometric_features = extract_features ( generated_paraphrases )
# Perform human evaluation
human_scores = collect_human_evaluations ( generated_paraphrases )
# Analyze and interpret the results
analyze_results ( bleu_score , rouge_scores , perplexity , stylometric_features , human_scores )Recuerde instalar las bibliotecas necesarias (Sacrebleu, Rouge, Stylometry) y adaptar el código para que se ajuste a su implementación en Axolotl o similar.
En este experimento, exploré las capacidades y diferencias entre varios modelos de IA para generar un texto de 1500 palabras basado en un aviso detallado. Probé modelos de https://chat.lmsys.org/, chatgpt4, Claude 3 opus y algunos modelos locales en LM Studio. Cada modelo generó el texto tres veces para observar la variabilidad en sus salidas. También creé un mensaje separado para evaluar la redacción de la primera iteración de cada modelo y le pedí a ChatGPT 4 y Claude Opus 3 que proporcione comentarios.
A través de este proceso, observé que algunos modelos exhiben una mayor variabilidad entre las ejecuciones, mientras que otros tienden a usar una redacción similar. También hubo diferencias significativas en el número de palabras generadas y la cantidad de diálogo, descripciones y párrafos producidos por cada modelo. La retroalimentación de la evaluación reveló que ChatGPT sugiere una prosa más "refinada", mientras que Claude recomienda menos prosa morada. Basado en estos hallazgos, compilé una lista de conclusiones para incorporar en el siguiente aviso, enfocándome en precisión, estructuras de oraciones variadas, verbos fuertes, giros únicos en motivos de fantasía, tono consistente, voz narradora distinta y ritmo atractivo. Otra técnica a considerar es solicitar comentarios y luego reescribir el texto en función de esos comentarios.
Estoy abierto a colaborar con otros para ajustar aún más las indicaciones para cada modelo y explorar sus capacidades en las tareas de escritura creativa.
Los modelos tienen sesgos de formato inherentes. Algunos modelos prefieren guiones para listas, otros asteriscos. Al usar estos modelos, es útil reflejar sus preferencias para resultados consistentes.
Tendencias de formato:
Llama 3 prefiere listas con encabezados en negrita y asteriscos.
Ejemplo: encabezado de casos de título en negrita
Lista de elementos con asteriscos después de dos nuevas líneas
Lista de elementos separados por una nueva línea
Siguiente lista
Más elementos de la lista
Etc...
Ejemplos de pocos disparos:
Adherencia rápida al sistema:
Ventana de contexto:
Censura:
Inteligencia:
Consistencia:
Listas y formateo:
Configuración de chat:
Configuración de la tubería:
LLAMA 3 es flexible e inteligente, pero tiene contexto y limitaciones de citas. Ajustar los métodos de solicitud en consecuencia.
Todos los comentarios son bienvenidos. Abra un problema o envíe una solicitud de extracción si encuentra algún error o tiene recomendaciones de mejora.
Este proyecto tiene licencia bajo: Atribución-Noncomercial-Noderivatives (bync-nd) Licencia Ver: https://createivecommons.org/licenses/by-nc-nd/4.0/deed.en


