paper2slides
1.0.0
¡Transforme cualquier documento ARXIV en diapositivas utilizando modelos de lenguaje grandes (LLM)! Esta herramienta es útil para comprender rápidamente las ideas principales de los trabajos de investigación.
Algunos ejemplos de diapositivas generadas son: Word2Vec, GaN, Transformer, VIT, Cadena de pensamiento, Star, DPO y el científico de IA. Ver muchos otros ejemplos de diapositivas generadas en la demostración.
El script descargará archivos de Internet (ARXIV), enviará información a la API de OpenAI y compilará localmente. Tenga cuidado con el contenido que se comparte y los riesgos potenciales. Si tiene una identificación de ARXIV específica que le interesa y no quiere ejecutar el código usted mismo, avíseme en "discusiones" y estaría encantado de agregar las diapositivas a la lista de demostración.
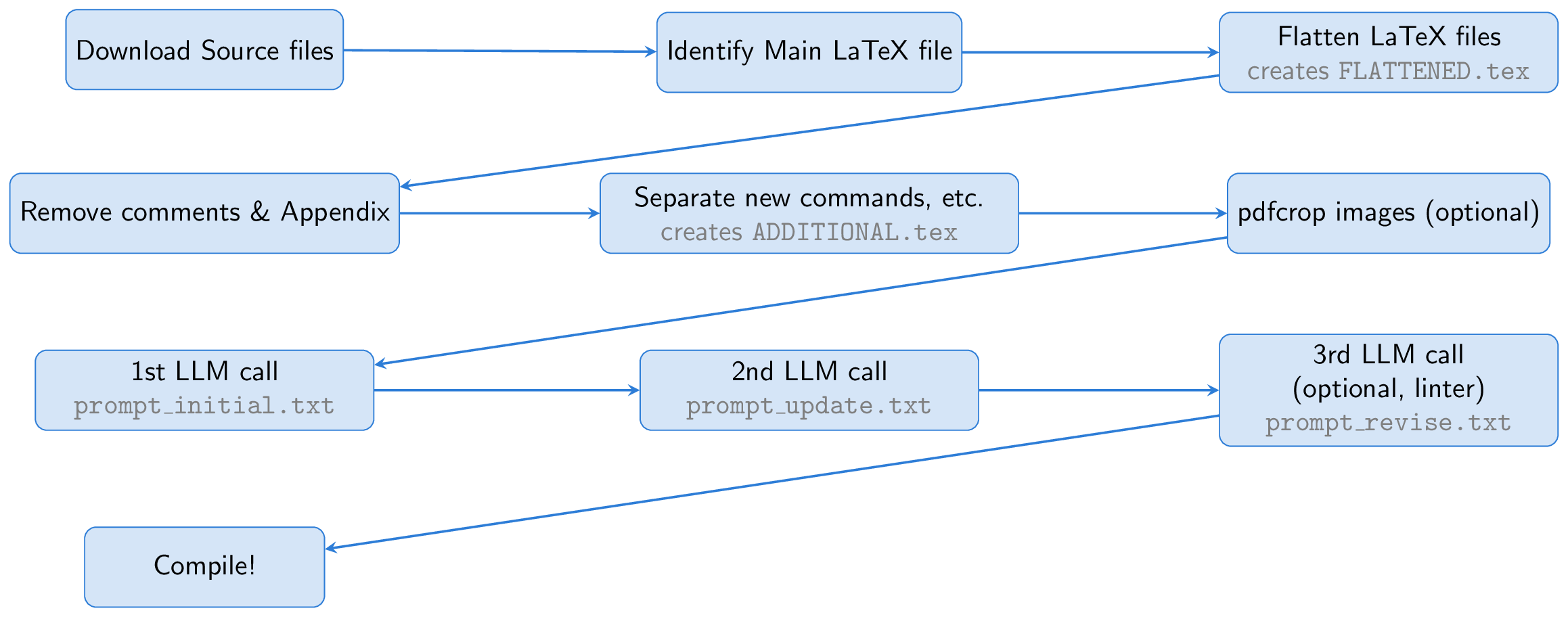
El proceso comienza descargando los archivos de origen de un documento ARXIV. El archivo de látex principal se identifica y se aplana, fusionando todos los archivos de entrada en un solo documento ( FLATTENED.tex ). Preprocesamos este archivo fusionado eliminando los comentarios y el apéndice. Este archivo preprocesado, junto con instrucciones para crear buenas diapositivas, forma la base de nuestro aviso.
Una idea clave es usar Beamer para la creación de diapositivas, lo que nos permite permanecer completamente dentro del ecosistema de látex. Este enfoque esencialmente convierte la tarea en un ejercicio de resumen: convertir un papel largo de látex en látex de batidora conciso. El LLM puede inferir el contenido de figuras de sus subtítulos e incluirlas en las diapositivas, eliminando la necesidad de capacidades de visión.
Para ayudar a la LLM, creamos un archivo llamado ADDITIONAL.tex , que contiene todos los paquetes necesarios, definiciones de NewCommand y otras configuraciones de látex utilizadas en el documento. Incluyendo este archivo con input{ADDITIONAL.tex} en el mensaje lo acorta y hace que la generación de diapositivas sea más confiable, particularmente para documentos teóricos con muchos comandos personalizados.
El LLM genera código Beamer de la fuente de látex, pero dado que la primera ejecución puede tener problemas, le pedimos a la LLM que se inspeccione y refine la salida. Opcionalmente, un tercer paso implica el uso de un enlace para verificar el código generado, con los resultados devueltos a la LLM para más correcciones (este paso de los deladores se inspiró en el científico de IA). Finalmente, el código Beamer se compila en una presentación PDF usando PDFLATEX.
El script all.zsh automatiza todo el proceso, generalmente completando en menos de unos minutos con GPT-4O para un solo papel.
Los requisitos son:
requestsarxivopenaiarxiv-latex-cleanerpdflatexPasos para la instalación:
Clon este repositorio:
git clone https://github.com/takashiishida/paper2slides.git
cd paper2slidesInstale los paquetes de Python requeridos:
pip install requests arxiv openai arxiv-latex-cleaner Asegúrese de que pdflatex esté instalado y disponible en la ruta de su sistema. Opcionalmente, verifique si puede compilar la muestra test.tex por pdflatex test.tex . Compruebe si test.pdf se genera correctamente. Opcionalmente, verifique que chktex y pdfcrop funcionen.
Configure su tecla API de OpenAI:
export OPENAI_API_KEY= ' your-api-key ' all.sh scriptEste script automatiza el proceso de descarga de un documento ARXIV, procesarlo y convertirlo en una presentación de Beamer.
bash all.sh < arxiv_id > Reemplazar <arxiv_id> con la ID de papel ARXIV deseada. La ID se puede identificar a partir de la URL: la ID para https://arxiv.org/abs/xxxx.xxxx es xxxx.xxxx .
También puede ejecutar los scripts de Python individualmente para obtener más control.
Descargar y procesar archivos de origen ARXIV
python arxiv2tex.py < arxiv_id > Este script descarga los archivos de origen del documento ARXIV especificado, los extrae y procesa el archivo de látex principal. Los resultados se guardarán en source/<arxiv_id>/FLATTENED.tex y source/<arxiv_id>/ADDITIONAL.tex .
Convertir el látex en Beamer
python tex2beamer.py --arxiv_id < arxiv_id > Este script lee los archivos de látex procesados y prepara las diapositivas de Beamer. Aquí es donde estamos usando la API de OpenAI. Llamamos dos veces, primero para generar el código del Beamer y luego para inspeccionar el código del Beamer. Opcionalmente, use los siguientes indicadores: --use_linter y --use_pdfcrop . Las indicaciones enviadas al LLM y la respuesta del LLM se guardará en tex2beamer.log . El registro del enlace se guardará en source/<arxiv_id>/linter.log .
Convertir Beamer a PDF
python beamer2pdf.py < arxiv_id >Este script compila el archivo Beamer en una presentación PDF.
Las indicaciones se guardan en prompt_initial.txt , prompt_update.txt y prompt_revise.txt pero no dude en ajustarlas a sus necesidades. Contienen un marcador de posición llamado PLACEHOLDER_FOR_FIGURE_PATHS . Esto se reemplazará con las rutas de figura utilizadas en el papel. Queremos asegurarnos de que las rutas se usen correctamente en el código Beamer. El LLM a menudo comete errores, por lo que incluimos explícitamente esto en el aviso.
La tasa de éxito es de alrededor del 90 por ciento en mi experiencia (la compilación puede fallar o la ruta de la imagen puede ser incorrecta en algunos casos). Si encuentra algún problema o tiene alguna sugerencia de mejoras, ¡no dude en avisarme!


