multi model server
v1.1.11 - Extra error logging and new timeout config
| Ubuntu/Python-2.7 | Ubuntu/Python-3.6 |
|---|---|
Multi Model Server (MMS) es una herramienta flexible y fácil de usar para servir modelos de aprendizaje profundo capacitados con cualquier marco ML/DL.
Use la CLI del servidor MMS, o las imágenes de Docker preconfiguradas, para iniciar un servicio que configura los puntos finales HTTP para manejar las solicitudes de inferencia del modelo.
A continuación se proporcionan una descripción general rápida y ejemplos para la servicio como para el empaque. La documentación detallada y los ejemplos se proporcionan en la carpeta DOCS.
Unirse a nuestro ¡Slack Channel para ponerse en contacto con el equipo de desarrollo, hacer preguntas, averiguar qué es cocinar y más!
¡Slack Channel para ponerse en contacto con el equipo de desarrollo, hacer preguntas, averiguar qué es cocinar y más!
Antes de continuar con este documento, asegúrese de tener los siguientes requisitos previos.
Ubuntu, Centos o MacOS. El soporte de Windows es experimental. Las siguientes instrucciones se centrarán solo en Linux y MacOS.
PYTHON - El servidor de modelos múltiples requiere que Python ejecute los trabajadores.
PIP - PIP es un sistema de gestión de paquetes de Python.
Java 8: el servidor de modelos múltiples requiere Java 8 para comenzar. Tiene las siguientes opciones para instalar Java 8:
Para Ubuntu:
sudo apt-get install openjdk-8-jre-headlessPara CentOS:
sudo yum install java-1.8.0-openjdkPara macOS:
brew tap homebrew/cask-versions
brew update
brew cask install adoptopenjdk8Paso 1: Configurar un entorno virtual
Recomendamos instalar y ejecutar servidor de modelos múltiples en un entorno virtual. Es una buena práctica ejecutar e instalar todas las dependencias de Python en entornos virtuales. Esto proporcionará aislamiento de las dependencias y facilitará la gestión de la dependencia.
Una opción es usar VirtualEnv. Esto se utiliza para crear entornos virtuales de Python. Puede instalar y activar un VirtualEnv para Python 2.7 de la siguiente manera:
pip install virtualenvLuego cree un entorno virtual:
# Assuming we want to run python2.7 in /usr/local/bin/python2.7
virtualenv -p /usr/local/bin/python2.7 /tmp/pyenv2
# Enter this virtual environment as follows
source /tmp/pyenv2/bin/activateConsulte la documentación de VirtualEnv para obtener más información.
Paso 2: instalar MXNET MMS no instalará el motor MXNET de forma predeterminada. Si aún no está instalado en su entorno virtual, debe instalar uno de los paquetes MXNET PIP.
Para la inferencia de la CPU, se recomienda mxnet-mkl . Instálelo de la siguiente manera:
# Recommended for running Multi Model Server on CPU hosts
pip install mxnet-mkl Para la inferencia de GPU, se recomienda mxnet-cu92mkl . Instálelo de la siguiente manera:
# Recommended for running Multi Model Server on GPU hosts
pip install mxnet-cu92mklPaso 3: Instale o actualice MMS de la siguiente manera:
# Install latest released version of multi-model-server
pip install multi-model-server Para actualizar desde una versión anterior de multi-model-server , consulte el documento de referencia de migración.
Notas:
model-archiver con MMS como dependencia. Consulte el Archiver de modelo para obtener más opciones y detalles. Una vez instalado, puede obtener el servidor de modelos MMS en funcionamiento muy rápidamente. Pruebe --help para ver todas las opciones de CLI disponibles.
multi-model-server --helpPara este inicio rápido, saltaremos la mayoría de las funciones, pero asegúrese de echar un vistazo a los documentos completos del servidor cuando esté listo.
Aquí hay un ejemplo fácil para servir a un modelo de clasificación de objetos:
multi-model-server --start --models squeezenet=https://s3.amazonaws.com/model-server/model_archive_1.0/squeezenet_v1.1.marCon el comando ejecutado anteriormente, tiene MMS ejecutándose en su host, escuchando solicitudes de inferencia. Tenga en cuenta que si especifica modelo (s) durante el inicio de MMS, escalará automáticamente los trabajadores de back -end al número igual a VCPUS disponible (si se ejecuta en instancia de CPU) o al número de GPU disponibles (si se ejecuta en instancia de GPU ). En el caso de los poderosos hosts con muchos recursos de cómputo (VCPU o GPU), este inicio y el proceso de autoscalado pueden tomar un tiempo considerable. Si desea minimizar el tiempo de inicio de MMS, puede intentar evitar registrarse y ampliar el modelo durante el tiempo de inicio y moverlo a un punto posterior utilizando las llamadas de API de administración correspondientes (esto permite el control de grano más fino a la cantidad de recursos que se asignan cualquier modelo en particular).
Para probarlo, puede abrir una nueva ventana de terminal junto a la que ejecuta MMS. Luego puede usar curl para descargar una de estas lindas imágenes de una bandera de gatito y curl -o lo nombrará kitten.jpg para usted. Luego, se curl una POST en el punto final de predecir MMS con la imagen del gatito.

En el siguiente ejemplo, proporcionamos un atajo para estos pasos.
curl -O https://s3.amazonaws.com/model-server/inputs/kitten.jpg
curl -X POST http://127.0.0.1:8080/predictions/squeezenet -T kitten.jpgEl punto final predicto devolverá una respuesta de predicción en JSON. Se verá como el siguiente resultado:
[
{
"probability" : 0.8582232594490051 ,
"class" : " n02124075 Egyptian cat "
},
{
"probability" : 0.09159987419843674 ,
"class" : " n02123045 tabby, tabby cat "
},
{
"probability" : 0.0374876894056797 ,
"class" : " n02123159 tiger cat "
},
{
"probability" : 0.006165083032101393 ,
"class" : " n02128385 leopard, Panthera pardus "
},
{
"probability" : 0.0031716004014015198 ,
"class" : " n02127052 lynx, catamount "
}
] Verá este resultado en la respuesta a su llamada curl al punto final de predicción, y en el servidor registra en la ventana del terminal que ejecuta MMS. También se está registrando localmente con métricas.
Se pueden descargar otros modelos del zoológico del modelo, así que pruebe algunos de esos también.
¡Ahora has visto lo fácil que puede ser servir un modelo de aprendizaje profundo con MMS! ¿Te gustaría saber más?
Para detener la instancia de servidor modelo ejecutiva actual, ejecute el siguiente comando:
$ multi-model-server --stopVerá la salida que especifica que el servidor de múltiples modelos se ha detenido.
MMS le permite empaquetar todos los artefactos de su modelo en un solo archivo de modelos. Esto hace que sea fácil compartir e implementar sus modelos. Para empaquetar un modelo, consulte la documentación del Archiver del Modelo
Explore al ReadMe de Docs para el índice completo de documentación. Esto incluye más ejemplos, cómo personalizar el servicio API, los detalles del punto final de la API y más.
Aquí hay algunas demostraciones de ejemplo de aplicaciones de aprendizaje profundo, impulsados por MMS:
Clasificación de revisión de productos 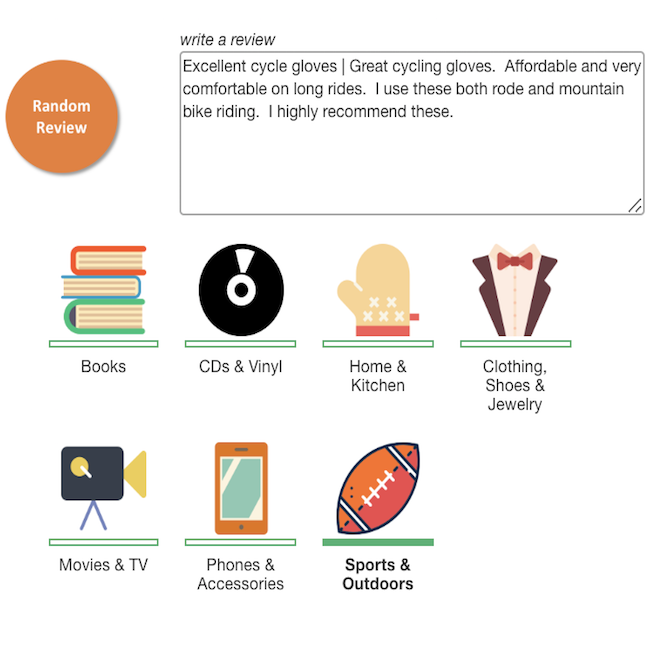 | Búsqueda visual 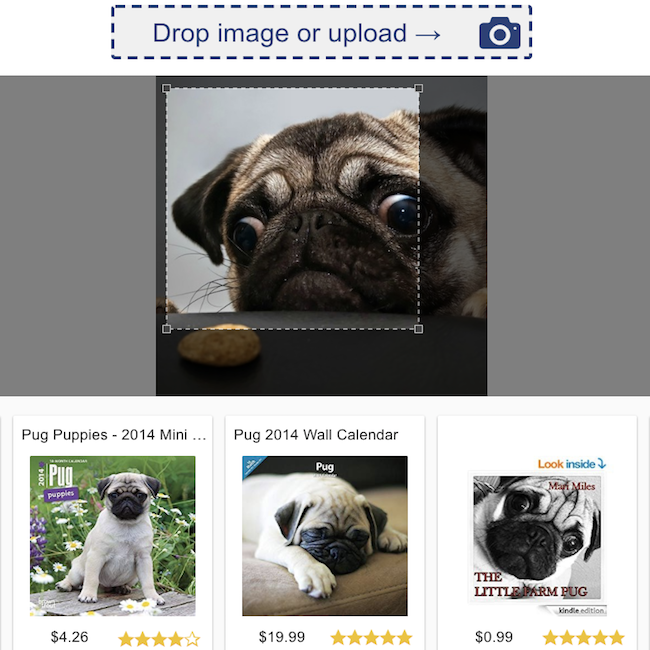 |
Reconocimiento de emociones faciales  | Transferencia de estilo neuronal  |
¡Agradecemos todas las contribuciones!
Para presentar un error o solicitar una función, por favor presente un problema de GitHub. Las solicitudes de extracción son bienvenidas.


