l2p
1.0.0
Esta base de código contiene la implementación de dos métodos de aprendizaje continuo:
L2P es una nueva técnica de aprendizaje continuo que aprende a impulsar dinámicamente un modelo previamente capacitado para que aprenda tareas secuencialmente bajo diferentes transiciones de tareas. A diferencia de los métodos basados en el ensayo o arquitectura principales, L2P no requiere ni un búfer de ensayo ni identidad de tarea de tiempo de prueba. L2P se puede generalizar a varios entornos de aprendizaje continuo, incluida la configuración degnóstica de tareas más desafiante y realista. L2P supera consistentemente a los métodos de última generación. Sorprendentemente, L2P logra resultados competitivos contra los métodos basados en el ensayo, incluso sin un amortiguador de ensayo.
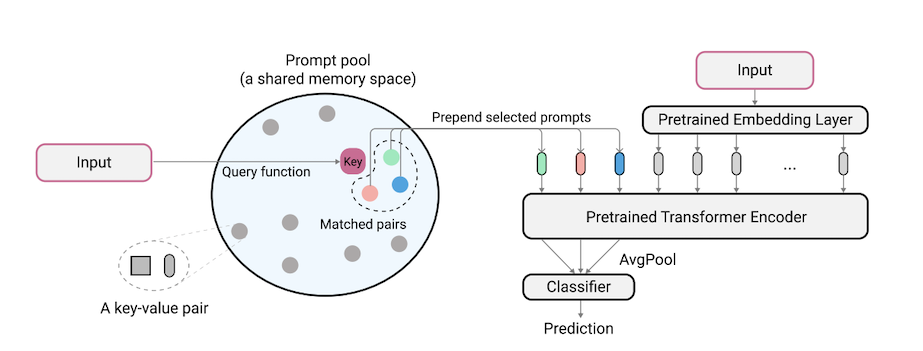
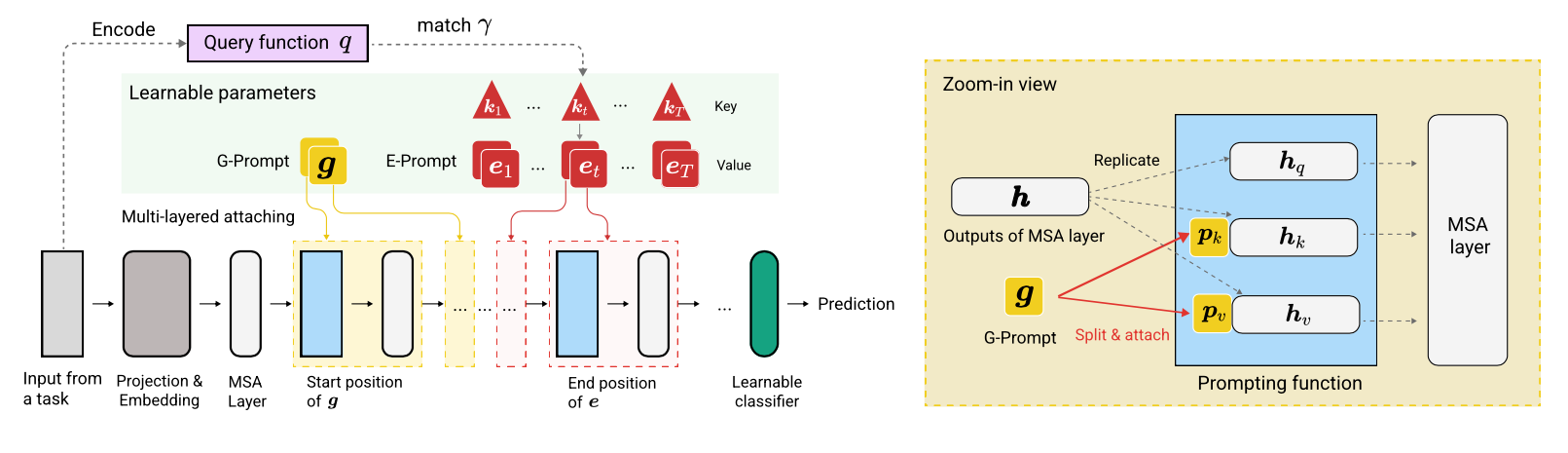
El código está escrito por Zifeng Wang. Reconocimiento a https://github.com/google-research/nested-transformer.
Este no es un producto de Google compatible oficialmente.
El punto de referencia Split ImageNet-R se basa en ImageNet-R dividiendo las 200 clases en 10 tareas con 20 clases por tarea, consulte libml/input_pipeline.py para obtener más detalles. Creemos que la división Imagenet-R es de gran importancia para la comunidad de aprendizaje continuo, por las siguientes razones:
La base de código ha sido reimplementada en Pytorch por Jaeho Lee en L2P-Pytorch y DualPrompt-Pytorch.
pip install -r requirements.txt
Después de esto, es posible que deba ajustar su versión de Jax de acuerdo con su versión de controlador CUDA para que Jax identifique correctamente sus GPU (consulte este problema para obtener más detalles).
Nota: La base de código se ha probado a través del entorno de TPU utilizando la versión más reciente de Jax. Actualmente estamos trabajando para verificar aún más el entorno de GPU.
Antes de ejecutar experimentos para 5-Datasets y Core50, se debe realizar un paso de preparación del conjunto de datos adicional de la siguiente manera:
"PATH_TO_CORE50" y "PATH_TO_NOT_MNIST" en libml/input_pipeline.py por las rutas de destino en el paso 2 El modelo VIT-B/16 utilizado en este documento se puede descargar aquí. Nota: Nuestra base de código en realidad admite varios tamaños de VITs. Si desea probar las variaciones de VIT, no dude en cambiar el config.model_name .
Proporcionamos el archivo de configuración para entrenar y evaluar L2P y DualPrompt en múltiples puntos de referencia en las configuraciones.
Para ejecutar L2P en conjuntos de datos de referencia:
python main.py --my_config configs/$L2P_CONFIG --workdir=./l2p --my_config.init_checkpoint=<ViT-saved-path/ViT-B_16.npz>
donde $L2P_CONFIG puede ser uno de los siguientes: [cifar100_l2p.py, five_datasets_l2p.py, core50_l2p.py, cifar100_gaussian_l2p.py] .
NOTA: Ejecutamos nuestros experimentos usando 8 GPU v100 o 4 TPU, y especificamos un tamaño por lotes por dispositivo de 16 en los archivos de configuración. Esto indica que usamos un tamaño de lote total de 128.
Para ejecutar DualPrompt en conjuntos de datos de referencia:
python main.py --my_config configs/$DUALPROMPT_CONFIG --workdir=./dualprompt --my_config.init_checkpoint=<ViT-saved-path/ViT-B_16.npz>
Donde $DUALPROMPT_CONFIG puede ser uno de los siguientes: [imr_dualprompt.py, cifar100_dualprompt.py] .
Usamos TensorBoard para visualizar el resultado. Por ejemplo, si el directorio de trabajo especificado para ejecutar L2P es workdir=./cifar100_l2p , el comando para verificar el resultado es el siguiente:
tensorboard --logdir ./cifar100_l2p
Estas son las métricas importantes para realizar un seguimiento y sus significados correspondientes:
| Métrico | Descripción |
|---|---|
| precisión_n | Precisión de la tarea n-th |
| olvidado | Olvidación promedio hasta la tarea actual |
| AVG_ACC | Precisión promedio de evaluación hasta la tarea actual |
@inproceedings{wang2022learning,
title={Learning to prompt for continual learning},
author={Wang, Zifeng and Zhang, Zizhao and Lee, Chen-Yu and Zhang, Han and Sun, Ruoxi and Ren, Xiaoqi and Su, Guolong and Perot, Vincent and Dy, Jennifer and Pfister, Tomas},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={139--149},
year={2022}
}
@article{wang2022dualprompt,
title={DualPrompt: Complementary Prompting for Rehearsal-free Continual Learning},
author={Wang, Zifeng and Zhang, Zizhao and Ebrahimi, Sayna and Sun, Ruoxi and Zhang, Han and Lee, Chen-Yu and Ren, Xiaoqi and Su, Guolong and Perot, Vincent and Dy, Jennifer and others},
journal={European Conference on Computer Vision},
year={2022}
}


