rl 6 nimmt
1.0.0
6 Nimmt! es un juego de cartas galardonado para dos a diez jugadores de 1994. Citando a Wikipedia:
El juego tiene 104 cartas, cada una con un número y símbolos de la cabeza de uno a Seven Bull que representan puntos de penalización. Se juega una ronda de diez turnos donde todos los jugadores colocan una carta de su elección en la mesa. Las tarjetas colocadas están dispuestas en cuatro filas de acuerdo con las reglas fijas. Si se coloca en una fila que ya tiene cinco cartas, el jugador recibe esas cinco cartas, que cuentan como puntos de penalización que se totalizan al final de la ronda.
6 Nimmt! es un juego competitivo de información incompleta y una gran cantidad de estocasticidad. Jugar bien requiere un poco de planificación. El juego simultáneo se presta a los juegos y el farol, mientras que una estrategia a largo plazo es necesaria para evitar terminar en posiciones difíciles del juego final.
¡Implementamos una versión ligeramente simplificada de 6 NIMMT! como un entorno de gimnasio Operai. A diferencia del juego original, cuando se juega una carta más baja que la última carta en todas las pilas, el jugador no puede elegir libremente qué pila reemplazar, sino que siempre tomará la pila con el menor número de puntos de penalización.
Hasta ahora hemos implementado los siguientes agentes:
Como primera prueba, realizamos un torneo simple de sí mismo. Comenzando con cinco agentes no entrenados, jugamos 4000 juegos en total. Para cada juego seleccionamos al azar dos, tres o cuatro agentes para jugar (y aprender). Cada 400 juegos clonamos al agente con mejor rendimiento y expulsamos a algunos de los más pobres. Al final, solo mantuvimos la mejor instancia de cada tipo de agente.
Resultados sobre todos los juegos:
| Agente | Juegos jugados | Puntuación media | Ganar fracción | Elo |
|---|---|---|---|---|
| Alfa0.5 | 2246 | -7.79 | 0.42 | 1806 |
| MCS | 2314 | -8.06 | 0.40 | 1745 |
| Acer | 1408 | -12.28 | 0.18 | 1629 |
| D3qn | 1151 | -13.32 | 0.17 | 1577 |
| Aleatorio | 1382 | -13.49 | 0.19 | 1556 |
Así es como se desarrolló el rendimiento (medido en ELO) de los modelos durante el curso del torneo:
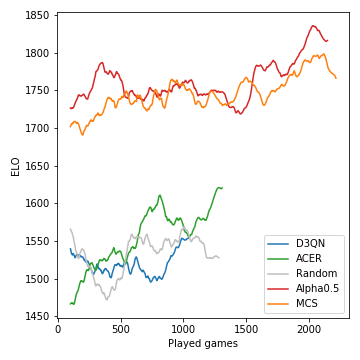
La búsqueda de árboles de Monte-Carlo es crucial y conduce a jugadores fuertes. Los agentes RL sin modelo, por otro lado, luchan por incluso superar claramente la línea de base aleatoria. Debido a la naturaleza estocástica del juego, las probabilidades ganadoras y las diferencias ELO no son tan drásticas como podrían ser, digamos, para el ajedrez. Tenga en cuenta que no hemos ajustado ninguno de los muchos hiperparámetros.
Después de esta fase de autoestima, el agente Alpha0.5 se enfrentó a Merle, uno de los mejores 6 NIMMT! Jugadores en nuestro grupo de amigos, por 5 juegos. Estos son los puntajes:
| Juego | 1 | 2 | 3 | 4 | 5 | Suma |
|---|---|---|---|---|---|---|
| Mirlo | -10 | -16 | -11 | -3 | -4 | -44 |
| Alfa0.5 | -1 | -3 | -14 | -8 | -6 | -32 |
Suponiendo que tiene instalado Anaconda, clone el repositorio con
git clone [email protected]:johannbrehmer/rl-6nimmt.git
y crear un entorno virtual con
conda env create -f environment.yml
conda activate rl
Tanto el juego de auto-juego y los juegos entre un jugador humano y agentes entrenados se demuestran en Simple_Tournament.ipynb.
Reunidos por Johann Brehmer y Marcel Gutsche.


