kubeai
helm-chart-models-0.9.0
Obtenga la infección en Kubernetes: LLMS, Incrustos, Speech-to-Text.
✅️ Reemplazo de entrega para OpenAI con compatibilidad de API
⚖️ Escala de cero, Autoscale basado en la carga
? Servir modelos de generación de texto (LLMS, VLMS, etc.)
API de discurso a texto
? API de incrustación/vector
Multiplataforma: solo CPU, GPU, TPU
? Garado en caché del modelo con sistemas de archivos compartidos (EFS, Filestore, etc.)
Dependencias cero (no depende de istio, knative, etc.)
Chat UI incluida (OpenWebui)
? Opera servidores de modelos OSS (VLLM, Ollama, más rápido, infinito)
✉ Inferencia de transmisión/lotes a través de integraciones de mensajería (Kafka, PubSub, etc.)
Citas de la comunidad:
Solución reutilizable y bien abstracta para ejecutar LLMS - Mike Ensor
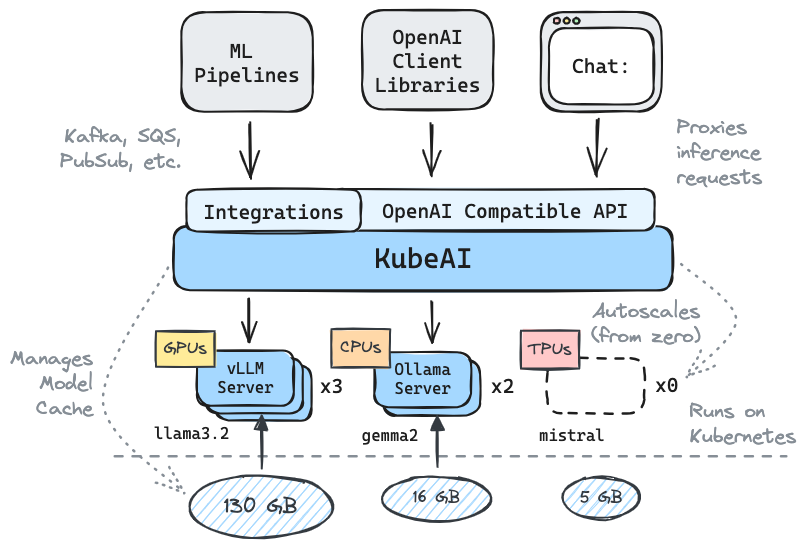
Kubeai sirve una API HTTP compatible con OpenAI. Los administradores pueden configurar modelos ML a través de kind: Model Kubernetes Recursos personalizados. Kubeai puede considerarse como un operador modelo (ver patrón de operador) que administra los servidores VLLM y Ollama.
Cree un clúster local usando Kind o Minikube.
# You might need to stop and remove the existing machine:
podman machine stop
podman machine rm
# Init and start a new machine:
podman machine init --memory 6144 --disk-size 120
podman machine startkind create cluster # OR: minikube startAgregue el repositorio del timón Kubeai.
helm repo add kubeai https://www.kubeai.org
helm repo updateInstale Kubeai y espere a que todos los componentes estén listos (puede tomar un minuto).
helm install kubeai kubeai/kubeai --wait --timeout 10mInstale algunos modelos predefinidos.
cat << EOF > kubeai-models.yaml
catalog:
gemma2-2b-cpu:
enabled: true
minReplicas: 1
qwen2-500m-cpu:
enabled: true
nomic-embed-text-cpu:
enabled: true
EOF
helm install kubeai-models kubeai/models
-f ./kubeai-models.yamlAntes de progresar a los siguientes pasos, comience un reloj en las vainas en una terminal independiente para ver cómo Kubeai despliega modelos.
kubectl get pods --watch Debido a que establecemos minReplicas: 1 para el modelo Gemma, debería ver una vaina modelo que ya aparece.
Comience un puerto local hacia adelante a la interfaz de usuario de chat agrupada.
kubectl port-forward svc/openwebui 8000:80Ahora abra su navegador a Localhost: 8000 y seleccione el modelo Gemma para comenzar a chatear.
Si vuelve al navegador y comienza una conversación con Qwen2, notará que tomará un tiempo responder al principio. Esto se debe a que establecemos minReplicas: 0 para este modelo y Kubeai necesita girar un nuevo POD (puede verificar con kubectl get models -oyaml qwen2-500m-cpu ).
Consulte nuestra documentación en kubeai.org para encontrar información sobre:
Lista de adoptantes conocidos:
| Nombre | Descripción | Enlace |
|---|---|---|
| Telescopio | El telescopio utiliza kubeai para la inferencia LLM de lotes a gran escala múltiple. | TryTelescope.ai |
| Google Cloud Distributed Edge | Kubeai se incluye como una arquitectura de referencia para inferencias en el borde. | LinkedIn, Gitlab |
| Lambda | Puedes probar Kubeai en la nube de desarrolladores de Lambda AI. Vea el tutorial y el video de Lambda. | Lambda |
Si está utilizando Kubeai y desea que se enumere como adoptante, haga un PR.
# Implemented #
/v1/chat/completions
/v1/completions
/v1/embeddings
/v1/models
/v1/audio/transcriptions
# Planned #
# /v1/assistants/*
# /v1/batches/*
# /v1/fine_tuning/*
# /v1/images/*
# /v1/vector_stores/* Nota: Kubeai nació de un proyecto llamado Lingo, que era un simple proxy de Kubernetes LLM con autoscalaje básico. Relanzamos el proyecto como Kubeai (finales de agosto de 2024) y ampliamos la hoja de ruta a lo que es hoy.
? ¡No olvides dejarnos una estrella en Github y seguir el repositorio para mantenerte al día!
Háganos saber sobre las características que está interesado en ver o comunicarse con preguntas. ¡Visite nuestro canal Discord para unirse a la discusión!
O simplemente comuníquese con LinkedIn si desea conectarse:


