ChatIE
1.0.0
Repositorio oficial del documento "Extracción de información de disparo cero a través del chat con chatgpt". ¡Estrata, mira y bifurca nuestro repositorio para las actualizaciones activas!
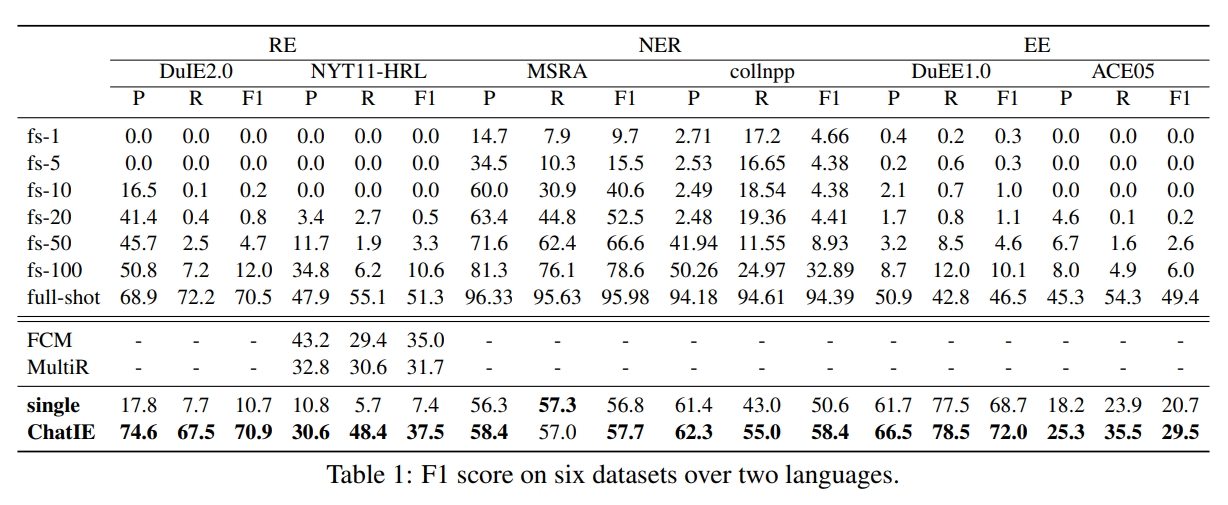
La extracción de información de disparo cero (es decir) tiene como objetivo construir sistemas IE a partir del texto no anotado. Es un desafío debido a que involucra poca intervención humana. Desafiante pero valioso, IE, IE, reduce el tiempo y el esfuerzo que toma el etiquetado de datos. Los esfuerzos recientes en modelos de idiomas grandes (LLMS, EG, GPT3, CHATGPT) muestran un rendimiento prometedor en configuraciones de disparo cero, inspirándonos así a explorar métodos rápidos. En este trabajo, preguntamos si los modelos de IE fuertes se pueden construir mediante la provisión directa de LLM. Específicamente, transformamos la tarea de IE de disparo cero en un problema de preguntas de múltiples vueltas con un marco de dos etapas (Chatie). Con el poder de CHATGPT, evaluamos ampliamente nuestro marco en tres tareas de IE: Entityrelation Triple Extract, nombrado reconocimiento de entidades y extracción de eventos. Los resultados empíricos en seis conjuntos de datos en dos idiomas muestran que Chatie logra un rendimiento impresionante e incluso supera algunos modelos de disparo completo en varios conjuntos de datos (por ejemplo, NYT11-HRL). Creemos que nuestro trabajo podría arrojar luz sobre la construcción de modelos IE con recursos limitados.
零样本信息抽取( Extracción de información, es decir, )旨在从无标注文本中建立 系统 系统 , 因为很少涉及人为干预 该问题非常具有挑战性。但零样本 该问题非常具有挑战性。但零样本 该问题非常具有挑战性。但零样本 不再需要标注数据时耗费的时间和人力 不再需要标注数据时耗费的时间和人力, 因此十分重要。近来的大规模语言模型(例如 gpt-3 , chat gpt )在零样本设置下取得了很好的表现 , 这启发我们探索基于提示的方法来解决零样本 这启发我们探索基于提示的方法来解决零样本 任务。我们提出一个 任务。我们提出一个问题 : 不经过训练来实现零样本信息抽取是否可行?我们将零样本 不经过训练来实现零样本信息抽取是否可行?我们将零样本 任务转变为一个两阶段框架的多轮问答问题( chat, es decir,)) 并在三个 : : : 实体 实体 实体 实体 实体 实体 实体 实体 实体 实体 实体 实体 实体.关系三元组抽取、命名实体识别和事件抽取。在两个语言的 6 个数据集上的实验结果表明 , Chat, es decir, 取得了非常好的效果 甚至在几个数据集上(例如 甚至在几个数据集上(例如 nyt11-hrl)上超过了全监督模型的表现。我们的工作能够为有限资源下 es decir, 系统的建立奠定基础。
ACTUALIZACIÓN: Usamos la API oficial, ¡la herramienta se vuelve más más rápida! Si la clave excede los límites, dígenos.
Aviso: la velocidad de respuesta depende de la API oficial de OpenAI CHATGPT. (A veces, el funcionario está demasiado lleno y la velocidad será lenta o el chatgpt se sobrecargará). Además, es mejor que use su propia clave OpenAI porque si varias personas usan nuestra cuenta predeterminada al mismo tiempo, la cuenta puede ser sobrecargado.
AVISO: Debido a que la API oficial no está disponible en nacional, por lo que usamos API de RevChatGPT y la versión V1. Pero es demasiado lento , por lo que le recomendamos que use la herramienta fuera de línea para estudiar. Actualizaremos la API aún más en el futuro ( TODO ).
También proporcionamos una herramienta IE basada en GPT3.5, puede ver en GPT4IE
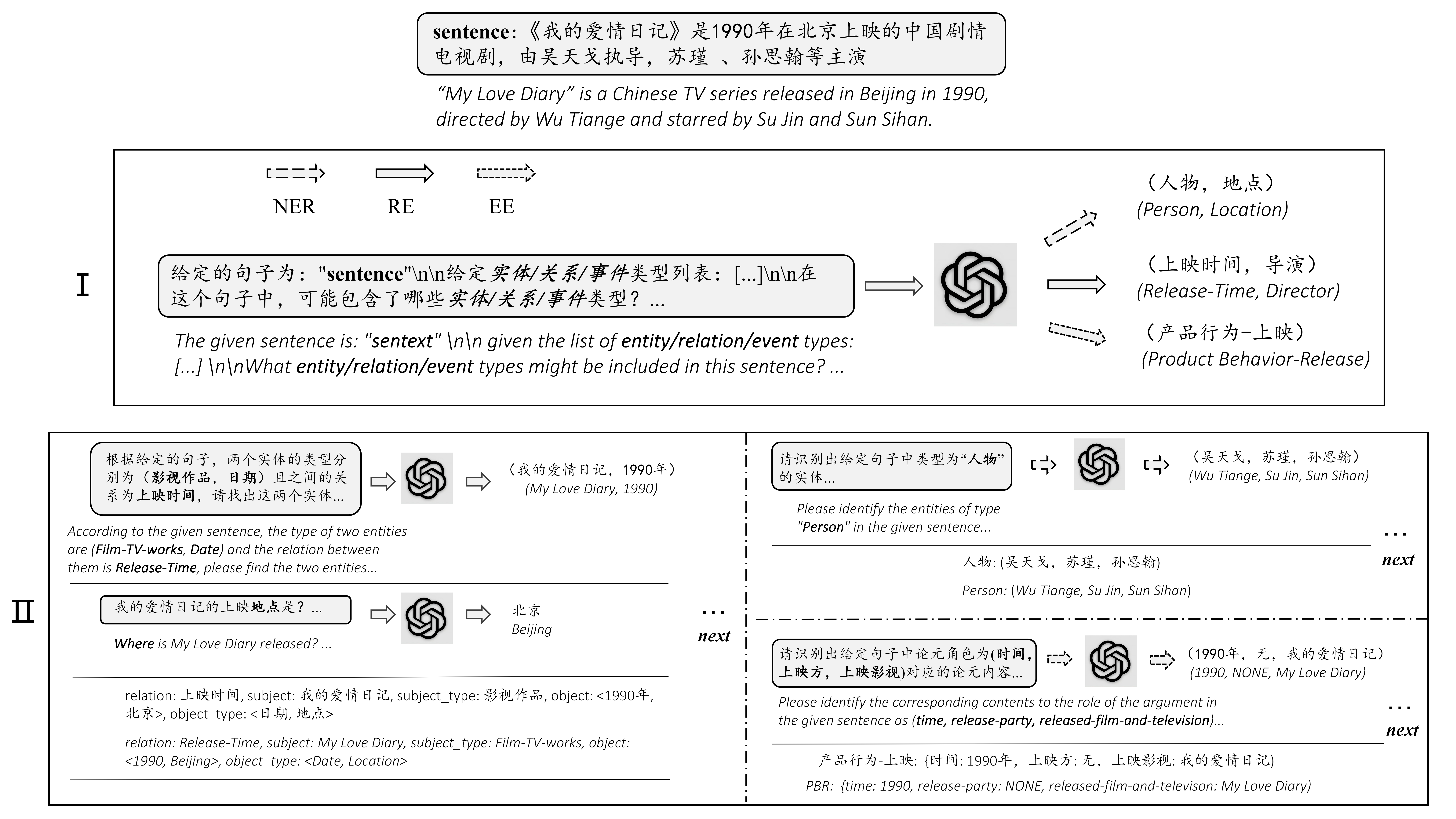
Chatie (extracción de información de disparo cero a través de chat con chatgpt) es una demostración de herramienta de IE de código abierto y poderosa. Mejorada por ChatGPT y su solicitud, tiene como objetivo extraer automáticamente información estructurada de una oración en bruto y hacer un valioso análisis en profundidad de la oración de entrada. Aprovechar información estructurada valiosa ayuda a las corporaciones a tomar decisiones incisivas y de mejora de los negocios. 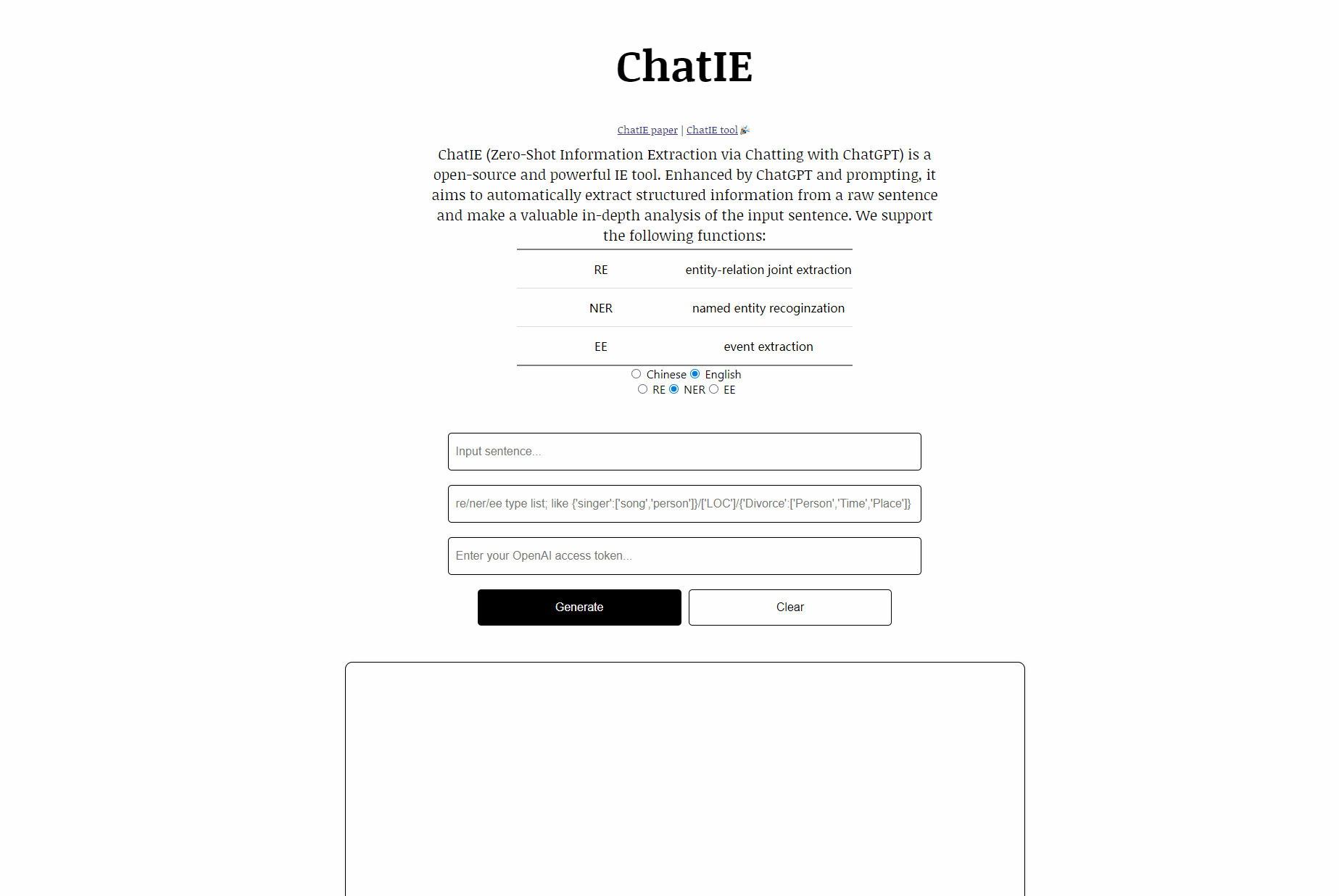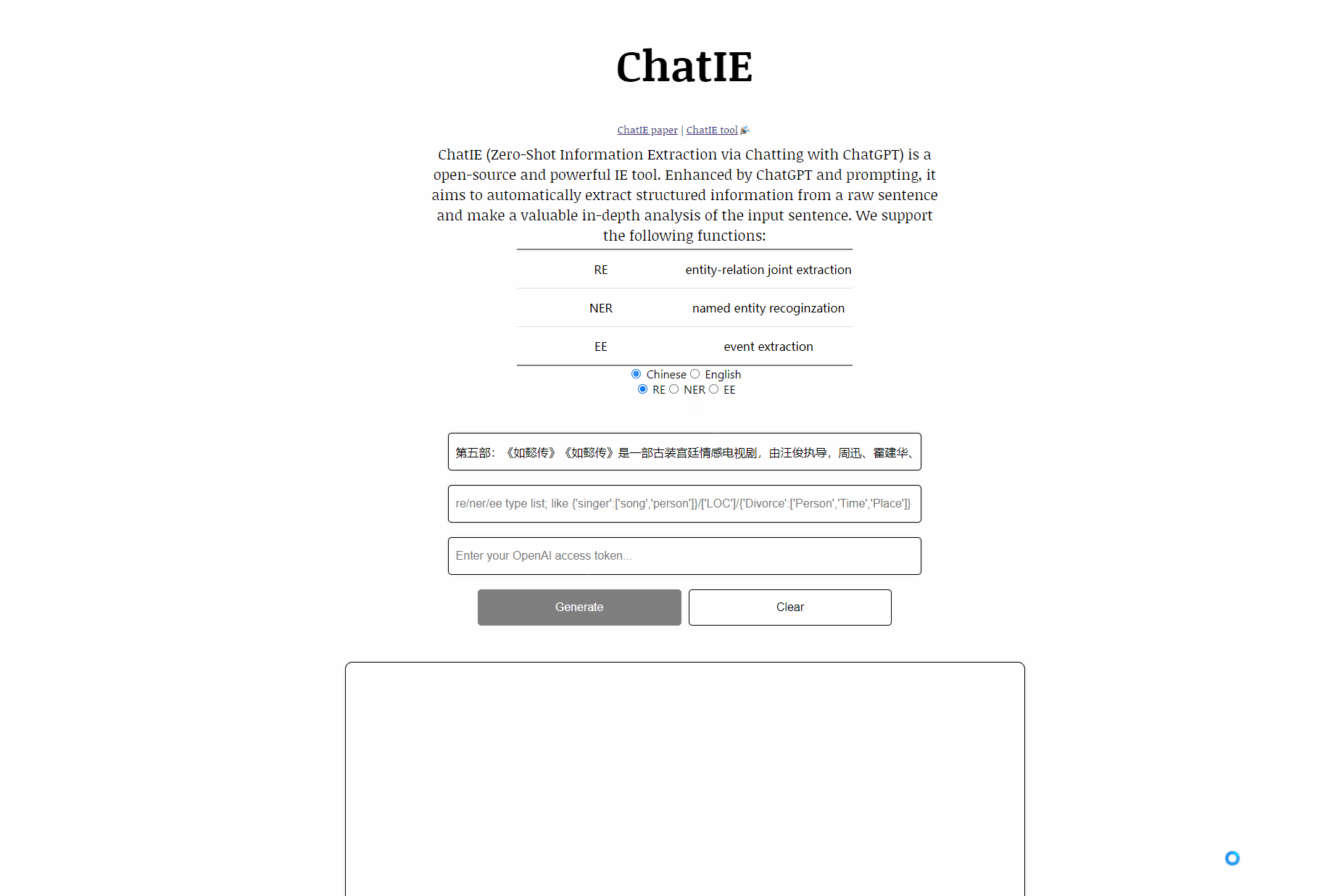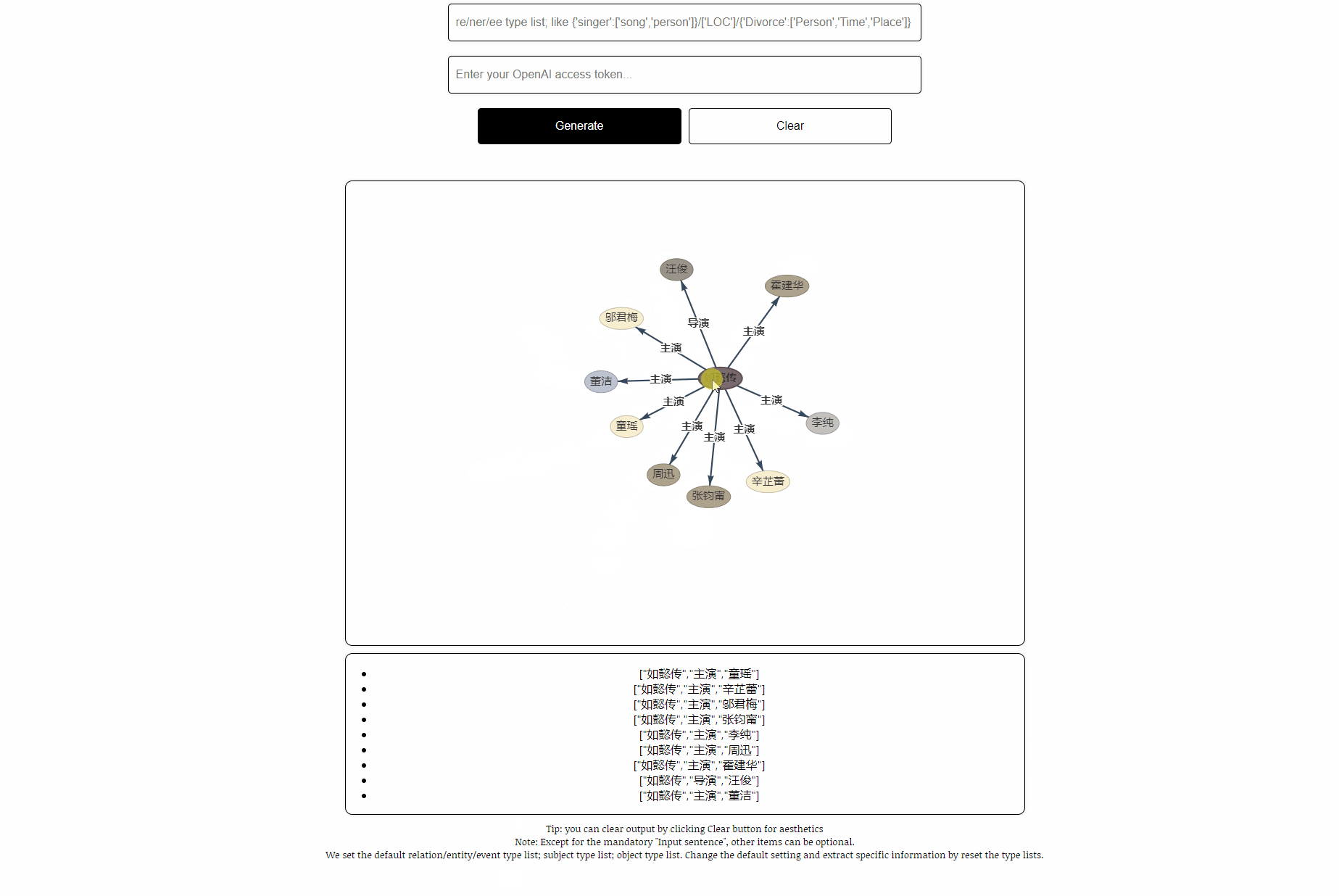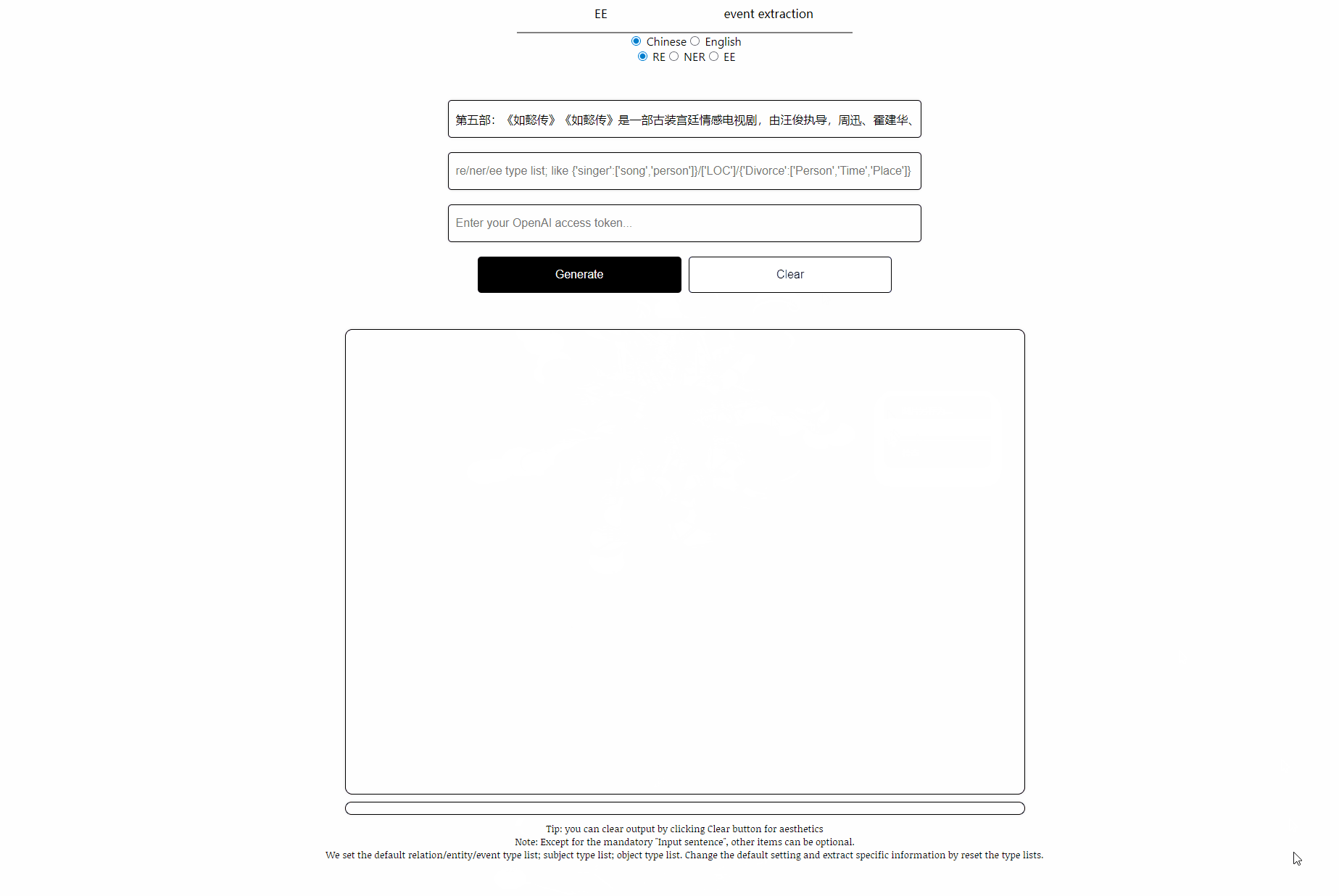
Apoyamos las siguientes funciones:
| Tarea | Nombre | Lauguaces |
|---|---|---|
| RE | extracción de articulación de la relación entre entidad | Chino, inglés |
| Ner | Recoginzación de entidad nombrada | Chino, inglés |
| EE | extracción de eventos | Chino, inglés |
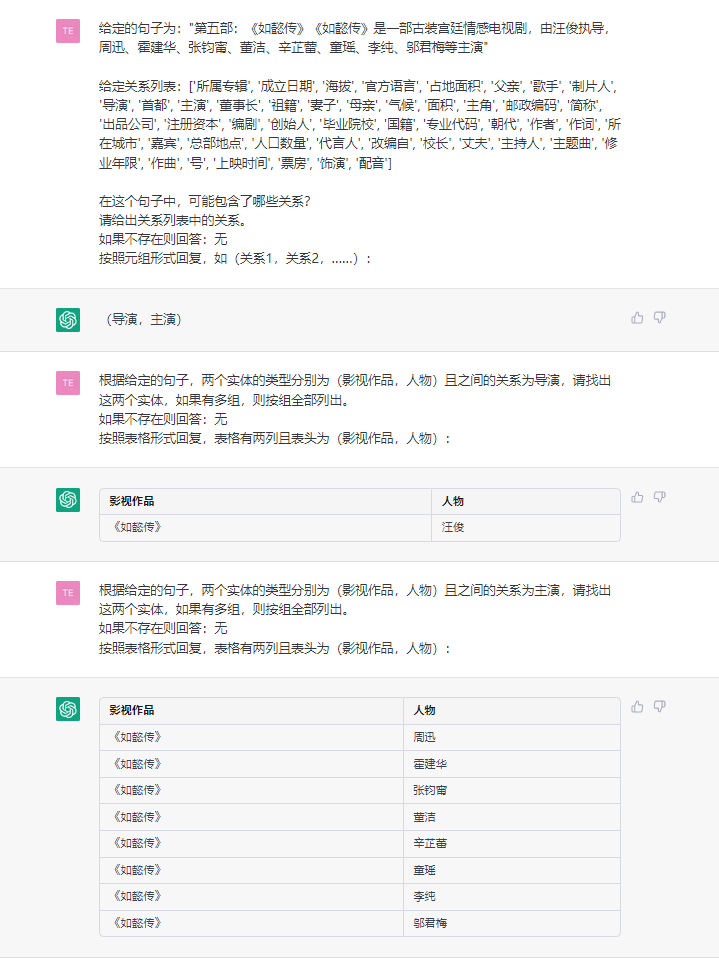
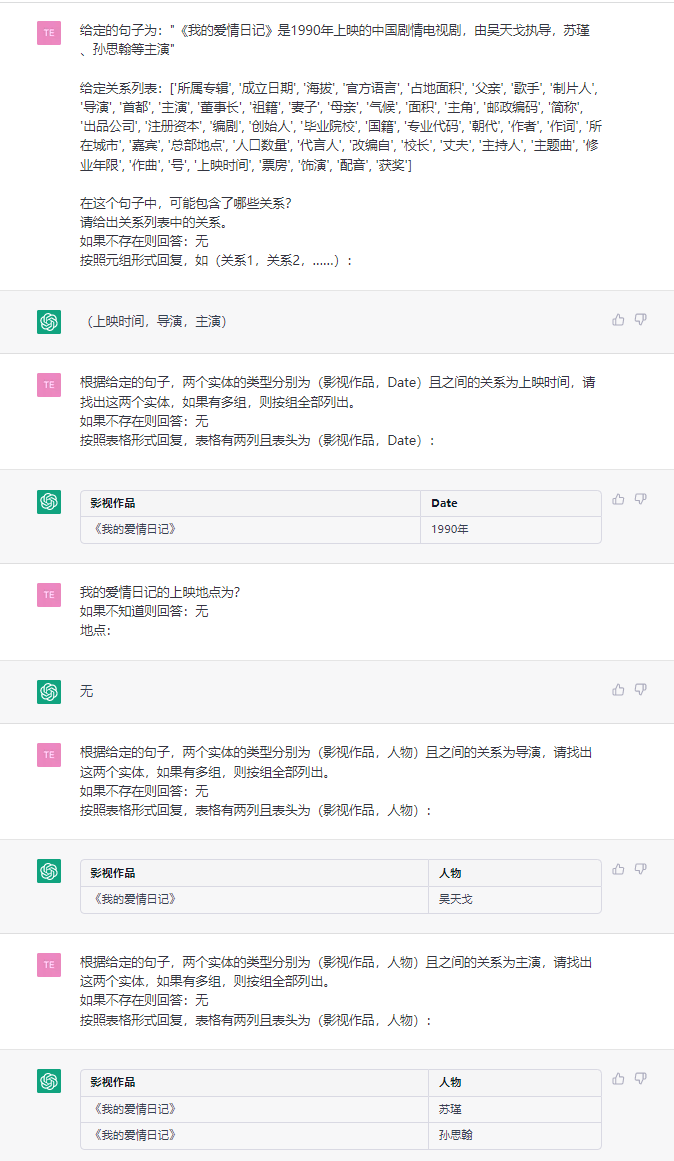
Esta tarea tiene como objetivo extraer triples de textos planos, como (China, Capital, Beijing) , (《如懿传》, 主演, 周迅) .
PD: * Denote Opcional, establecemos el valor predeterminado para ellos. Pero para una mejor extracción, debe especificar la lista tres de acuerdo con los escenarios de la aplicación.
Sentencia: otros cuatro ejecutivos de Google, el director financiero, George Reyes; el vicepresidente senior de operaciones comerciales, Shona Brown; el director legal, David Drummond; Y el vicepresidente senior de gestión de productos, Jonathan Rosenberg obtuvo salarios de $ 250,000 cada uno.
rtl: predeterminado, consulte el archivo "tipos predeterminados"
outtut: 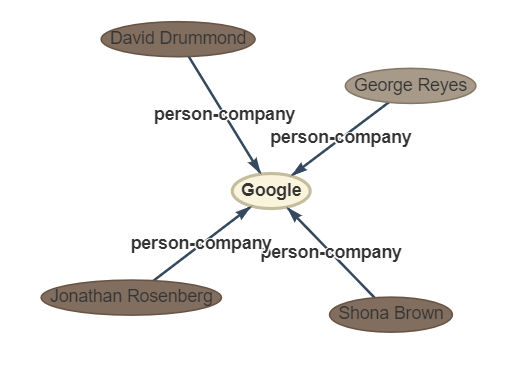
Frase: : : 《如懿传》《如懿传》是一部古装宫廷情感电视剧 , 由汪俊执导 周迅、霍建华、张钧甯、董洁、辛芷蕾、童瑶、李纯、邬君梅等主演。
rtl: predeterminado, consulte el archivo "tipos predeterminados"
outtut: 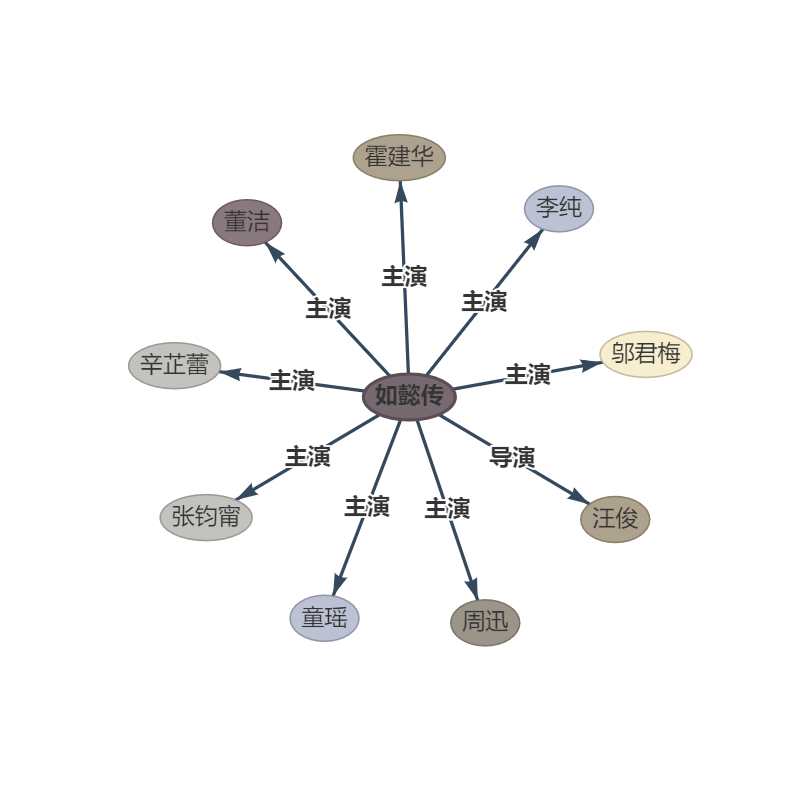
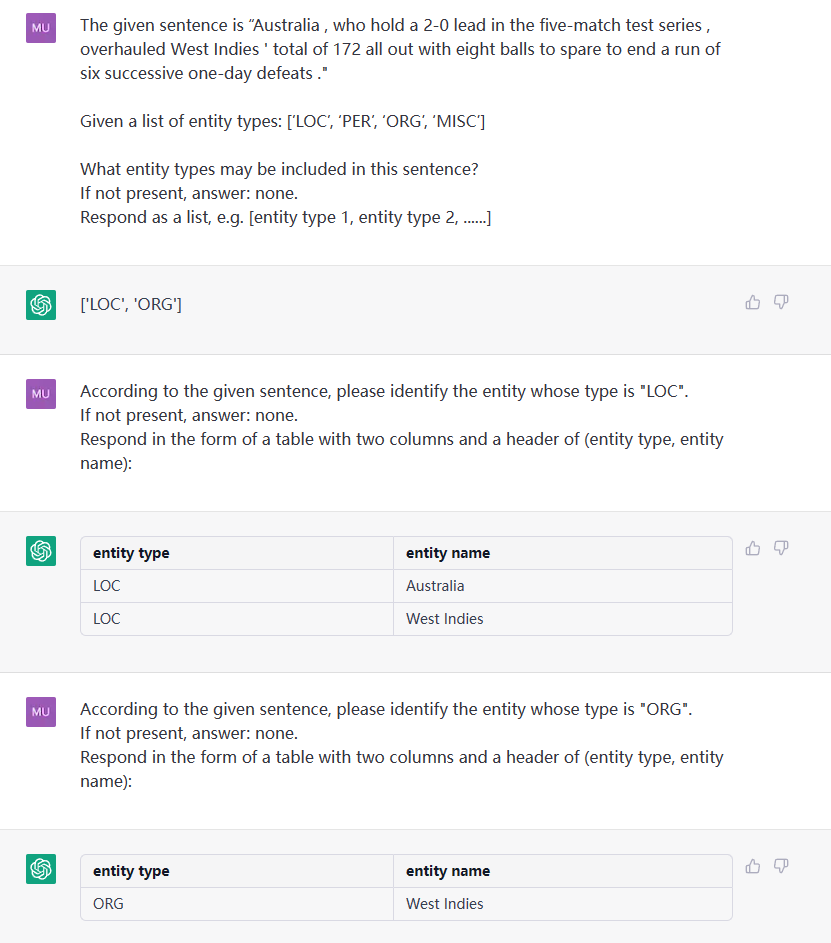
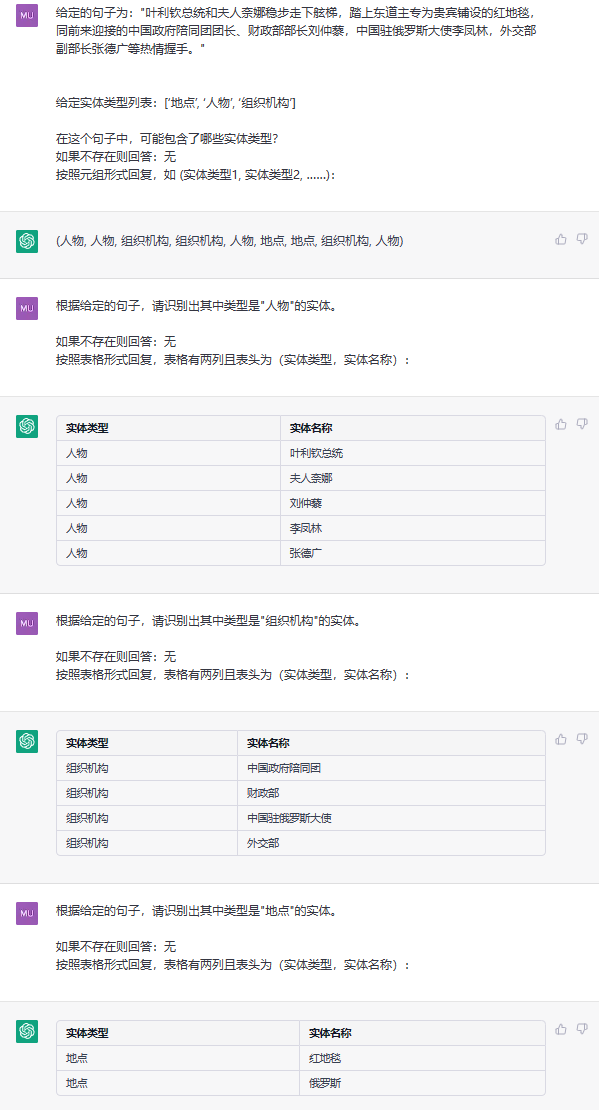
Esta tarea tiene como objetivo extraer entidades de textos planos, como (loc, beijing) , (人物, 周恩来) .
Frase: James trabajó para Google en Beijing, la capital de China. ETL: ['Loc', 'Misc', 'Org', 'Per']
outtut: 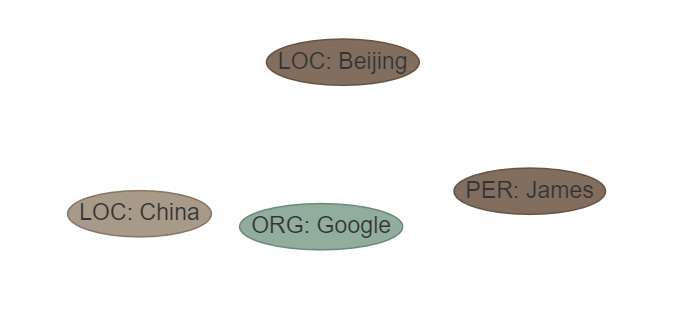
oración:中国 共产党创立于中华民国大陆时期 , 由陈独秀和李大钊领导组织。
ETL: ['组织机构', '地点', '人物']
outtut: 
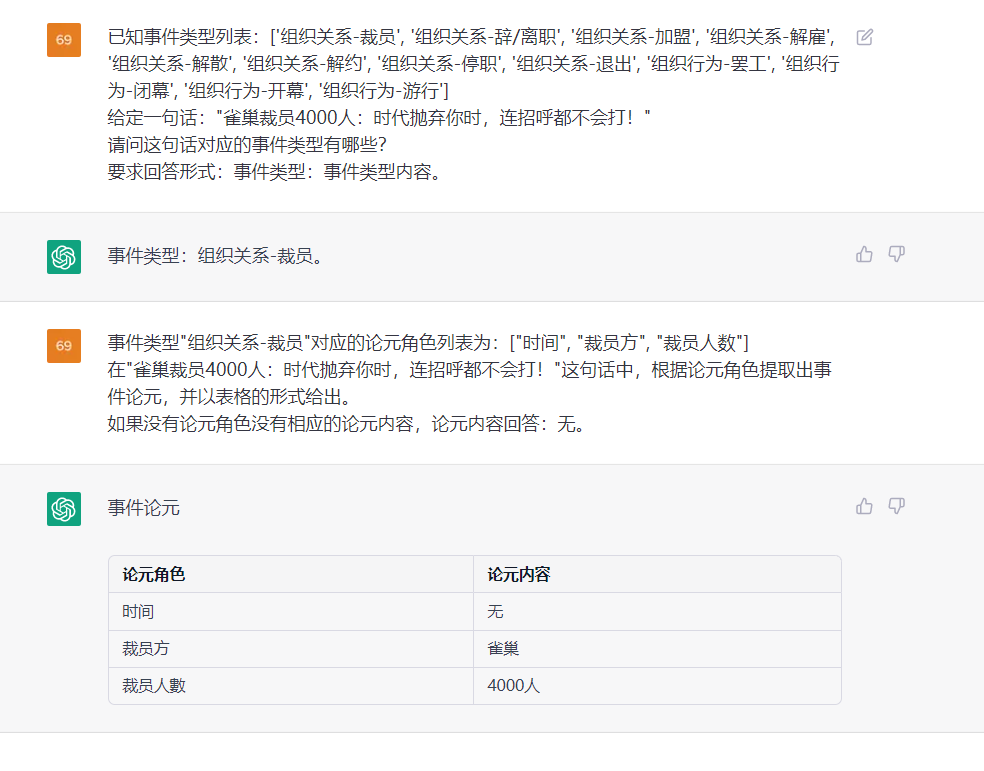
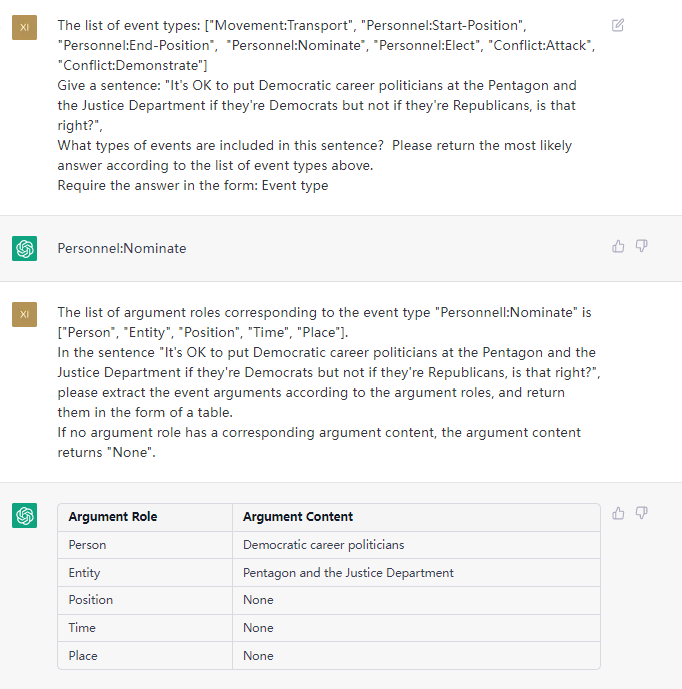
Esta tarea tiene como objetivo extraer el evento de los textos sin formato, como {Life-Divorce: {Person: Bob, Time: Today, Place: America}}, {竞赛行为-晋级: {时间: 无, 晋级方: 西北狼, 晋级赛事: 中甲榜首之争}} .
Frase: ayer Bob y su esposa se divorciaron en Guangzhou.
ETL: predeterminado, consulte el archivo "tipos predeterminados"
outtut: 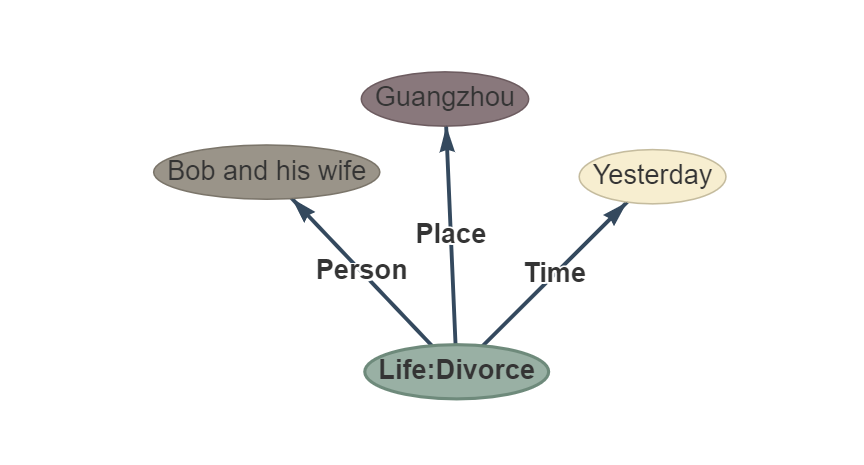
Frase:在 2022 年卡塔尔世界杯决赛中 , 阿根廷以点球大战险胜法国。
ETL: predeterminado, consulte el archivo "tipos predeterminados"
outtut: 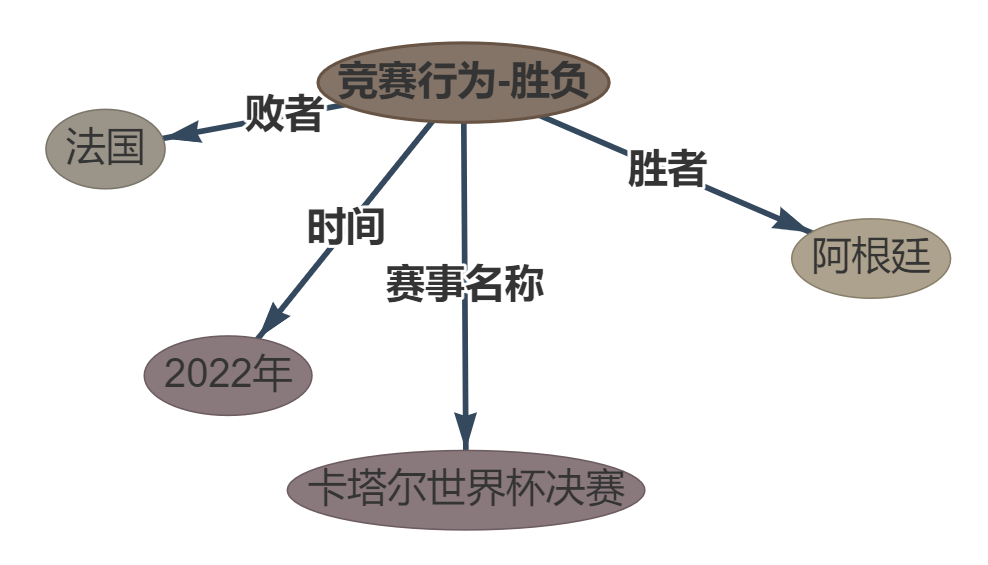
reaccionar+frasco
front-end y ejecutar npm install para descargar las dependencias requeridas.npm run start . Chatie debe abrirse en una nueva pestaña del navegador.back-end y ejecutar python run.py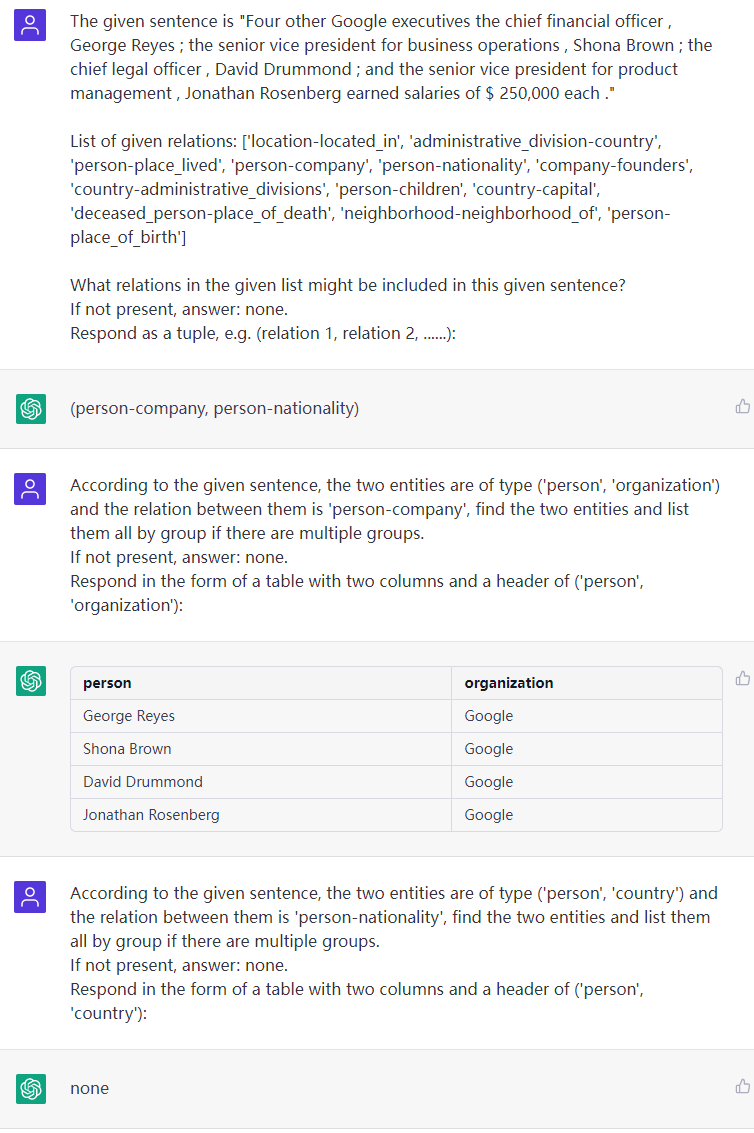
Estamos comprometidos a mejorar nuestro proyecto y proporcionarle la mejor experiencia posible. Para lograr esto, recopilaremos sus datos para ayudarnos a comprender cómo interactúa con nuestro proyecto e identificar áreas para mejorar. Valoramos la privacidad y la seguridad de sus datos y aseguramos los datos solo para mejorar nuestro proyecto.
Vea este documento ARXIV: 2302.10205
@article{wei2023zero,
title={Zero-Shot Information Extraction via Chatting with ChatGPT},
author={Wei, Xiang and Cui, Xingyu and Cheng, Ning and Wang, Xiaobin and Zhang, Xin and Huang, Shen and Xie, Pengjun and Xu, Jinan and Chen, Yufeng and Zhang, Meishan and others},
journal={arXiv preprint arXiv:2302.10205},
year={2023}
}


