Reading_groups
1.0.0
El poder de la computación : una gran cantidad de evidencia muestra que los avances en el aprendizaje automático están impulsados en gran medida por la computación, no la investigación, consulte "La lección amarga", y a menudo hay fenómenos de emergencia y homogeneización. Los estudios han demostrado que el uso de la informática de inteligencia artificial se duplica aproximadamente cada 3.4 meses, mientras que la mejora de la eficiencia solo se duplica cada 16 meses. Entre ellos, la cantidad de cálculo está impulsada principalmente por la potencia informática, mientras que la eficiencia es impulsada por la investigación. Esto significa que el crecimiento de la computación ha dominado históricamente los avances en el aprendizaje automático y sus subcampos. Esto se demuestra aún más por la aparición de GPT-4. A pesar de esto, todavía debemos prestar atención a si habrá una arquitectura más subvertida en el futuro, como S4. La mayoría de los puntos de acceso de investigación de la PNL actual se basan en LLM más avanzado (~ 100B,
Para obtener más documentos de temas de LLM, consulte aquí y aquí.
Documentos ( categoría aproximada )
recurso
【Pruebas en GPT-4, Limitación】 chispas de inteligencia general artificial: experimentos tempranos con GPT-4
【Documentos de instrucciones, incluidos SFT, PPO, etc., uno de los artículos más importantes】 Modelos de lenguaje de capacitación para seguir las instrucciones con comentarios humanos
【Supervisión escalable: ¿Cómo pueden los humanos continuar mejorando sus modelos después de que sus modelos superen sus propias tareas? 】 Medir el progreso en supervisión escalable para modelos de idiomas grandes
【Definición de alineación, producida por DeepMind】 Alineación de agentes del lenguaje
Un asistente general de idiomas como laboratorio para la alineación
[Documento retro, modelo buscado usando CCA+] Mejora de modelos de lenguaje recuperando de billones de tokens
Modelos lingüísticos de ajuste de las preferencias humanas
Capacitar a un asistente útil e inofensivo con refuerzo aprendiendo de comentarios humanos
【Modelo grande en chino e inglés, excediendo GPT-3】 GLM-130B: un modelo pre-capacitado bilingüe abierto
【Optimización del objetivo previo al entrenamiento】 UL2: unificadores de paradigmas de aprendizaje de idiomas
【¿Nuevos puntos de referencia de alineación, bibliotecas de modelos y nuevos métodos】 es el aprendizaje de refuerzo (no) para el procesamiento del lenguaje natural?: Puntos de referencia, líneas de base y bloques de construcción para la optimización de políticas de lenguaje natural
【MLM sin las etiquetas [máscara] a través de la tecnología】 Deficiencia de representación en el modelado de lenguaje enmascarado
【Texto a la capacitación de imágenes alivia las necesidades del vocabulario y resiste ciertos ataques】 Modelado de idiomas con píxeles
LEXMAE: Pretratenamiento con cuello de léxico para la recuperación a gran escala
Incoder: un modelo generativo para el relleno y síntesis de código
[Buscar imágenes relacionadas con el texto para el modelo de planificación de lenguaje] Modelado de idiomas visualmente acuático
Un modelo lingüístico autointriminante no monotónico
【Comparación y ajuste de retroalimentación negativa a través del diseño de propt】 La cadena de visión retrospectiva alinea los modelos de lenguaje con retroalimentación
【Modelo de gorrión】 Mejora de la alineación de los agentes de diálogo a través de juicios humanos específicos
[Use parámetros de modelo pequeños para acelerar el proceso de entrenamiento del modelo grande (no a partir de cero)] Aprender a cultivar modelos previos a la pretrada para un entrenamiento de transformadores eficientes
[Modelo de fusión de conocimiento semi-paramétrico para múltiples fuentes de conocimiento] Conocimiento en contexto: hacia modelos de lenguaje semi-paramétrico expertos
【Método de fusión para fusionar múltiples modelos capacitados en diferentes conjuntos de datos】 Fusión de conocimiento de la datos mediante la fusión de los pesos de los modelos de idiomas
[Es muy inspirador que el mecanismo de búsqueda reemplace la arquitectura general de FFN en Transformer (× 2.54 Time) para desacoplar el conocimiento almacenado en parámetros del modelo] Modelo de lenguaje con memoria de Knowldge enchufable
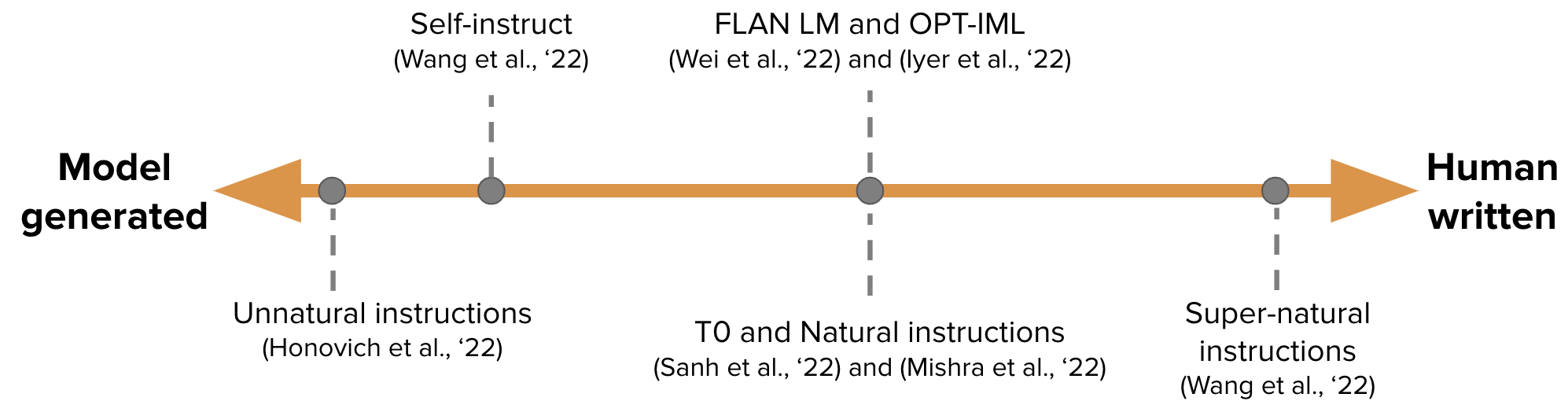
【Genere automáticamente los datos de ajuste de instrucciones para la capacitación GPT-3】 Autoinstrucción de la autoinstrucción: alineación del modelo de lenguaje con instrucciones auto-generadas
- 
Hacia modelos de lenguaje enmascarado dependientes de condicionalmente
【Calibro iterativamente calibrado imperfectamente correctores independientes, el artículo de seguimiento de Sean Welleck】 Generación de secuencias aprendiendo a autocorrección
[Aprendizaje continuo: Agregue un PropT para la nueva tarea, y el propt de la tarea anterior y el gran modelo siguen sin cambios] Invitaciones progresivas: aprendizaje continuo para modelos de idiomas sin olvidar
[EMNLP 2022, Actualización continua del modelo] MEMPROMPT: edición de solicitud asistida por memoria con comentarios de los usuarios
【Nueva arquitectura neural (Folnet), que contiene sesgo de inducción lógica de primer orden】 Representaciones de lenguaje de aprendizaje con sesgo inductivo lógico
GANLM: Presadrina del codificador codificador con un discriminador auxiliar
【Modelo de lenguaje previo al ejercicio basado en modelos de espacio de estado, superando a Bert】 Pretratiamiento sin atención
[Considere la retroalimentación humana durante la capacitación previa] modelos lingüísticos previos a la altura con preferencias humanas
[Modelo de Llama de código abierto de Meta, 7B-65B, entrena modelos pequeños más etiquetados de lo habitual, logre un rendimiento óptimo bajo varios presupuestos de inferencia] Llama: modelos de idiomas de base abiertos y eficientes
[Enseñar modelos de idiomas grandes para autodesbug y explicar el código generado a través de un pequeño número de ejemplos, pero se han utilizado así ahora] enseñando modelos de idiomas grandes a autodesbug
¿Qué tan lejos pueden llegar los camellos?
Lima: menos es más para la alineación
【Árbol de pensamiento, cada vez más como AlphaGo】 Resolución de problemas deliberados con modelos de idiomas grandes
【El método de razonamiento de múltiples pasos para aplicar ICL es muy inspirador】 React: sinergizando razonamiento y actuación en modelos de idiomas
【COT genera directamente el código del programa, y luego permite que Python intérprete ejecute】 Programa de solicitaciones de pensamientos: Desenangeando el cálculo del razonamiento para las tareas de razonamiento numérico
[Big Model genera directamente el contexto de evidencia] Generar en lugar de recuperar: los modelos de lenguaje grandes son generadores de contexto fuertes
【Modelo de escritura con 4 operaciones específicas】 Peer: un modelo de lenguaje colaborativo
【Combinación de Python, ejecutores de SQL y grandes modelos】 Modelos de lenguaje vinculante en idiomas simbólicos
[Recupere el código de generación de documentos] DOCPrompting: Generación del código recuperando los documentos
[Habrá muchos artículos en Grounding+LLM en la próxima serie] LLM-Planner: Planificación de pocos disparos para agentes incorporados con modelos de idiomas grandes
【Datos de capacitación de generación autoiterativa (verificado usando Python)】 Los modelos de idiomas pueden enseñarse a programar mejor
Artículos relacionados: Especialización de modelos de idiomas más pequeños para un razonamiento de varios pasos
Estrella: Bootstrapping Razoning con razonamiento, a partir de Neurips 22 (genere datos de cuna para el modelo de ajuste), causando una serie de artículos de cuna posteriores que enseñan modelos pequeños
Ideas similares [Destilación del conocimiento] Enseñar modelos de idiomas pequeños a la razón y al aprendizaje destilando el contexto
Ideas similares Kaist y Xiang Ren Groups ([Cot's Rationale Fine-Auting (Profesor)] Pinto: razonamiento de lenguaje fiel utilizando fundamentos con indemnización por aviso, etc.) y los modelos de idiomas grandes son maestros de razonamiento
La descomposición de problemas de ETH [COT entrena con problemas y modelos de resolución de problemas por separado] Destilación de capacidades de razonamiento de varios pasos de modelos de idiomas grandes en modelos más pequeños a través de descomposiciones semánticas
【Deje que los modelos pequeños aprendan habilidades de cuna
【Big Model Enseñe el pequeño modelo Cot】 Los modelos de idiomas grandes son maestros de razonamiento
[Big Model genera evidencia (recitación) y luego realiza una pequeña muestra de pregunta y respuesta de libros cerrados] Modelos de lenguaje acuático de recitación
[Métodos de lenguaje natural de razonadores inductivos] modelos de lenguaje como razonadores inductivos
[GPT-3 se utiliza para la anotación de datos (como la clasificación emocional)] ¿Es GPT-3 un buen anotador de datos?
【Modelos para el aumento de datos basados en la capacitación de multitarea para menos muestras de aumento de datos】 Knowda: Modelo de mezcla de conocimiento todo en uno para el aumento de datos en PNL de baja recursos NLP
【Trabajo de planificación procesal, no está interesado en el momento de ser】 Planificación de procedimiento neuroimbólico con indulgencia de sentido común
[Objetivo: Genere artículos fácticamente correctos para consultas a tierra en un gran corpus web
【Combinando los resultados del simulador de física externo en el contexto】 Ojo de la mente: razonamiento del modelo de lenguaje fundamentado a través de la simulación
[Recupere el COT mejorado para hacer tareas intensivas en conocimiento] Recuperación de intercalación con razonamiento de la cadena de pensamiento para preguntas de múltiples pasos que intensifican el conocimiento
【Contraste el conocimiento potencial (binario) en el modelo de lenguaje de reconocimiento no supervisado】 Descubriendo el conocimiento latente en modelos de idiomas sin supervisión
[Percy Liang Group, Motor de búsqueda de confianza, solo el 51.5% de las oraciones generadas están totalmente respaldadas por citas] que evalúa la verificabilidad en los motores de búsqueda generativos
La indicación progresiva de la insinuación mejora el razonamiento en modelos de idiomas grandes
Autoalineación de los modelos lingüísticos impulsados por los principios desde cero con una supervisión humana mínima
Juzgar LLM-as-a-Judge con Mt Bench y Chatbot Arena
[En mi opinión, es uno de los artículos más importantes. capacitación y el ancho y la profundidad de los detalles de la arquitectura, como el ancho y la profundidad.
[Uno de los otros artículos más importantes, Chinchilla, bajo computación limitada, el modelo óptimo no es el modelo más grande, sino un modelo más pequeño entrenado con más datos (60-70b)] COMPUTADO Modelos de lenguaje grande óptimo
[¿Qué arquitectura y objetivos de optimización ayudan a la generalización de muestras cero] ¿Qué arquitectura del modelo de lenguaje y objetivos de prepertinamiento funcionan mejor para la generalización de disparo cero?
【Memorización del proceso de aprendizaje de la "epifanía" de groking-> Formación de circuitos-> limpieza】 Medidas de progreso para la interpretación mecanicista
[Investigue las características del modelo basado en la búsqueda y descubra que ambos son de razonamiento limitado] ¿Pueden los modelos de lenguaje acuáticos de Retriever?
[Marco de evaluación de interacción del lenguaje humano-AI] Evaluación de la interacción del modelo de idioma humano
¿Qué algoritmo de aprendizaje es el aprendizaje en contexto?
【Edición de modelos, este es un tema candente】 Memoria de edición de masas en un transformador
[La sensibilidad del modelo al contexto irrelevante, agregar información irrelevante a los ejemplos de la solicitud y agregar instrucciones que ignoren el contexto irrelevante parcialmente resuelven] los modelos de lenguaje grande pueden distraerse fácilmente con un contexto irrelevante
【La cuna de disparo cero mostrará sesgo y toxicidad bajo cuestiones sensibles】 en un segundo pensamiento, ¡no pensemos paso a paso!
【La cuna del modelo grande tiene capacidades de lenguaje cruzado】 Los modelos de idiomas son razones multilingües de la cadena de pensamiento
[Cuanto más bajo sea el grado de confusión de diferentes secuencias rápidas, mejor será el rendimiento] las indicaciones desmitificadoras en los modelos de idiomas a través de la estimación de perplejidad
[Tarea de resolución de implicación binaria de modelos grandes, esta sugerencia es difícil y no hay fenómeno de escala] Los modelos de lenguaje grande no son comunicadores de shot cero (https://github.com/google/big-bench/tree/main/bigbench/ benchmark_tasks/ implicity)
【Significación basada en la complejidad para el razonamiento de múltiples pasos
¿Qué importa en la poda estructurada de modelos de lenguaje generativo?
[Ambibench DataSet, Task Ambigüedad: el modelo de escalado RLHF funciona mejor en tareas de desambiguación. El ajuste fino es más útil que pocos disparos, ambigüedad de tareas en humanos y modelos de idiomas
【Prueba GPT-3, que incluye memoria, calibración, sesgo, etc.
[Estudio de OSU ¿Qué parte de COT es efectiva para el rendimiento] para comprender la incrustación de la cadena de pensamiento: un estudio empírico de lo que importa
[La investigación sobre el modelo de indicaciones cruzadas de indicaciones discretas] ¿Pueden los indicaciones discretas de extracción de información que se generalizarán en los modelos de idiomas?
【La tasa de memoria es una relación lineal logarítmica con el tamaño del modelo, la longitud del prefijo y la tasa de repetición en la capacitación】 Memorización de cuantificación en los modelos de lenguaje neuronal
【Es muy inspirador, descompone el problema en las subcuestiones a través de la iteración GPT y responda】 Medir y reducir la brecha de composición en los modelos de idiomas
[Prueba análoga de GPT-3 similar a las preguntas de inteligencia de los funcionarios civiles] razonamiento analógico emergente en modelos de idiomas grandes
【Entrenamiento de texto corto, pruebas de texto largas, evaluación de la adaptabilidad de longitud variable del modelo】 un transformador de longitud extrapolática
[Cuando no confiará en los modelos de idiomas: investigar la efectividad y las limitaciones de los recuerdos paramétricos y no paramétricos
【ICL es otra forma de actualización de gradiente】 ¿Por qué GPT puede aprender en contexto?
¿GPT-3 es un psicópata?
[Investigación sobre el proceso de capacitación del modelo OPT en diferentes tamaños, y descubrió que la confusión es un indicador de las trayectorias de capacitación de ICL] de modelos de idiomas a través de escalas
[EMNLP 2022, el corpus de inglés puro previamente capacitado contiene otros idiomas, y las capacidades de lenguaje cruzado del modelo pueden provenir de la fuga de datos] La contaminación del idioma ayuda a explicar las capacidades cruzadas de los modelos de petróleo en inglés
[Priors semánticos anulantes y el uso de la información en propt es una capacidad de sobretensión] Los modelos de lenguaje más grandes hacen aprendizaje en contexto de manera diferente
【EMNLP 2022 Hallazgos】 ¿Qué modelo de idioma capacitar si tiene un millón de horas de GPU?
[La introducción de la tecnología CFG durante el razonamiento mejora enormemente la capacidad de cumplimiento de la instrucción de los modelos pequeños] Manténgase en el tema con orientación sin clasificadores
【Entrena tu propia modelo de LLAMA con el GPT-4 de Openai, y solo puedo decir que te admiro】 Tuning de instrucciones con GPT-4
Reflexión: un agente autónomo con memoria dinámica y autorreflexión
【Aprendizaje indicador de estilo personalizado, OPT】 Información extensible para modelos de idiomas
[Acelerando la decodificación del modelo grande, utilizando el consenso directo entre modelos pequeños y modelos grandes que se utilizarán varias veces a la vez, después de todo, la entrada será muy lenta si es larga] acelerando la decodificación del modelo de lenguaje grande con muestreo especializado
[Use el aviso suave para reducir la disminución de la capacidad de ICL causada por el ajuste fino, ajuste la primera etapa, ajuste la segunda etapa] Preservando la capacidad de aprendizaje en contexto en el modelo de lenguaje grande ajuste fino
【Tareas de análisis semántico, métodos de selección de muestras de ICL, Codex y T5-Large】 diversas demostraciones mejoran la generalización de composición en contexto
【Un nuevo método de optimización para la generación de texto】 Adaptar modelos de generación de idiomas bajo la distancia de variación total
[Estimación de incertidumbre de la generación condicional, utilizando la agrupación semántica combinada con múltiples salidas de muestreo para estimar la entropía de los clústeres] Incertidumbre semántica: invarianidades lingüísticas para la estimación de la incertidumbre en la generación de idiomas naturales
Autorización de Go: Mejora de las habilidades de aprendizaje de disparo cero de modelos de idiomas más pequeños
【Método de generación de texto muy inspirador bajo restricciones de texto libre】 Generación de texto controlable con restricciones de lenguaje
[Al generar predicciones, use similitud para seleccionar frase en lugar de token softmax] modelado de lenguaje enmascarado no paramétrico
[Método ICL para texto largo] Contexto paralelo Las ventanas mejoran el aprendizaje en contexto de modelos de idiomas grandes
[Muestra de modelos InstructTPPT que genera ICL por sí mismo] autoprestando modelos de lenguaje grande para QA de dominio abierto
[¿Puede ICL ingresar más muestras de anotación a través de mecanismos de agrupación y atención] Invirtimiento estructurado: escalar el aprendizaje en contexto a 1,000 ejemplos
Calibración de momento para la generación de texto
【Dos métodos de selección de muestras de ICL, experimentos basados en OPT y GPTJ】 La curación de datos cuidadoso estabiliza el aprendizaje en contexto
【Análisis de los indicadores de evaluación de Mauve (Pillutla et al.)】 Sobre la utilidad de los incrustaciones, grupos y cadenas para la evaluación de la generación de texto
PractAgator: recuperación densa de pocos disparos de 8 ejemplos
[Tres zapateros, Zhuge Liang] La autoconsistencia mejora el razonamiento de la cadena de pensamiento en los modelos de idiomas
[Invertir, entrada y etiqueta generan instrucciones para las condiciones] ¡Adivina las instrucciones haciendo que los modelos de lenguaje fueran más fuertes.
La autoverificación de derivación inversa de LLM】 Los modelos de lenguaje grande son razones con autoverificación
【Métodos para la búsqueda: escenarios de seguridad bajo el proceso de generación de evidencia】 Foveate, atribuye y racionalizan: hacia AI segura y confiable
[Estimación de confianza de los fragmentos de extracción de información generada por texto basados en la búsqueda del haz] ¿Cómo mejora la búsqueda del haz la estimación de confianza de nivel de nivel en el etiquetado de secuencia generativa?
SPT: ajuste de inmediato semiparamétrico para el aprendizaje de múltiples tareas
【Una discusión sobre la etiqueta de oro de resumen extraído】 Resumen de texto con expectativa de Oracle
【Método de detección de ood basado en la distancia marciana】 Detección fuera de distribución y generación selectiva para modelos de lenguaje condicional
[El módulo de atención integra el aviso de la muestra de la muestra] Ensemble del modelo en lugar de la fusión rápida: un método de transferencia de conocimiento específico de la muestra para un ajuste de indicación de pocos disparos
【Solicitar múltiples tareas por descomposición y destilación en un mensaje】 Ajuste de inmediato de inmediato habilita el aprendizaje de transferencia de parámetros eficientes
[Los indicadores de evaluación del razonamiento paso a paso del texto generado se pueden usar como tema para compartir la próxima vez] Roscoe: un conjunto de métricas para calificar el razonamiento paso a paso
[La probabilidad de la secuencia de calibración mejora la generación de idiomas condicionales]
【Método de ataque de texto basado en la optimización de gradiente】 Textgrad: avance de la evaluación de robustez en PNL por optimización basada en gradientes
[Modelado de GMM Límites de clasificación de decisión de ICL para calibrar] Calibración prototípica para aprendizaje de pocos disparos de modelos de idiomas
【Problema de reescritura y método de agregación ICL basado en gráficos】 Pregúntame cualquier cosa: una estrategia simple para solicitar modelos de lenguaje
[Base de datos para seleccionar buenos candidatos como ICL de grupos de ejemplo no anotados] La anotación selectiva hace que los modelos de idiomas sean mejores estudiantes de pocos disparos
ARRATBOOSTING: Clasificación de texto de caja negra con diez pases delanteros
Ataques de puerta trasera guiados por la atención contra Transformers
【Selección de etiquetas automáticas de posición de máscara rápida】 Los modelos de lenguaje previamente capacitado pueden ser aprendices de disparo a cero
[Comprima la longitud del vector de entrada FID y reordenlo cuando salga a la clasificación de documentos de salida] FIF-Light: Generación de texto de recuperación eficiente y efectiva de recuperación
【Explicación sobre la generación de modelos grandes】 Pinto: razonamiento del lenguaje fiel utilizando los fundamentos generados por la provisión
【Encuentre un subconjunto de impactos previos a la capacitación】 Orca: interpretación de modelos de lenguaje impulsado a través de la ubicación que respalda la evidencia en el océano de los datos de previación
[Proyecto inmediato, dirigido a la instrucción, genera filtrado de clasificación de primera etapa y dos etapas] Los modelos de lenguaje grande son ingenieros de inmediato a nivel humano
Desbloqueo del conocimiento para mitigar los riesgos de privacidad en los modelos de idiomas
Modelos de edición con aritmética de tareas
[No ingrese instrucciones y muestras cada vez, conviértalos en módulos de eficiencia de parámetros,] Sugerencia: Hypernetwork Instruction Ango para una generalización eficiente de disparo cero
[Método de generación de visualización de ICL sin selección de muestra manual] Z-ICL: aprendizaje en contexto cero con pseudo-demonios
[Instrucción de tareas y texto Generar integración juntas] Un incrustador, cualquier tarea: Instrucciones de texto con instrucción finalizada
【Big modelo enseñanza modelo pequeño cot】 cuchillo: destilación de conocimiento con fundamentos de texto libre
[Problema de inconsistencia entre la segmentación de palabras de origen y de palabras de destino del modelo de generación de extracción de información] La consistencia de la tokenización es importante para modelos generativos en tareas de NLP extractivas
Parsel: un marco de lenguaje natural unificado para el razonamiento algorítmico
[Selección de muestra de ICL, selección de primera fase y clasificación de segunda fase] Aprendizaje autoadaptativo en contexto
[Lectura intensiva, método de selección no supervisado de inmediato, GPT-2] hacia el ajuste indicador legible humano: The Shining de Kubrick es una buena película, y una buena aviso también
【Prontaqa DataSet Probar la capacidad de inferencia de cot y descubre que la capacidad de planificación aún es limitada】 Los modelos de lenguaje pueden (una especie) de razón: un análisis formal sistemático de la cadena de pensamiento
【Conjunto de datos de razonamiento】 wikiwhy: responder y explicar preguntas de causa y efecto
【DataSet de razonamiento】 Street: un razonamiento estructurado de varias tareas y explicación de referencia
【Conjunto de datos de razonamiento, comparando OPT previa al entrenamiento y ajuste fino, incluidos los modelos de ajuste fino de la cuna】 Alerta: adaptación de modelos de lenguaje a tareas de razonamiento
[Resumen del reciente razonamiento del equipo de Zhang Ningyu de la Universidad de Zhejiang] razonamiento con el modelo de idioma: una encuesta
[Resumen de la tecnología y dirección de la generación de texto del equipo de Xiao Yanghua en Fudan] Aprovechando el conocimiento y el razonamiento para la generación de lenguaje natural similar a los humanos: una breve revisión
[Resumen de artículos de razonamiento recientes, Jie Huang desde UIUC] hacia el razonamiento en modelos de idiomas grandes: una encuesta
【Revisión de tareas, conjuntos de datos y métodos de razonamiento matemático y DL】 Una encuesta de aprendizaje profundo para el razonamiento matemático
Una encuesta sobre procesamiento del lenguaje natural para la programación
Conjunto de datos de modelado de recompensas:
Red-teaming数据集,harmless vs. helpful, RLHF +scale更难被攻击(另一个有效的技术是CoT fine-tuning):
【知识】+【推理】+【生成】
如果对您有帮助,请star支持一下,欢迎Pull Request~
主观整理,时间上主要从ICLR 2023 Rebuttal期间开始的,包括ICLR,ACL,ICML等预印版论文。
不妥之处或者建议请指正! Dongfang Li, [email protected]


