Awesome ChatTTS
1.0.0

Inglés |
Awesome-Chattts es un proyecto de resumen de recursos de Chattts oficialmente recomendado.
Si cree que este proyecto es útil para que comprenda y use Chattts, por favor, déme algunas recompensas y soporte.
Nota
Los siguientes proyectos son recursos comunitarios.
| Sitio web | tipo |
|---|---|
| Web original | Experiencia de versión web original |
| Forge Web | Experiencia de edición mejorada de Forge |
| Linux | Paquete de instalación de Python |
| Muestras | Ejemplo de semillas de tono |
| Clonación | Experiencia de clonación de tono |
| proyecto | Estrella | Reflejos |
|---|---|---|
| jianchang512/chattts-ui | Proporciona interfaz API que se puede llamar en aplicaciones de terceros | |
| 6drf21e/chattts_colab | Proporcionar salida de transmisión, soporte de generación de audio larga y lectura de características parciales | |
| Lenml/Chattts-Forge | Proporciona mejora vocal y reducción de ruido de fondo, con palabras rápidas adicionales disponibles | |
| Ccmahua/chattts mejorado | Admite el procesamiento por lotes de archivos y exportaciones de archivos SRT | |
| HKOON/CHATTTS-OPENVOICE | Clonación de sonido con OpenVoice |
| proyecto | Estrella | Reflejos |
|---|---|---|
| 6drf21e/chattts_speaker | Marcado del personaje de tono y evaluación de estabilidad | |
| Aifsh/comfyui-chattts | Comfyui versión, que se puede introducir como un nodo de flujo de trabajo | |
| MaterialShadow/Chattts-Manager | Proporciona un sistema de administración de tono y una interfaz WebUI |
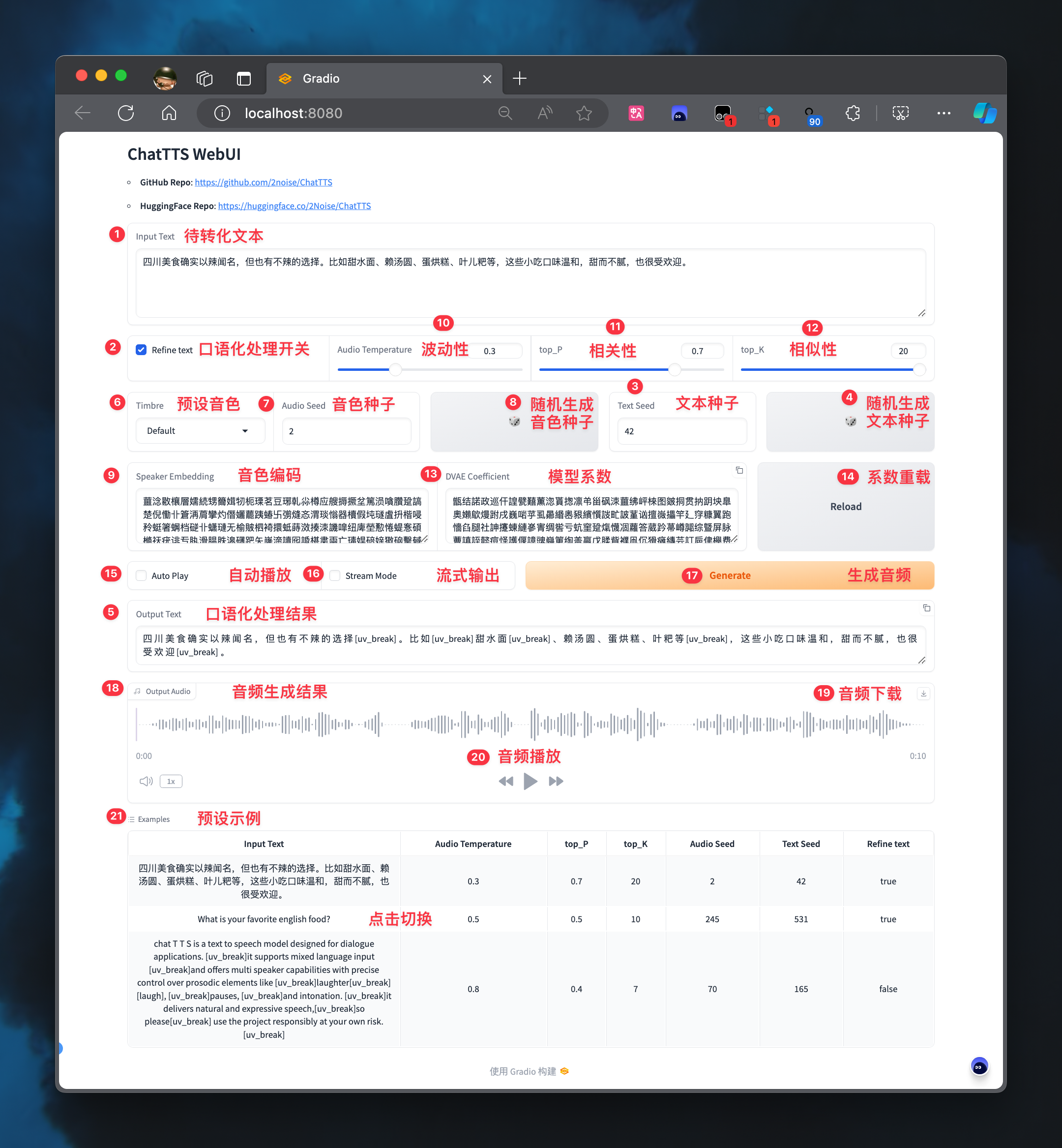
Después de las .pt reales, hay una diferencia significativa en el efecto de generar spk_emb cada vez que se genera el valor de semilla de tono especificado y reutilizando spk_emb pregenerado.
Las semillas de tono fueron inicialmente marcadas y una evaluación estable en el proyecto Chattts_Speaker, y el tono correcto se puede seleccionar rápidamente a través de ejemplos.
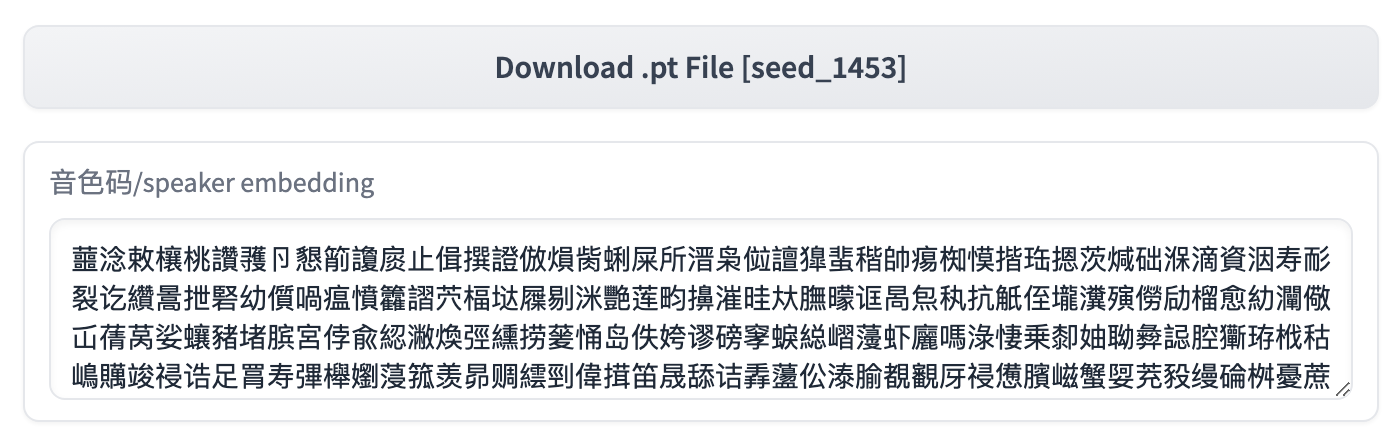
Cuando se usa en el WebUI oficial, puede copiar directamente el código de tono y reemplazar el valor en 9. Speaker Embedding para lograr el control de tono.
Cuando se use en los scripts de Python, consulte el esquema de compresión en el número 07 para lograr el control de tono.
spk = torch . load ( "asset/seed_1332_restored_emb.pt" , map_location = torch . device ( 'cpu' )). detach ()
spk_emb_str = compress_and_encode ( spk )
params_infer_code = ChatTTS . Chat . InferCodeParams (
spk_emb = spk_emb_str , # add sampled speaker
temperature = .0003 , # using custom temperature
top_P = 0.7 , # top P decode
top_K = 20 , # top K decode
)| video | Reflejos |
|---|---|
| Hermano Tongji Zihao | Tutorial de implementación detallado desde la entrada a avanzado |
| ZTFS | Tutorial de implementación de Mac M1 |
| Rey - Bao Bao | Tutorial de implementación de Windows |
| video | Reflejos |
|---|---|
| Sam Witteveen | Introducción a la versión en inglés |
Después de las iteraciones recientes, los problemas en el código de repositorio de fuente se han resuelto básicamente. Si encuentra problemas, se recomienda verificar primero la versión china del documento de descripción oficial en detalle.
El proyecto original necesita descargar el modelo correspondiente de Huggingface. Como alternativa, puede descargar el modelo y la configuración de Modelscope y configurar la ruta local.
Importante
La biblioteca de modelos en la Torre Mágica es mantenida por voluntarios y no garantiza que todos los modelos estén actualizados.
pip install modelscope # 在开头导入依赖,并下载模型和配置
from modelscope import snapshot_download
model_dir = snapshot_download ( 'zlj2546/ChatTTS' )
# 第 118 行修改模型路径
ret = chat . load_models ( 'custom' , custom_path = model_dir )Cuando se ejecuta en el IDE, el script no puede ejecutarse sin problemas debido a la ruta relativa del archivo.
Se recomienda consultar las instrucciones en el inicio rápido de la documentación oficial y ejecutarla directamente en la terminal.
Asegúrese de estar en el Directorio Root del Proyecto al ejecutar el siguiente comando.
python examples/web/webui.pyEl audio generado se guardará en
./output_audio_n.mp3
python examples/cmd/run.py " Your text 1. " " Your text 2. " ¿Este problema ocurre porque el código oficial no cubre todo el tiempo cuando se trata de puntuación china, por ejemplo ? Los símbolos como, … no se procesan, lo que resulta en un error durante la generación de modelos.
Puede eliminar manualmente signos de puntuación chinos similares, o modificar el código en ChatTTS/utils/infer_utils.py para agregar puntos de puntuación faltantes al diccionario de character_map en las líneas 103.
character_map = {
'…' : '' ,
'—' : ',' ,
'_' : ',' ,
'?' : ',' ,
}La GPU requiere al menos la memoria de video 4G, de lo contrario, se utilizará la CPU.
1. load_models() got an unexpected keyword argument 'source'
Ver preguntas frecuentes para más detalles: el modelo no se puede descargar
2. cannot import name 'CommitOperationAdd' from 'huggingface_hub'
Ver preguntas frecuentes para más detalles: el modelo no se puede descargar
3 FileNotFoundError:[Erzno 2] No such file or directory: 'C:\Users\xxx\.cache\huggingface\hub\models--2Noise--ChatTTS\snapshots
Ver preguntas frecuentes para más detalles: el modelo no se puede descargar
4. local variable 'Normalizer' referenced before assignment
Debe instalar las dependencias de pynini y WeTextProcessing después de completar la configuración del entorno.
conda install -c conda-forge pynini=2.1.5 && pip install WeTextProcessing 5. download to Local path D:pythonlprojectChatTTSChatTTS failed.
Ejecutar scripts directamente en el IDE, y se informará un error debido a problemas de ruta de archivo.
6. ModuleNotFoundError : No module named'Cython'
No se encuentra la ruta de ejecución de Python, los dispositivos de Windows deben configurar la ruta de entorno de acuerdo con el tutorial


