archgw
release 0.1.5 ?
Arch es un proxy distribuido de capa 7 inteligente diseñado para proteger, observar y personalizar a los agentes de IA con sus API.
Engineered with purpose-built LLMs, Arch handles the critical but undifferentiated tasks related to the handling and processing of prompts, including detecting and rejecting jailbreak attempts, intelligently calling "backend" APIs to fulfill the user's request represented in a prompt, routing to and offering disaster recovery between upstream LLMs, and managing the observability of prompts and LLM interactions in a centralized way.
Arch se basa en (y con los contribuyentes centrales de) proxy enviado con la creencia de que:
Las indicaciones son solicitudes de usuario matizadas y opacas, que requieren las mismas capacidades que las solicitudes HTTP tradicionales que incluyen manejo seguro, enrutamiento inteligente, observabilidad robusta e integración con sistemas de backend (API) para personalización, todas las lógicas comerciales fuera.*
Características centrales :
Salte a nuestros documentos para aprender cómo puede usar Arch para mejorar la velocidad, la seguridad y la personalización de sus aplicaciones Genai.
Importante
Hoy, la función que llama a LLM (Arch-Function) diseñada para los escenarios de Agentic y RAG está alojado de forma gratuita en la región de los Estados Unidos-Central. Para ofrecer latencias y rendimiento consistentes, y para administrar nuestros gastos, pronto habilitaremos el acceso a la versión alojada a través de las claves de desarrolladores y le daremos la opción de ejecutar ese LLM localmente. Para más detalles, consulte este número #258
Para ponerse en contacto con nosotros, únase a nuestro servidor Discord. Monitorearemos eso activamente y ofrecemos apoyo allí.
Siga esta guía para aprender a configurar rápidamente el Arch e integrarlo en sus aplicaciones generativas de IA.
Antes de comenzar, asegúrese de tener lo siguiente:
Docker y Python instalados en su sistemaAPI Keys para proveedores de LLM (si usa LLMS externos)La CLI de Arch le permite administrar e interactuar con la puerta de enlace de Arch de manera eficiente. Para instalar la CLI, simplemente ejecute el siguiente comando: Consejo: recomendamos que los desarrolladores creen un nuevo entorno virtual de Python para aislar dependencias antes de instalar Arch. Esto garantiza que ArchgW y sus dependencias no interfieran con otros paquetes en su sistema.
Asegúrese de tener las siguientes utilidades instaladas antes de continuar,
$ python -m venv venv
$ source venv/bin/activate # On Windows, use: venvScriptsactivate
$ pip install archgwArch opera en función de un archivo de configuración donde puede definir proveedores de LLM, objetivos rápidos, barandas, etc. A continuación se muestra una configuración de ejemplo para comenzar:
version : v0.1
listener :
address : 127.0.0.1
port : 8080 # If you configure port 443, you'll need to update the listener with tls_certificates
message_format : huggingface
# Centralized way to manage LLMs, manage keys, retry logic, failover and limits in a central way
llm_providers :
- name : OpenAI
provider : openai
access_key : $OPENAI_API_KEY
model : gpt-3.5-turbo
default : true
# default system prompt used by all prompt targets
system_prompt : |
You are a network assistant that helps operators with a better understanding of network traffic flow and perform actions on networking operations. No advice on manufacturers or purchasing decisions.
prompt_targets :
- name : device_summary
description : Retrieve network statistics for specific devices within a time range
endpoint :
name : app_server
path : /agent/device_summary
parameters :
- name : device_ids
type : list
description : A list of device identifiers (IDs) to retrieve statistics for.
required : true # device_ids are required to get device statistics
- name : days
type : int
description : The number of days for which to gather device statistics.
default : " 7 "
- name : reboot_devices
description : Reboot a list of devices
endpoint :
name : app_server
path : /agent/device_reboot
parameters :
- name : device_ids
type : list
description : A list of device identifiers (IDs).
required : true
- name : days
type : int
description : A list of device identifiers (IDs)
default : " 7 "
# Arch creates a round-robin load balancing between different endpoints, managed via the cluster subsystem.
endpoints :
app_server :
# value could be ip address or a hostname with port
# this could also be a list of endpoints for load balancing
# for example endpoint: [ ip1:port, ip2:port ]
endpoint : host.docker.internal:18083
# max time to wait for a connection to be established
connect_timeout : 0.005sHacer llamadas salientes a través de Arch
from openai import OpenAI
# Use the OpenAI client as usual
client = OpenAI (
# No need to set a specific openai.api_key since it's configured in Arch's gateway
api_key = '--' ,
# Set the OpenAI API base URL to the Arch gateway endpoint
base_url = "http://127.0.0.1:12000/v1"
)
response = client . chat . completions . create (
# we select model from arch_config file
model = "--" ,
messages = [{ "role" : "user" , "content" : "What is the capital of France?" }],
)
print ( "OpenAI Response:" , response . choices [ 0 ]. message . content )Arch está diseñado para admitir la mejor observabilidad en clase al apoyar los estándares abiertos. Lea nuestros documentos sobre observabilidad para obtener más detalles sobre el rastreo, las métricas y los registros
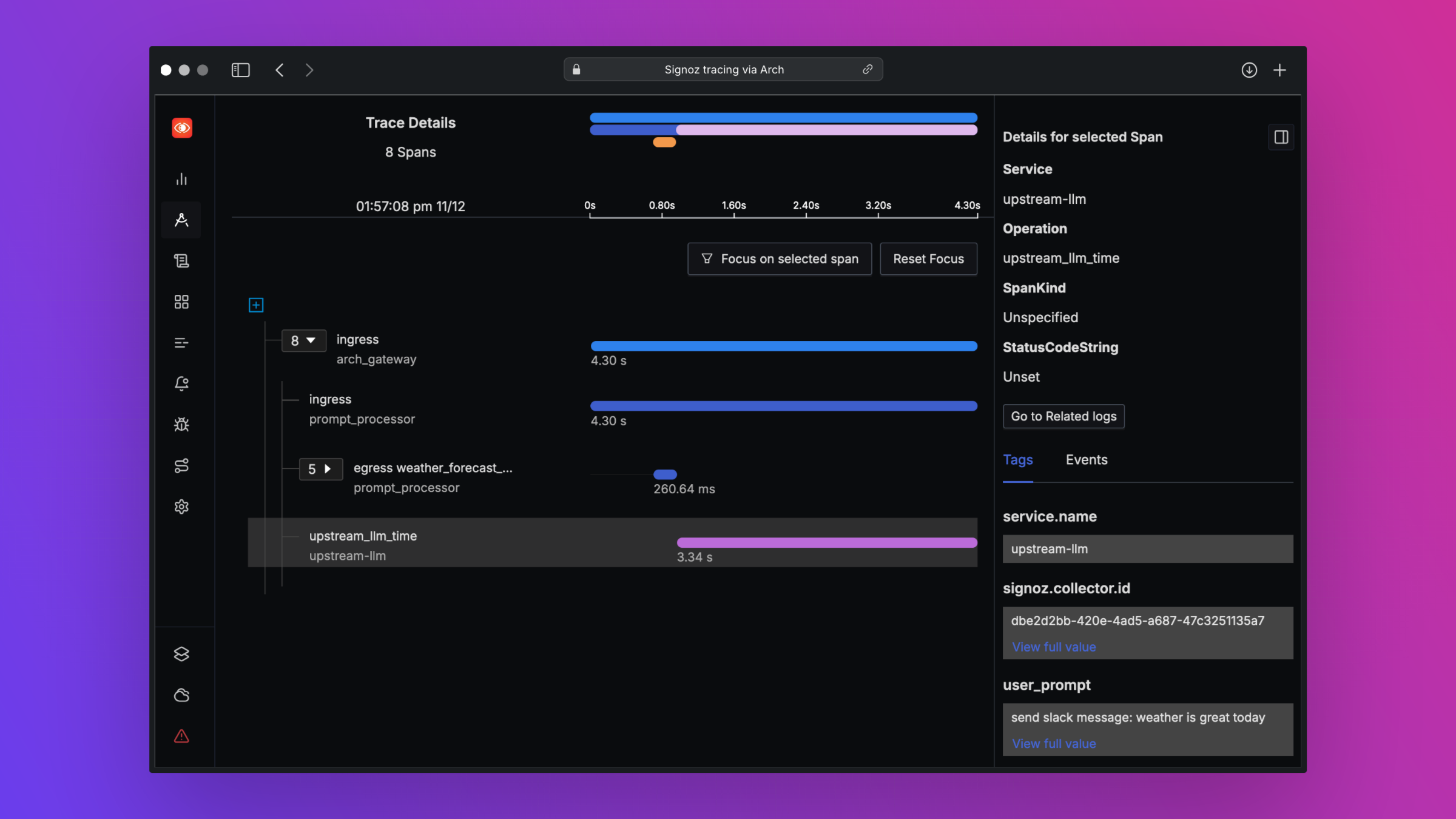
¡Nos encantaría comentarios sobre nuestra hoja de ruta y agradecemos las contribuciones al Arch ! Ya sea que esté arreglando errores, agregando nuevas funciones, mejorando la documentación o la creación de tutoriales, su ayuda es muy apreciada. Visite nuestra guía de contribución para obtener más detalles


