JARVIS ChatGPT
1.0.0
Un asistente interactivo basado en la voz equipado con una variedad de voces sintéticas (incluida la voz de Jarvis de Ironman)
 Imagen de MidJourney AI
Imagen de MidJourney AI
¿Alguna vez soñó pedir consejos de sistema hiperinteligentes para mejorar su armadura? ¡Ahora puedes! Bueno, tal vez no la parte de la armadura ... este proyecto explota Openai Whisper, Operai Chatgpt e IBM Watson.
Motivación del proyecto:
Muchas veces las ideas vienen en el peor momento y se desvanecen antes de que tengas tiempo para explorarlas mejor. El objetivo de este proyecto es desarrollar un sistema capaz de dar consejos y opiniones en tiempo casi real sobre cualquier cosa que solicite. Se podrá acceder al asistente final desde cualquier micrófono autorizado dentro de su casa o su teléfono, debe ejecutarse constantemente en segundo plano y, cuando se convocará, debe poder generar respuestas significativas (con voz rudo), así como interfaz con la PC o un servidor y guardar/leer/escribir archivos a los que se puede acceder más adelante. Debería poder ejecutar investigaciones, recopilar material de Internet (extraer contenido de las páginas HTML, transcribir videos de YouTube, encontrar artículos científicos ...) y proporcionar resúmenes que puedan usarse como contexto para tomar decisiones informadas. Además, podría interactuar con algunos dispositivos externos (IoT), pero eso es extra.
MANIFESTACIÓN:
Puedo compartir Finnaly el primer borrador del modo de investigación. Esta modalidad se pensaba para las personas que a menudo trataban con trabajos de investigación.
PD: Este modo no es súper estable y debe trabajar en
PPS: Este proyecto se suspenderá por algún tiempo ya que trabajaré en mi tesis hasta 2024. Sin embargo, ya hay muchas cosas que se pueden mejorar, ¡así que volveré!
DESCARGO DE RESPONSABILIDAD:
El proyecto podría consumir su crédito OpenAI que resulta en una facturación no deseada;
No asumro la responsabilidad de ningún cargo no deseado;
Considere establecer limitaciones en el consumo de crédito en su cuenta de OpenAI;
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117 );Puede confiar en la nueva
setup.batBat que hará la mayoría de las cosas por usted.
Script principal debe ejecutar: openai_api_chatbot.py Si desea utilizar la última versión de la API de OpenAI dentro de la carpeta Demos, encontrará alguna orientación para los paquetes utilizados en el proyecto, si tiene errores, primero puede verificar estos archivos para orientar el problema. La mayoría de las funciones se almacenan en la carpeta de asistente: get_audio.py almacena todas las funciones para manejar las interacciones de micrófono, tools.py By implementa algunos aspectos básicos del asistente virtual, voice.py describe una clase de voz (muy) rugosa. Agents.py manejar la parte langchain del sistema (aquí puede agregar o eliminar herramientas de los kits de herramientas de los agentes)
Los scripts restantes son complementarios para la generación de voz y no deben editarse.
Puede ejecutar setup.bat si se ejecuta en Windows/Linux. El script realizará cada paso de la instalación manual en secuencia. Consulte aquellos en caso de que el procedimiento falle.
La instalación automática también ejecutará la instalación de Vicuna (Guía de instalación de Vicuna)
pip install -r venv_requirements.txt ; Esto podría llevar algún tiempo; Si encuentra conflictos en paquetes específicos, instálelos manualmente sin el ==<version> ;whisper_edits a la carpeta whisper de su entorno (. Venv lib Site-Packages Whisper ) Estas ediciones agregarán solo un atributo al modelo Whisper para acceder a su dimensión más fácilmente;demos/tts_demo.py ); cd Vicuna
call vicuna.ps1
env.txt y cambie el nombre a .env (sí, elimine la extensión txt)torch.cuda.is_available() y torch.cuda.get_device_name(0) dentro de pyhton; .tests.py . Este archivo intenta realizar operaciones básicas que podrían aumentar los errores;VirtualAssistant.__init__() ; 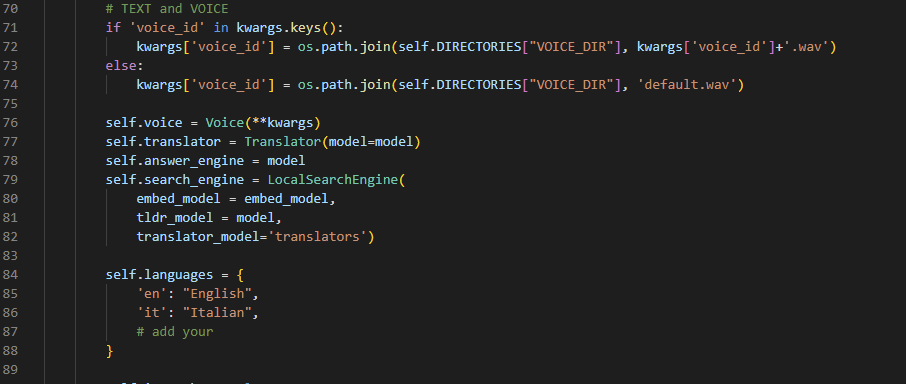
__main__() en whisper_model = whisper.load_model("large") ; Pero espero que tu memoria de GPU sea grande también. openai_api_chatbot.py ):Cuando se ejecute, verá mucha información que se muestra. Me esfuerzo constantemente por mejorar la legibilidad de la ejecución, todo el proyecto es una gran versión beta, perdona ligeras variaciones de las pantallas a continuación. De todos modos, esto es lo que sucede en términos generales cuando presionas 'Run':
Jarvis para convocar al asistente. En este punto, comenzará una conversación y puede hablar en cualquier idioma que desee (si siguió el paso 2). La conversación terminará cuando 1) Diga una palabra de parada 2) diga algo con una palabra (como 'ok') 3) Cuando deje de hacer preguntas durante más de 30 segundos 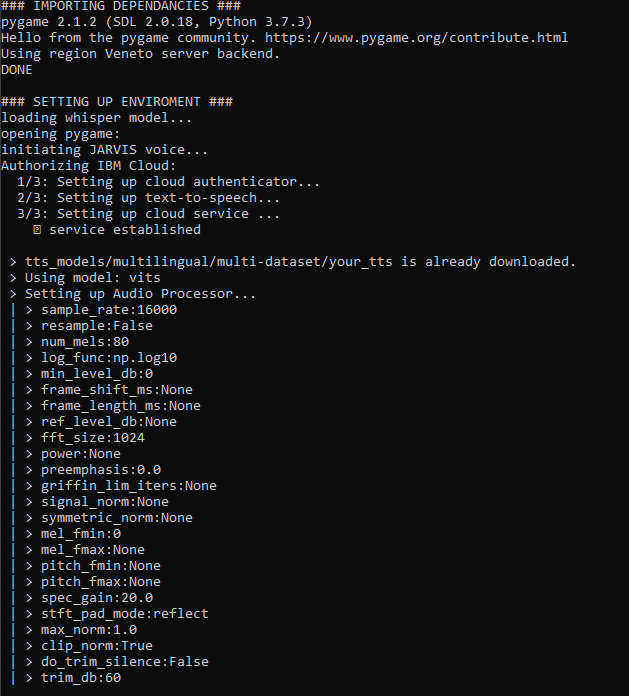
chat_history con su pregunta, enviará una solicitud con la API y actualizará el historial tan pronto como reciba una respuesta completa de ChatGPT (esto puede tomar hasta 5-10 segundos, considere explícitamente una respuesta breve si tiene prisa);say() realizará la duplicación de voz para hablar con la voz de Jarvis/alguien; Si el argumento no está en inglés, IBM Watson enviará la respuesta de uno de sus buenos modelos de texto a voz. Si todo falla, las funciones dependerán de PYTTSX3, que es una alternativa rápida pero no tan genial;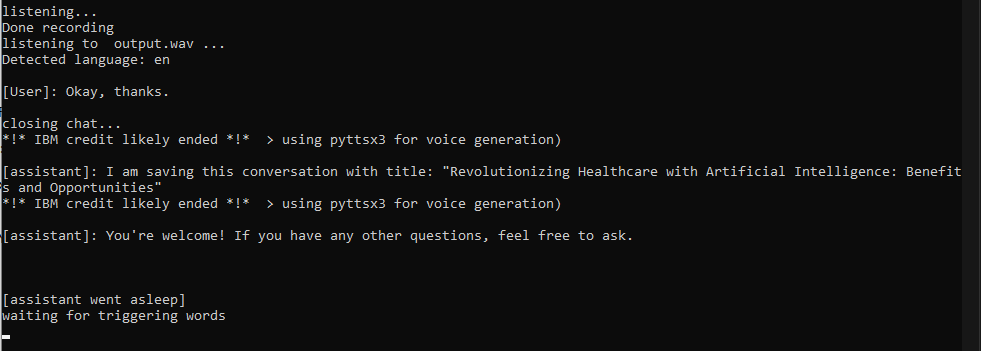
Hice algunas indicaciones y cerré la conversación
No es ideal, lo sé, pero funciona por ahora
VirtualAssistant pila completa con memoria y acceso local de almacenamiento Actualmente trabajando en:
siguiente:
Consulte el updateHistory.md del proyecto para obtener más información.
¡Divertirse!
Categorías: instalar, general, tiempo de ejecución
El problema es consciente de Whisper. Debe volver a instalarlo manualmente con pip install whisper-openai
pip install --upgrade openai . Los requisitos no se actualizan en cada confirmación. Si bien esto puede generar errores, puede instalar rápidamente los módulos que faltan, al mismo tiempo mantiene el medio ambiente limpio de los conflictos cuando pruebo los nuevos paquetes (y pruebo muchos de ellos)
Significa que el modelo que seleccionó es demasiado grande para la memoria de su dispositivo CUDA. Desafortunadamente, no hay mucho que pueda hacer al respecto, excepto cargar un modelo más pequeño. Si el modelo más pequeño no le satisface, es posible que desee hablar "más claro" o hacer indicaciones más largas para que el modelo predice con mayor precisión lo que está diciendo. Esto suena inconveniente pero, en mi caso, mejoró enormemente mi habla inglesa :)
Este es un error aún presente, no espere tener conversaciones largas con su asistente, ya que simplemente tendrá suficiente memoria para recordar toda la conversación en algún momento. Una solución está en desarrollo, podría consistir en adoptar un enfoque de 'ventanas deslizantes', incluso si puede causar la repetición de algunos conceptos.
En este momento (abril de 2023) Estoy trabajando casi sin parar en esto. Probablemente me tomaré un descanso en el verano porque trabajaré en mi tesis.
Si tiene preguntas, puede contactarme planteando un problema y haré todo lo posible para ayudar lo antes posible.
Gianmarco Guarnier


