Deep RL Keras
1.0.0
Implementación modular de algoritmos populares de aprendizaje de refuerzo profundo en keras:
Esta implementación requiere Keras 2.1.6, así como Operai Gym.
$ pip install gym keras==2.1.6El algoritmo de actor-crítico es un método sin modelo y sin políticas donde el crítico actúa como un aproximador de función de valor y el actor como un aproximador de función de política. Al entrenar, el crítico predice el error TD y guía el aprendizaje de sí mismo y del actor. En la práctica, aproximamos el error TD utilizando la función de ventaja. Para obtener más estabilidad, utilizamos una columna vertebral computacional compartida en ambas redes, así como una formulación N-Step de las recompensas con descuento. También incorporamos un término de regularización de entropía (aprendizaje "suave") para fomentar la exploración. Si bien A2C es simple y eficiente, ejecutarlo en los juegos Atari rápidamente se vuelve intratable debido al largo tiempo de cálculo.
De manera similar al algoritmo A2C, la implementación de A3C incorpora actualizaciones de peso asincrónicas, lo que permite un cálculo mucho más rápido. Utilizamos múltiples agentes para realizar un ascenso de gradiente de forma asincrónica, en múltiples hilos. Probamos A3C en el entorno de ruptura de Atari.
El algoritmo DDPG es un algoritmo sin modelo libre de políticas para espacios de acción continua. De manera similar a A2C, es un algoritmo de actor crítico en el que el actor está entrenado en una política objetivo determinista, y el crítico predice valores Q. Para reducir la varianza y aumentar la estabilidad, utilizamos la repetición de experiencia y las redes de destino separadas. Además, como lo insinúan Operai, fomentamos la exploración a través del ruido del espacio de los parámetros (a diferencia del ruido del espacio de acción tradicional). Probamos DDPG en el entorno de aterrizaje lunar.
$ python3 main.py --type A2C --env CartPole-v1
$ python3 main.py --type A3C --env CartPole-v1 --nb_episodes 10000 --n_threads 16
$ python3 main.py --type A3C --env BreakoutNoFrameskip-v4 --is_atari --nb_episodes 10000 --n_threads 16
$ python3 main.py --type DDPG --env LunarLanderContinuous-v2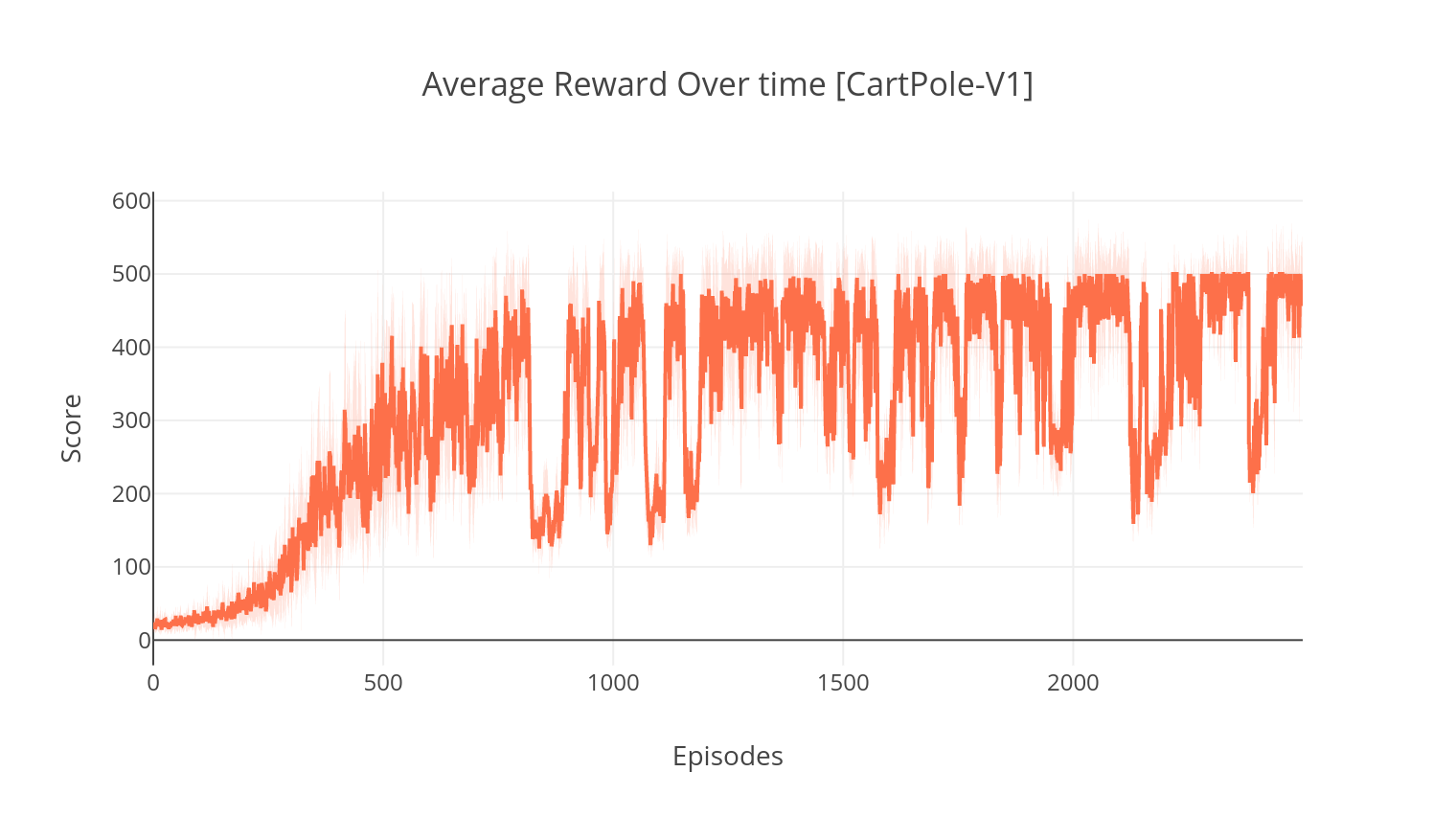
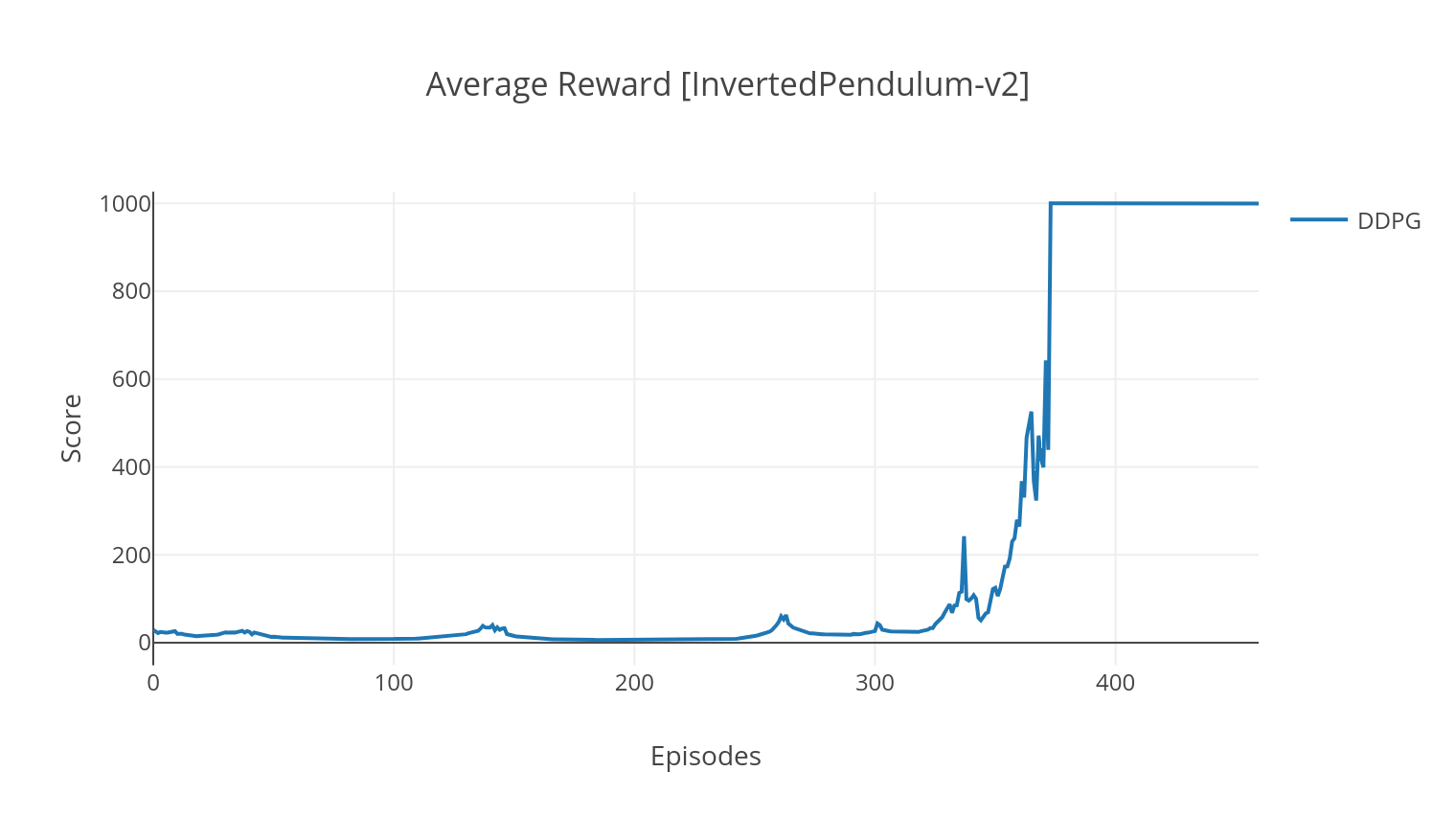
El algoritmo DQN es un algoritmo Q-Learning, que utiliza una red neuronal profunda como un aproximador de función de valor Q. Estimamos los valores Q objetivo aprovechando la ecuación de Bellman y reuniendo experiencia a través de una política de greedia epsilon. Para obtener más estabilidad, mostramos experiencias pasadas al azar (repetición de experiencia). Una variante del algoritmo DQN es el doble DQN (o DDQN). Para una estimación más precisa de nuestros valores Q, utilizamos una segunda red para templar las sobreestimaciones de los valores Q por la red original. Esta red de destino se actualiza a una tasa más lenta, en cada paso de entrenamiento.
Podemos mejorar aún más nuestro algoritmo DDQN agregando una repetición de experiencia priorizada (PER), cuyo objetivo es realizar un muestreo de importancia en la experiencia reunida. La experiencia es clasificada por su error TD y almacenada en una estructura Sumtree, que permite una recuperación eficiente de las transiciones (S, A, R, S ') con el más alto error.
En la variante de duelo del DQN, incorporamos una capa intermedia en la red Q para estimar tanto el valor de estado como la función de ventaja dependiente del estado. Después de la reformulación (ver ref), resulta que podemos expresar el valor Q estimado como el valor de estado, a lo que agregamos la ventaja estimada y restamos su media. Esta factorización de los valores independientes del estado y dependientes del estado ayuda a desenredar el aprendizaje entre acciones y produce mejores resultados.
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64 --with_PER
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64 --dueling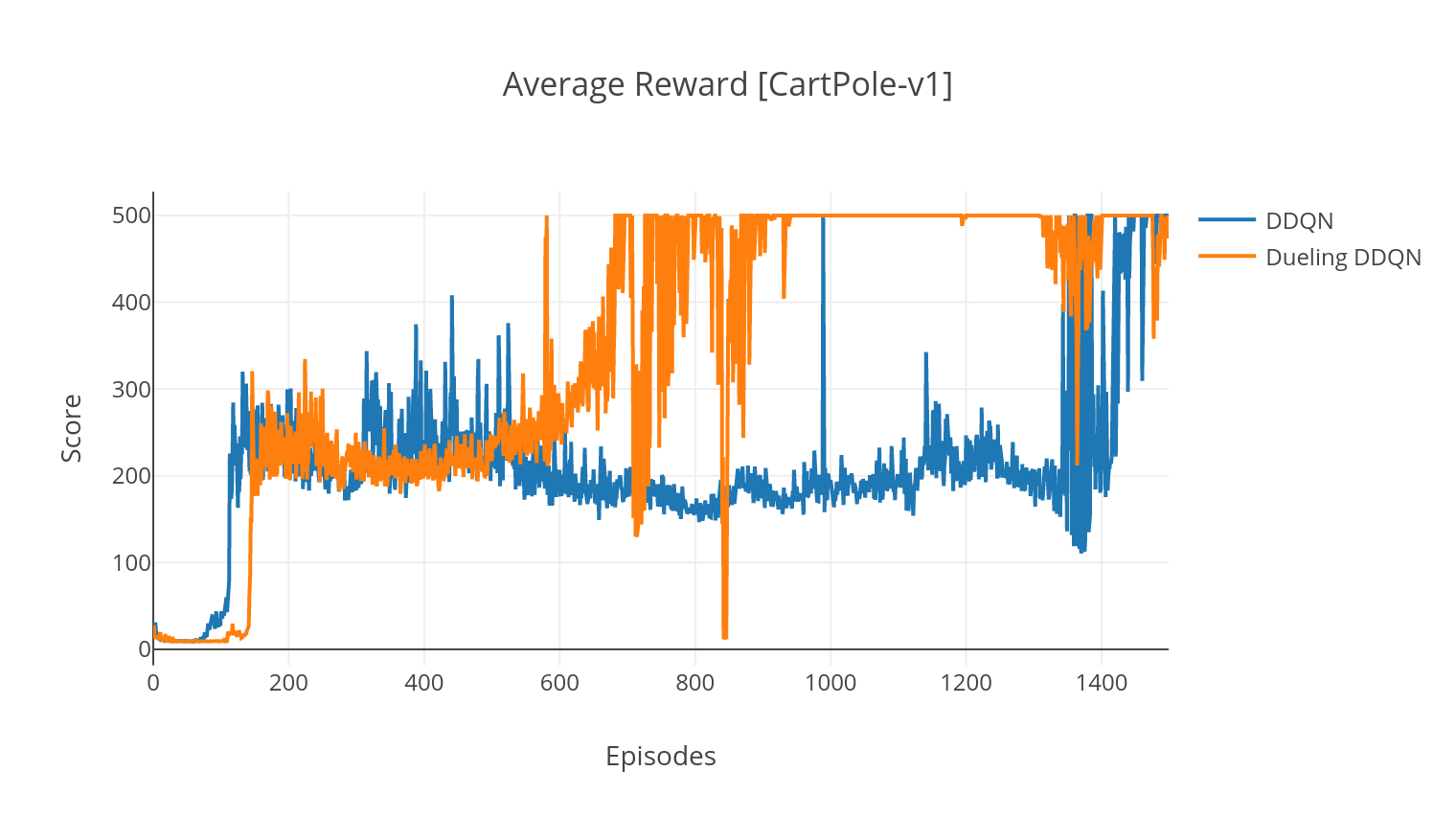
| Argumento | Descripción | Valores |
|---|---|---|
| --tipo | Tipo de algoritmo RL para ejecutar | Elija entre {A2C, A3C, DDQN, DDPG} |
| - | Especificar el entorno | BreakoutNoFrameskip-v4 (predeterminado) |
| --nb_episodes | Número de episodios para ejecutar | 5000 (predeterminado) |
| -batch_size | Tamaño de lote (DDQN, DDPG) | 32 (predeterminado) |
| -consecutivo_frames | Número de marcos consecutivos apilados | 4 (predeterminado) |
| --is_atari | Si el entorno es un juego de Atari con entrada de píxeles | - |
| -with_per | Si utilizar la repetición de experiencia priorizada (con DDQN) | - |
| --duel. | Si usar redes de duelo (con DDQN) | - |
| --n_threads | Número de hilos (A3C) | 16 (predeterminado) |
| --Gather_stats | Si calcular estadísticas de puntajes promedió más de 10 juegos (lento, ver más abajo) | - |
| --prestar | Si debe prender el entorno como capacitación | - |
| -GPU | Índice de GPU | 0 |
Todos los modelos se guardan en <algorithm_folder>/models/ cuando terminan de entrenamiento. Puede visualizarlos en el mismo entorno en el que fueron entrenados ejecutando el script load_and_run.py . Para los modelos DQN, debe especificar la ruta al modelo deseado en el argumento --model_path . Para los modelos críticos de actores, debe especificar ambos archivos de peso en los argumentos --actor_path y --critic_path .
Usando TensorBoard, puede monitorear la puntuación del agente ya que es el entrenamiento. Al entrenar, se creará una carpeta de registro con el nombre que coincide con el entorno elegido. Por ejemplo, para seguir la progresión A2C en Cartpole-V1, simplemente ejecute:
$ tensorboard --logdir=A2C/tensorboard_CartPole-v1/ Al entrenar con el argumento --gather_stats , se genera un archivo de registro que contiene puntajes promediados en 10 juegos en cada episodio: logs.csv . Usando Plotly, puede visualizar la recompensa promedio por episodio. Para hacerlo, primero deberá instalar complement y obtener una licencia gratuita.
pip3 install plotlyPara configurar sus credenciales, ejecute:
import plotly
plotly . tools . set_credentials_file ( username = '<your_username>' , api_key = '<your_key>' )Finalmente, para trazar los resultados, ejecute:
python3 utils/plot_results.py < path_to_your_log_file >

