
Antes de estudiar el contenido de este artículo, primero debemos comprender el concepto de asincrónico. Lo primero que debemos enfatizar es que existe una diferencia esencial entre asincrónico y paralelo .
El paralelismo generalmente se refiere a la computación paralela, lo que significa que se ejecutan varias instrucciones al mismo tiempo. Estas instrucciones se pueden ejecutar en varios núcleos de la misma CPU , en varias CPU , en varios hosts físicos o incluso en varias redes.
La sincronización generalmente se refiere a ejecutar tareas en un orden predeterminado. Solo cuando se complete la tarea anterior, se ejecutará la siguiente.
Asincrónico, correspondiente a la sincronización, significa que CPU deja de lado temporalmente la tarea actual, procesa la siguiente tarea primero y luego regresa a la tarea anterior para continuar la ejecución después de recibir la notificación de devolución de llamada de la tarea anterior. Segundo hilo.
Quizás sea más intuitivo explicar el paralelismo, la sincronización y la asincronía en forma de imágenes. Supongamos que hay dos tareas A y B que deben procesarse. Los métodos de procesamiento paralelo, sincrónico y asincrónico adoptarán los métodos de ejecución como se muestra en la figura. siguiente figura:
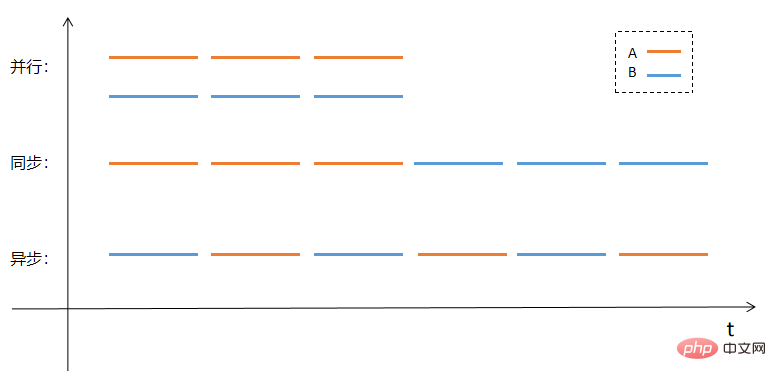
JavaScript nos proporciona muchas funciones asincrónicas. Estas funciones nos permiten ejecutar tareas asincrónicas de manera conveniente, es decir, comenzamos a ejecutar una tarea (función) ahora, pero la tarea se completará más tarde y el tiempo de finalización específico. no es No estoy seguro.
Por ejemplo, la función setTimeout es una función asincrónica muy típica. Además, fs.readFile y fs.writeFile también son funciones asincrónicas.
Podemos definir un caso de tarea asincrónica nosotros mismos, como personalizar una función de copia de archivos copyFile(from,to) :
const fs = require('fs')function copyFile(from, to) {
fs.readFile(de, (err, datos) => {
si (errar) {
consola.log(err.mensaje)
devolver
}
fs.writeFile(a, datos, (err) => {
si (errar) {
consola.log(err.mensaje)
devolver
}
console.log('Copia finalizada')
})
})} La función copyFile primero lee los datos del archivo del parámetro from y luego escribe los datos en el archivo al que apunta el parámetro to .
Podemos llamar copyFile de esta manera:
copyFile('./from.txt','./to.txt')//Copiar el archivo Si hay otro código después de copyFile(...) en este momento, el programa no espere La ejecución de copyFile finaliza, pero se ejecuta directamente hacia abajo. Al programa no le importa cuándo finaliza la tarea de copia del archivo.
copyFile('./from.txt','./to.txt')//El siguiente código no esperará a que finalice la ejecución del código anterior... En este punto, todo parece normal, pero si ¿Qué sucede si accede directamente al contenido del archivo ./to.txt después de la función copyFile(...) ?
Esto no leerá el contenido copiado, así:
copyFile('./from.txt','./to.txt')fs.readFile('./to.txt',(err,data)= >{
...}) Si el archivo ./to.txt no se ha creado antes de ejecutar el programa, obtendrá el siguiente error:
PS E:CodeNodedemos�3-callback> node .index.js finalizado Copia terminada PS E:CodeNodedemos�3-callback> nodo .index.js Error: ENOENT: no existe tal archivo o directorio, abra 'E:CodeNodedemos�3-callbackto.txt'Copia finalizada
Incluso si ./to.txt existe, el contenido copiado no se puede leer.
La razón de este fenómeno es: copyFile(...) se ejecuta de forma asincrónica. Después de que el programa ejecuta copyFile(...) , no espera a que se complete la copia, sino que la ejecuta directamente hacia abajo, provocando el archivo. que aparezca el error ./to.txt no existe, o el contenido del archivo está vacío (si el archivo se creó con anticipación).
No se puede determinar la hora de finalización de ejecución específica de la función asincrónica de devolución de llamada. Por ejemplo, la hora de finalización de ejecución de readFile(from,to) probablemente dependa del tamaño del archivo from
Entonces, la pregunta es ¿cómo podemos localizar con precisión el final de la ejecución copyFile y leer el contenido to archivo?
Esto requiere el uso de una función de devolución de llamada. Podemos modificar la función copyFile de la siguiente manera:
function copyFile(from, to, callback) {
fs.readFile(de, (err, datos) => {
si (errar) {
consola.log(err.mensaje)
devolver
}
fs.writeFile(a, datos, (err) => {
si (errar) {
consola.log(err.mensaje)
devolver
}
console.log('Copia finalizada')
callback()//La función de devolución de llamada se llama cuando se completa la operación de copia})
})} De esta manera, si necesitamos realizar algunas operaciones inmediatamente después de que se complete la copia del archivo, podemos escribir estas operaciones en la función de devolución de llamada:
function copyFile(from, to, callback) {
fs.readFile(de, (err, datos) => {
si (errar) {
consola.log(err.mensaje)
devolver
}
fs.writeFile(a, datos, (err) => {
si (errar) {
consola.log(err.mensaje)
devolver
}
console.log('Copia finalizada')
callback()//La función de devolución de llamada se llama cuando se completa la operación de copia})
})}copiarArchivo('./from.txt', './to.txt', función () {
//Pasar una función de devolución de llamada, leer el contenido del archivo "to.txt" y generar fs.readFile('./to.txt', (err, data) => {
si (errar) {
consola.log(err.mensaje)
devolver
}
consola.log(data.toString())
})}) Si ha preparado el archivo ./from.txt , entonces el código anterior se puede ejecutar directamente:
PS E:CodeNodedemos�3-callback> node .index.js Copia terminada Únase a la comunidad "Xianzong" y cultive la inmortalidad conmigo Dirección de la comunidad: http://t.csdn.cn/EKf1h
Este método de programación se denomina estilo de programación asincrónico "basado en devolución de llamada". Las funciones ejecutadas de forma asincrónica deben proporcionar una devolución de llamada. solía llamar después de que finaliza la tarea.
Este estilo es común en la programación JavaScript . Por ejemplo, las funciones de lectura de archivos fs.readFile y fs.writeFile son todas funciones asincrónicas.
La función de devolución de llamada puede manejar con precisión asuntos posteriores después de que se completa el trabajo asincrónico. Si necesitamos realizar múltiples operaciones asincrónicas en secuencia, debemos anidar la función de devolución de llamada.
Escenario de caso:
implementación de código para leer el archivo A y el archivo B en secuencia:
fs.readFile('./A.txt', (err, data) => {
si (errar) {
consola.log(err.mensaje)
devolver
}
console.log('Leer el archivo A: ' + data.toString())
fs.readFile('./B.txt', (err, datos) => {
si (errar) {
consola.log(err.mensaje)
devolver
}
console.log("Leer el archivo B: " + data.toString())
})}) Efecto de ejecución:
PS E:CodeNodedemos�3-callback> node .index.js Leer el archivo A: Immortal Sect es infinitamente bueno, pero falta alguien. Leer el archivo B: si quieres unirte a Immortal Sect, debes tener el enlace http://t.csdn.cn/H1faI
. Después de A, el archivo B se lee inmediatamente.
¿Qué pasa si queremos seguir leyendo el archivo C después del archivo B? Esto requiere continuar anidando devoluciones de llamada:
fs.readFile('./A.txt', (err, data) => {//Primera devolución de llamada if (err) {
consola.log(err.mensaje)
devolver
}
console.log('Leer el archivo A: ' + data.toString())
fs.readFile('./B.txt', (err, data) => {//Segunda devolución de llamada if (err) {
consola.log(err.mensaje)
devolver
}
console.log("Leer el archivo B: " + data.toString())
fs.readFile('./C.txt',(err,data)=>{//La tercera devolución de llamada...
})
})}) En otras palabras, si queremos realizar múltiples operaciones asincrónicas en secuencia, necesitamos múltiples niveles de devoluciones de llamada anidadas. Esto es efectivo cuando el número de niveles es pequeño, pero cuando hay demasiados tiempos de anidamiento, surgirán algunos problemas. ocurrir pregunta.
Convenciones de devolución de llamada
De hecho, el estilo de las funciones de devolución de llamada en fs.readFile no es una excepción, sino una convención común en JavaScript . Personalizaremos una gran cantidad de funciones de devolución de llamada en el futuro y debemos cumplir con esta convención y formar buenos hábitos de codificación.
La convención es:
callback está reservado para errores. Una vez que ocurre un error, se llamará callback(err) .callback(null, result1, result2,...) .Según la convención anterior, una función de devolución de llamada tiene dos funciones: manejo de errores y recepción de resultados. Por ejemplo, la función de devolución de llamada de fs.readFile('...',(err,data)=>{}) sigue esta convención.
Si no profundizamos más, el procesamiento de métodos asincrónicos basados en devoluciones de llamadas parece ser una forma bastante perfecta de manejarlo. El problema es que si tenemos un comportamiento asincrónico tras otro, el código se verá así:
fs.readFile('./a.txt',(err,data)=>{
si(errar){
consola.log(err.mensaje)
devolver
}
//Leer el resultado de la operación fs.readFile('./b.txt',(err,data)=>{
si(errar){
consola.log(err.mensaje)
devolver
}
//Leer el resultado de la operación fs.readFile('./c.txt',(err,data)=>{
si(errar){
consola.log(err.mensaje)
devolver
}
//Leer el resultado de la operación fs.readFile('./d.txt',(err,data)=>{
si(errar){
consola.log(err.mensaje)
devolver
}
...
})
})
})}) El contenido de ejecución del código anterior es:
A medida que aumenta el número de llamadas, el nivel de anidamiento del código se vuelve cada vez más profundo, incluyendo más y más declaraciones condicionales, lo que resulta en un código confuso que está constantemente sangrado hacia la derecha, lo que dificulta su lectura y mantener.
¡A este fenómeno de crecimiento continuo hacia la derecha (sangría hacia la derecha) lo llamamos " infierno de devolución de llamada " o " pirámide de la perdición "!
fs.readFile('a.txt',(err,datos)=>{
fs.readFile('b.txt',(err,datos)=>{
fs.readFile('c.txt',(err,datos)=>{
fs.readFile('d.txt',(err,datos)=>{
fs.readFile('e.txt',(err,datos)=>{
fs.readFile('f.txt',(err,datos)=>{
fs.readFile('g.txt',(err,datos)=>{
fs.readFile('h.txt',(err,datos)=>{
...
/*
Puerta al infierno ===>
*/
})
})
})
})
})
})
})}) Aunque el código anterior parece bastante regular, es simplemente una situación ideal, por ejemplo. Por lo general, hay una gran cantidad de declaraciones condicionales, operaciones de procesamiento de datos y otros códigos en la lógica empresarial, lo que altera el hermoso orden actual y lo hace. el cambio de código es difícil de mantener.
Afortunadamente, JavaScript nos proporciona múltiples soluciones y Promise es la mejor solución.