Rastreamos toda la información de la página web en la sección anterior. Ahora tenemos que encontrar el contenido que necesitamos en el código html, por lo que debemos ingresar al sitio web de acuerdo con el problema y analizar la información en la página web.
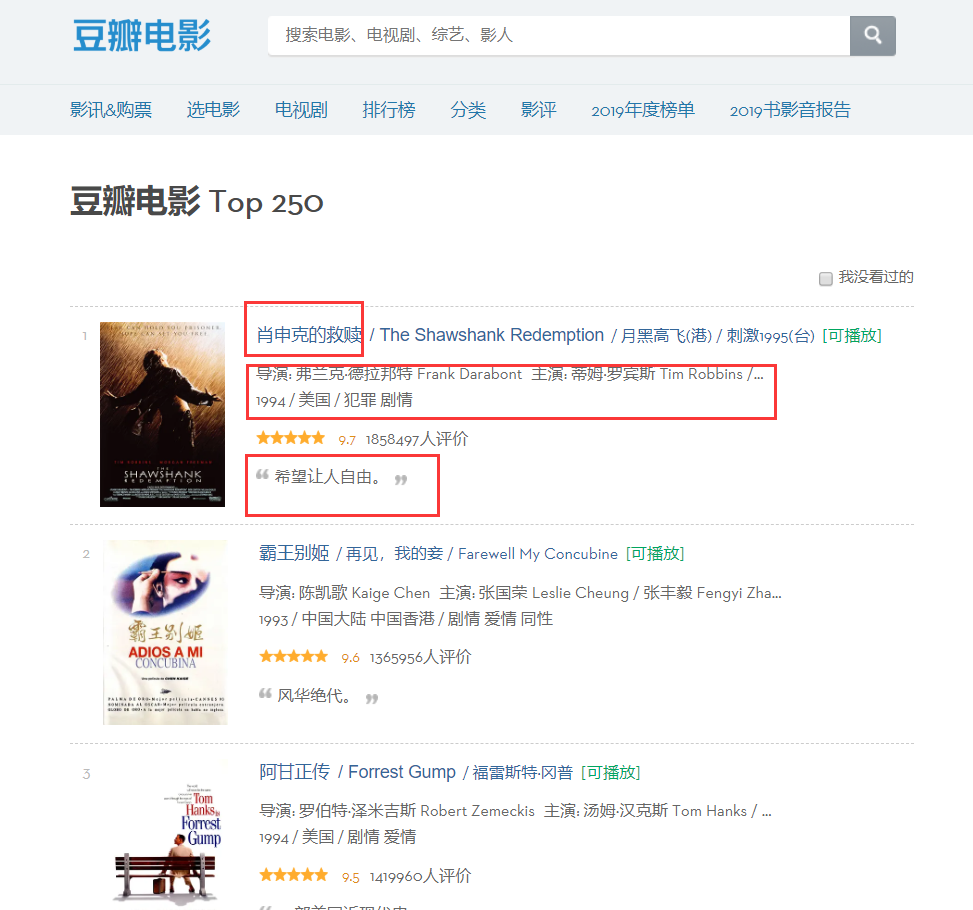
Se puede encontrar en la página que la información que necesitamos rastrear existe en diferentes particiones, así que verifiquemos los elementos de la página, hagamos clic derecho en la página para verificar el código fuente de la página web o F12.

Antes de analizar la página web, primero especificamos el método de almacenamiento después del análisis. Aquí usamos una lista para almacenar toda la información, y luego cada elemento de la lista corresponde a un diccionario, y cada diccionario corresponde a múltiples tipos de información.
movies=[]#Primero defina una lista para almacenar toda la información
A través del análisis, podemos determinar que la posición del título es el primer 'span' en la primera 'a' debajo del 'div' llamado 'hd', por lo que podemos bloquear el nombre de cada película a través del siguiente código, y luego en un diccionario.
moviename=each.find('div',class_='hd').a.span.text.strip()movie['title']=moviename#Un elemento en el diccionarioDe la misma forma, el código fuente del nombre del director se puede encontrar según el posicionamiento, pero este código fuente contiene mucha información, por lo que debemos filtrarlo mediante expresiones regulares.
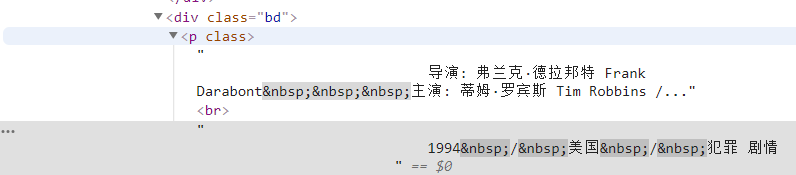
info=cada.find('div',class_='bd').p.text.strip()Primero, encontramos todo el contenido bajo esta etiqueta y luego filtramos la información irrelevante mediante expresiones regulares.
info=info.replace('n',)#Filtrar carro devuelve info=info.replace(,)#Filtrar espacios info=info.replace(xa0,)#Filtrar caracteres de espacios en blanco sin separación director=re.findall( r '[Director:].+[Protagonista:]',info)[0]director=director[3:len(director)-6]Luego defínalo como un elemento en el diccionario.
movie['director']=director#Un elemento en el diccionario
Podemos encontrar que el tipo de película también está en esta etiqueta 'p', y también obtenemos esta información directamente a través de expresiones regulares.
trama=re.findall(r'[0-9]*[/].+[/].+',info)[0]plot=trama[1:]plot=trama[plot.index('/') +1:]plot=plot[plot.index('/')+1:]movie['plot']=plot#Agregar como elemento en el diccionarioFinalmente, bloquee la información de calificación.
estrella=cada.find('div',class_='estrella')estrella=estrella.find('span',class_='rating_num').text.strip()Luego continúe guardándolo en forma de diccionario.
película['estrella']=estrella
Finalmente agregue este diccionario a la lista e itere sobre la salida.
movies.append(movie)#Agregar el diccionario a la lista paraiinmovies:#Recorrer la salida print(i)
importreimportrequestsfrombs4importBeautifulSoupforiinrange(1):headers={#Simular navegador para acceder a 'user-agent':'Mozilla/5.0(WindowsNT6.1;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/52.0.2743.82Safari/537. 36','Host':'movie.douban.com'}res='https://movie.douban.com/top250?start='+str(25*i)#25 veces r=requests.get(res ,headers=headers,timeout=10)#Establezca el tiempo de espera sopa=BeautifulSoup(r.text,html.parser)#Establezca el método de análisis, también se pueden usar otros métodos. div_list=soup.find_all('div',class_='item')movies=[]foreachindiv_list:movie={}moviename=each.find('div',class_='hd').a.span.text.strip ()película['título']=nombredepelícularank=cada.find('div',class_='pic').em.text .strip()movie['rank']=rankinfo=each.find('div',class_='bd').p.text.strip()info=info.replace('n',)info=info .replace(,)info=info.replace(xa0,)director=re.findall(r'[Director:].+[Protagonista:]',info)[0]director=director [3:len(director)-6]película['director']=directorrelease_date=re.findall(r'[0-9]{4}',info)[0]película['release_date']=release_dateplot=re .findall(r'[0-9]*[/].+[/].+',info)[0]plot=plot[1:]plot=plot[plot.index(' /')+1:]plot=plot[plot.index('/')+1:]película['plot']=plotstar=each.find('div',class_='star')star=estrella. find('span',class_='rating_num').text.strip()movie['star']=starmovies.append(movie)foriinmovies:print(i)Consola:

En este ejemplo, aprendemos principalmente cómo encontrar la información correspondiente en el código fuente de la página web. BeautifulSoup puede ayudarnos a localizarla rápidamente y luego combinarla con expresiones regulares para completar la comparación de información. guardará estos datos en la base de datos.