Se lanza OpenScholar, el artefacto de eficiencia de la investigación científica, que cambia por completo la experiencia de revisión de la literatura de los investigadores científicos. El editor de Downcodes le ofrece esta herramienta de investigación científica impulsada por IA. Tiene 450 millones de artículos de acceso abierto y 237 millones de incrustaciones de párrafos de artículos. Puede filtrar de forma rápida y precisa documentos relacionados con sus preguntas de investigación científica y generar respuestas completas a las referencias. OpenScholar no sólo es poderoso, sino que también puede aprender y mejorarse a sí mismo, mejorar continuamente la calidad de las respuestas y, en última instancia, presentar los resultados de investigación científica más perfectos. ¡También se puede utilizar para entrenar modelos más pequeños y eficientes, aportando cambios revolucionarios al campo de la investigación científica!
¿Quedarse despierto hasta tarde para revisar literatura? ¿Rascarse la cabeza y escribir un artículo? ¡No entre en pánico! ¡Los expertos en investigación científica de AI2 están aquí para salvarlo con su última obra maestra OpenScholar! ¡Este artefacto de eficiencia de investigación científica puede hacer que la revisión de literatura sea tan fácil y divertida! ¡Como caminar por el parque!
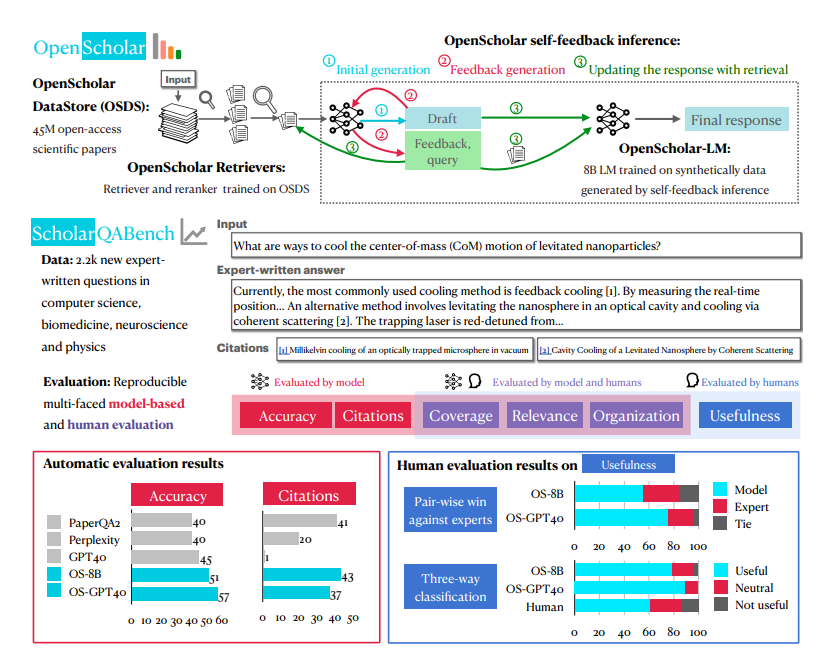
La mayor arma secreta de OpenScholar es un sistema llamado OpenScholar-Datastore (OSDS) con 450 millones de artículos de acceso abierto y 237 millones de párrafos de artículos integrados. Con una base de conocimientos tan sólida, OpenScholar puede abordar con facilidad diversos problemas de investigación científica.
Cuando encuentre un problema de investigación científica, OpenScholar primero enviará sus poderosas herramientas: el buscador y reordenador, para filtrar rápidamente los párrafos del artículo relacionados con su problema desde OSDS. A continuación, un modelo de lenguaje (LM) contiene la respuesta completa de la referencia. Lo que es aún más poderoso es que OpenScholar continuará mejorando las respuestas basándose en sus comentarios en lenguaje natural y complementará la información faltante hasta que esté satisfecho.
OpenScholar no sólo es potente por sí solo, sino que también puede ayudar a entrenar modelos más pequeños y eficientes. Los investigadores utilizaron el proceso de OpenScholar para generar cantidades masivas de datos de entrenamiento de alta calidad y utilizaron estos datos para entrenar un modelo de lenguaje de 8 mil millones de parámetros llamado OpenScholar-8B, así como otros modelos de recuperación.
Para probar exhaustivamente la efectividad en combate de OpenScholar, los investigadores también crearon especialmente un nuevo campo de pruebas llamado SCHOLARQABENCH. En este ámbito se establecen una variedad de tareas de revisión de literatura científica, incluida la clasificación cerrada, la opción múltiple y la generación de formato largo, que cubren múltiples campos como la informática, la biomedicina, la física y la neurociencia. Para garantizar la equidad y la justicia de la competencia, SCHOLARQABENCH también utiliza métodos de evaluación multifacéticos, que incluyen revisión de expertos, indicadores automáticos y pruebas de experiencia del usuario.
Después de muchas rondas de competencia feroz, OpenScholar finalmente se destacó. ¡Los resultados experimentales mostraron que tuvo un buen desempeño en varias tareas, incluso superando a los expertos humanos! ¡Este resultado revolucionario seguramente desencadenará una revolución en el campo de la investigación científica y permitirá a los científicos decir adiós a lo difícil! Trabajo de revisión de literatura, centrándose en explorar los misterios de la ciencia.
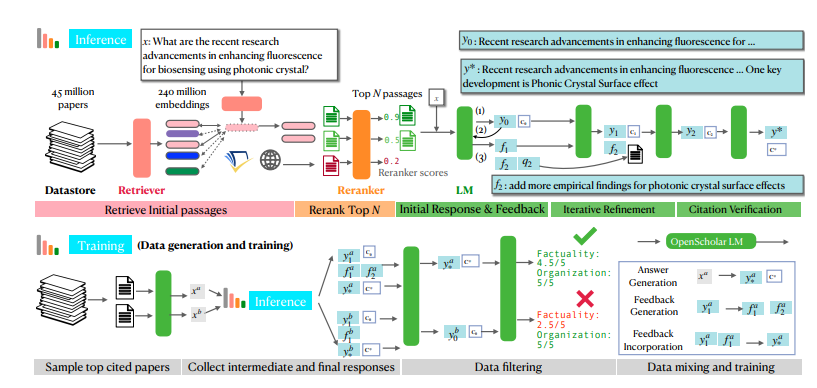
Las poderosas funciones de OpenScholar se benefician principalmente de su exclusivo mecanismo de razonamiento mejorado de recuperación de auto-retroalimentación. En pocas palabras, primero se hará preguntas, luego mejorará continuamente las respuestas en función de sus propias respuestas y finalmente le presentará la respuesta más perfecta. ¿No es asombroso?
Específicamente, el proceso de razonamiento de auto-retroalimentación de OpenScholar se divide en tres pasos: generación de respuesta inicial, generación de retroalimentación e integración de retroalimentación. Primero, el modelo de lenguaje genera una respuesta inicial basada en los pasajes del artículo recuperados. Luego, como un examinador severo, autocríticará sus respuestas, identificará deficiencias y generará comentarios en lenguaje natural, como "La respuesta solo contiene resultados experimentales en tareas de preguntas y respuestas, complemente otros tipos de resultados de tareas". . Finalmente, el modelo de lenguaje investigará la literatura relevante basándose en esta retroalimentación e integrará toda la información para generar una respuesta más completa.
Para entrenar modelos más pequeños pero igualmente poderosos, los investigadores también utilizaron el proceso de inferencia de auto-retroalimentación de OpenScholar para generar grandes cantidades de datos de entrenamiento de alta calidad. Primero seleccionaron los artículos más citados de la base de datos, luego generaron algunas preguntas de consulta de información basadas en los resúmenes de estos artículos y finalmente utilizaron el proceso de inferencia de OpenScholar para generar respuestas de alta calidad. Estas respuestas y la información de retroalimentación generada en el proceso constituyen datos de capacitación valiosos. Los investigadores combinaron estos datos con datos de ajuste de instrucción de dominio general existentes y datos de ajuste de instrucción de dominio científico para entrenar un modelo de lenguaje de 8 mil millones de parámetros llamado OpenScholar-8B.
Para evaluar más completamente el rendimiento de OpenScholar y otros modelos similares, los investigadores también crearon un nuevo punto de referencia llamado SCHOLARQABENCH. Este punto de referencia contiene 2967 preguntas de revisión de literatura escritas por expertos que cubren cuatro campos: informática, física, biomedicina y neurociencia. Cada pregunta tiene una respuesta extensa escrita por un experto y, en promedio, un experto tarda aproximadamente una hora en completar cada respuesta. SCHOLARQABENCH también emplea un enfoque de evaluación multifacético que combina métricas automatizadas y evaluación manual para proporcionar una medida más completa de la calidad de las respuestas generadas por el modelo.
Los resultados experimentales muestran que el rendimiento de OpenScholar en SCHOLARQABENCH supera con creces a otros modelos e incluso supera a los expertos humanos en algunos aspectos. Por ejemplo, en el campo de la informática, la tasa de corrección de OpenScholar-8B es un 5% mayor que la de GPT-4o, que es un 5% mayor. que el de GPT-4o. Además, la precisión de las citas de las respuestas generadas por OpenScholar es comparable a la de los expertos humanos, mientras que GPT-4o alcanza hasta un 78-90% de fabricación de la nada.
La aparición de OpenScholar es sin duda una gran ayuda para el campo de la investigación científica. ¡No solo puede ayudar a los investigadores científicos a ahorrar mucho tiempo y energía, sino también mejorar la calidad y eficiencia de las revisiones de la literatura! ¡Creo que en un futuro próximo OpenScholar se convertirá en un asistente indispensable para los investigadores científicos!
Dirección del artículo: https://arxiv.org/pdf/2411.14199
Dirección del proyecto: https://github.com/AkariAsai/OpenScholar
En definitiva, con sus potentes funciones y rendimiento eficiente, OpenScholar ha brindado una comodidad sin precedentes a los investigadores científicos y ha mejorado enormemente la eficiencia de la investigación científica. No es sólo una herramienta, sino también una revolución en el campo de la investigación científica. Vale la pena esperar su futuro desarrollo y aplicación.