El equipo de investigación del Instituto de Innovación en Computación de la Universidad de Zhejiang logró un gran avance en la solución del problema de la capacidad insuficiente de los modelos de lenguaje grandes para procesar datos tabulares y lanzó un nuevo modelo TableGPT2. Con su exclusivo codificador de tablas, TableGPT2 puede procesar de manera eficiente varios datos de tablas, aportando cambios revolucionarios a las aplicaciones basadas en datos, como la inteligencia empresarial (BI). El editor de Downcodes explicará en detalle la innovación y la dirección de desarrollo futuro de TableGPT2.
El auge de los grandes modelos de lenguaje (LLM) ha traído cambios revolucionarios a las aplicaciones de inteligencia artificial. Sin embargo, tienen deficiencias obvias en el procesamiento de datos tabulares. Para abordar este problema, un equipo de investigación del Instituto de Innovación en Computación de la Universidad de Zhejiang lanzó un nuevo modelo llamado TableGPT2, que puede integrar y procesar datos tabulares de manera directa y eficiente, abriendo nuevas vías para la inteligencia empresarial (BI) y otras tecnologías basadas en datos. Nuevas posibilidades.
La principal innovación de TableGPT2 radica en su exclusivo codificador de tablas, que está especialmente diseñado para capturar la información estructural y la información del contenido de las celdas de la tabla, mejorando así la capacidad del modelo para manejar consultas difusas, nombres de columnas faltantes y tablas irregulares que son comunes en la vida real. -Aplicaciones mundiales. TableGPT2 se basa en la arquitectura Qwen2.5 y se ha sometido a un entrenamiento previo y un ajuste fino a gran escala, que involucran más de 593,800 tablas y 2,36 millones de tuplas de salida de tablas de consulta de alta calidad, que es una escala sin precedentes de tablas relacionadas. datos en investigaciones anteriores.
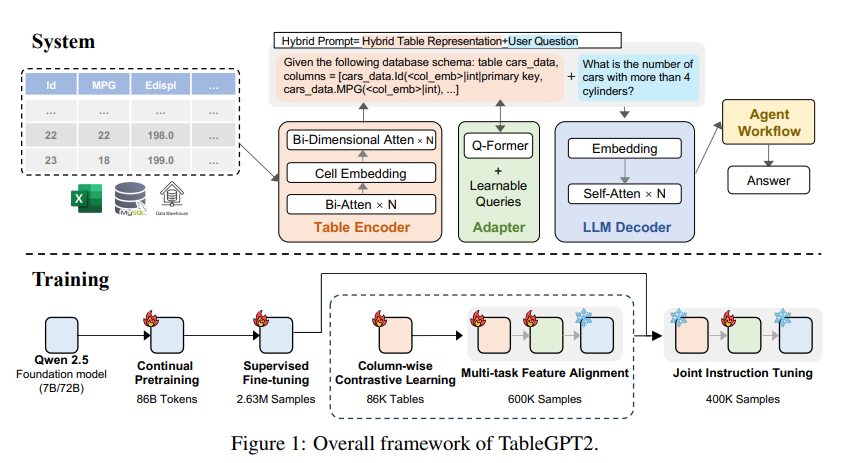
Para mejorar las capacidades de codificación y razonamiento de TableGPT2, los investigadores llevaron a cabo un entrenamiento previo continuo (CPT), en el que el 80% de los datos son códigos cuidadosamente anotados para garantizar que tengan sólidas capacidades de codificación. Además, también recopilaron una gran cantidad de datos de inferencia y libros de texto que contienen conocimientos de dominios específicos para mejorar las capacidades de inferencia del modelo. Los datos finales de CPT contienen 86 mil millones de tokens estrictamente filtrados, lo que proporciona las capacidades de codificación y razonamiento necesarias para que TableGPT2 maneje tareas complejas de BI y otras tareas relacionadas.
Para abordar las limitaciones de TableGPT2 a la hora de adaptarse a tareas y escenarios de BI específicos, los investigadores realizaron un ajuste fino supervisado (SFT). Crearon un conjunto de datos que cubre una variedad de escenarios críticos y del mundo real, incluidas múltiples rondas de conversaciones, razonamientos complejos, uso de herramientas y consultas altamente orientadas a los negocios. El conjunto de datos combina la anotación manual con un proceso de anotación automatizado dirigido por expertos para garantizar la calidad y relevancia de los datos. El proceso SFT, que utilizó un total de 2,36 millones de muestras, perfeccionó aún más el modelo para satisfacer las necesidades específicas de BI y otros entornos que involucran tablas.
TableGPT2 también presenta de manera innovadora un codificador de tabla semántica que toma la tabla completa como entrada y genera un conjunto compacto de vectores de incrustación para cada columna. Esta arquitectura está personalizada para las propiedades únicas de los datos tabulares, capturando de manera efectiva las relaciones entre filas y columnas a través de un mecanismo de atención bidireccional y un proceso de extracción de características jerárquicas. Además, se adopta un método de aprendizaje contrastivo de columnas para alentar al modelo a aprender representaciones semánticas tabulares significativas y conscientes de la estructura.
Para integrar perfectamente TableGPT2 con herramientas de análisis de datos de nivel empresarial, los investigadores también diseñaron un marco de ejecución de flujo de trabajo del agente. El marco consta de tres componentes principales: ingeniería de sugerencias en tiempo de ejecución, zona de pruebas de código seguro y módulo de evaluación del agente, que en conjunto mejoran las capacidades y la confiabilidad del agente. Los flujos de trabajo admiten tareas complejas de análisis de datos a través de pasos modulares (normalización de entradas, ejecución de agentes e invocación de herramientas) que funcionan en conjunto para administrar y monitorear el desempeño del agente. Al integrar Retrieval Augmented Generation (RAG) para una recuperación contextual eficiente y un espacio aislado de código para una ejecución segura, el marco garantiza que TableGPT2 brinde información precisa y sensible al contexto en problemas del mundo real.
Los investigadores realizaron una evaluación exhaustiva de TableGPT2 en una variedad de puntos de referencia tabulares y de propósito general ampliamente utilizados. Los resultados muestran que TableGPT2 sobresale en la comprensión, el procesamiento y el razonamiento de tablas, con una mejora promedio del rendimiento del 35,20% para un modelo de 7 mil millones de parámetros, 720. El rendimiento medio del modelo de 100 millones de parámetros aumentó un 49,32%, manteniendo al mismo tiempo un sólido rendimiento general. Para una evaluación justa, solo compararon TableGPT2 con modelos de código abierto neutrales en cuanto a puntos de referencia, como Qwen y DeepSeek, lo que garantiza un rendimiento equilibrado y versátil del modelo en una variedad de tareas sin sobreajustar ninguna prueba de punto de referencia. También introdujeron y lanzaron parcialmente un nuevo punto de referencia, RealTabBench, que enfatiza tablas no convencionales, campos anónimos y consultas complejas para ser más consistentes con escenarios de la vida real.
Aunque TableGPT2 logra un rendimiento de vanguardia en experimentos, todavía existen desafíos en la implementación de LLM en entornos de BI del mundo real. Los investigadores señalaron que las direcciones de investigación futuras incluyen:
Codificación específica de dominio: permite que LLM adapte rápidamente lenguajes específicos de dominio (DSL) o pseudocódigos específicos de la empresa para satisfacer mejor las necesidades específicas de la infraestructura de datos empresariales.
Diseño de agentes múltiples: explore cómo integrar eficazmente varios LLM en un sistema unificado para manejar la complejidad de las aplicaciones del mundo real.
Procesamiento de tablas versátil: mejore la capacidad del modelo para manejar tablas irregulares, como celdas fusionadas y estructuras inconsistentes comunes en Excel y Pages, para manejar mejor diversas formas de datos tabulares en el mundo real.
El lanzamiento de TableGPT2 marca el progreso significativo de LLM en el procesamiento de datos tabulares, brindando nuevas posibilidades para la inteligencia empresarial y otras aplicaciones basadas en datos. Creo que a medida que la investigación continúe profundizándose, TableGPT2 desempeñará un papel cada vez más importante en el campo del análisis de datos en el futuro.
Dirección del artículo: https://arxiv.org/pdf/2411.02059v1
La aparición de TableGPT2 ha traído un nuevo amanecer al campo de la inteligencia empresarial. Sus eficientes capacidades de procesamiento de datos de tablas y su gran escalabilidad indican que el análisis de datos será más inteligente y conveniente en el futuro. Esperamos que TableGPT2 se utilice más ampliamente en el futuro y aporte más valor a todos los ámbitos de la vida.