La comprensión de videos ultralargos siempre ha sido un problema difícil para los modelos de lenguaje grande multimodal (MLLM). Los modelos existentes tienen dificultades para procesar datos de video que exceden la longitud máxima del contexto, y la atenuación de la información y los altos costos computacionales también son un desafío importante. El editor de Downcodes se enteró de que el Instituto de Investigación Zhiyuan y varias universidades han propuesto un modelo de lenguaje visual ultralargo llamado Video-XL, que está diseñado para manejar de manera eficiente problemas de comprensión de videos a nivel de horas. La tecnología central de este modelo es el "resumen latente de contexto visual", que utiliza inteligentemente las capacidades de modelado de contexto de LLM para comprimir representaciones visuales largas en una forma más compacta, similar a condensar una vaca entera en un plato de esencia de carne, haciendo que el modelo más eficiente. Absorber información clave.
Actualmente, los modelos multimodales de lenguaje grande (MLLM) han logrado avances significativos en el campo de la comprensión de videos, pero procesar videos extremadamente largos sigue siendo un desafío. Esto se debe a que MLLM normalmente tiene dificultades para manejar miles de tokens visuales que exceden la longitud máxima del contexto y sufre el deterioro de la información causado por la agregación de tokens. Al mismo tiempo, una gran cantidad de etiquetas de video también traerá altos costos computacionales.
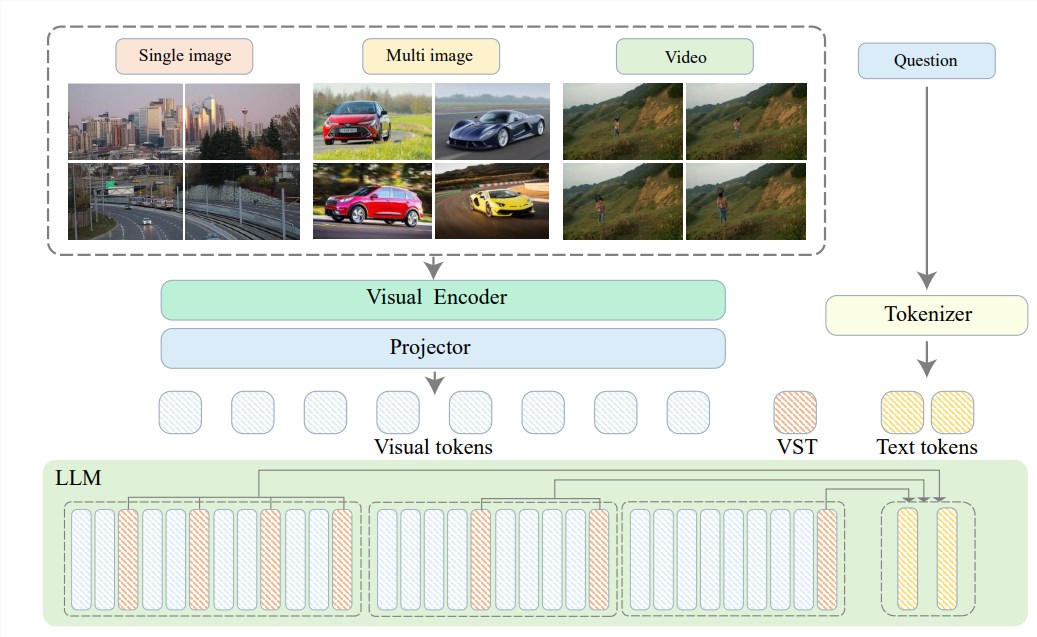
Para resolver estos problemas, el Instituto de Investigación Zhiyuan se asoció con la Universidad Jiao Tong de Shanghai, la Universidad Renmin de China, la Universidad de Pekín, la Universidad de Correos y Telecomunicaciones de Beijing y otras universidades para proponer Video-XL, un sistema de ultra alta definición diseñado para Comprensión eficiente de videos a nivel de horas. Modelo de lenguaje visual largo. El núcleo de Video-XL radica en la tecnología de "resumen latente de contexto visual", que aprovecha las capacidades inherentes de modelado de contexto de LLM para comprimir de manera efectiva representaciones visuales largas en una forma más compacta.
En pocas palabras, se trata de comprimir el contenido del video en una forma más simplificada, como condensar una vaca entera en un tazón de esencia de carne, que es más fácil de digerir y absorber para el modelo.
Esta tecnología de compresión no sólo mejora la eficiencia, sino que también preserva eficazmente la información clave del vídeo. Ya sabes, los vídeos largos suelen estar llenos de mucha información redundante, como el calzado de una anciana, largo y maloliente. Video-XL puede eliminar con precisión esta información inútil y retener sólo las partes esenciales, lo que garantiza que el modelo no pierda el rumbo al comprender contenidos de vídeo largos.
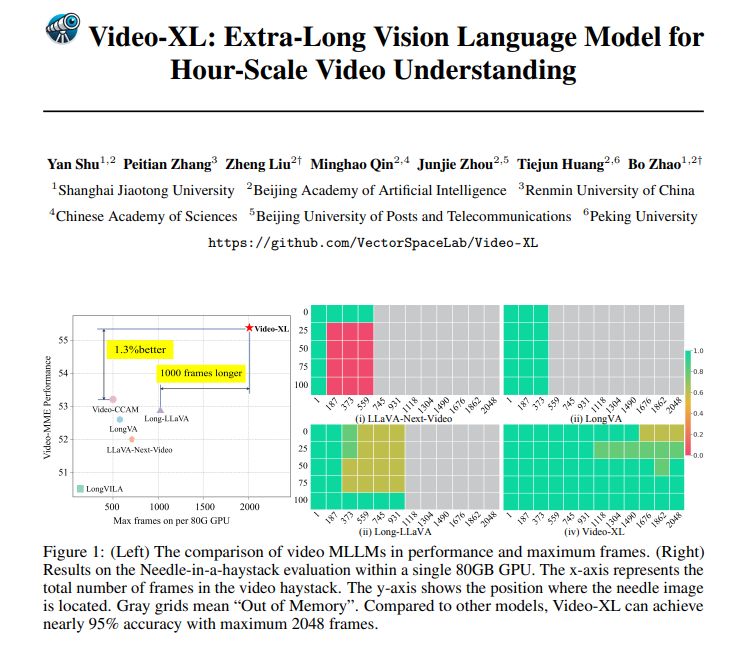
Video-XL no sólo es fantástico en teoría, sino que también es muy eficaz en la práctica. Video-XL ha logrado resultados líderes en múltiples pruebas comparativas de comprensión de videos largos, especialmente en la prueba VNBench, donde su precisión es casi un 10 % mayor que la de los mejores métodos existentes.
Aún más impresionante, Video-XL logra un equilibrio sorprendente entre eficiencia y efectividad, capaz de procesar 2048 cuadros de video en una sola GPU de 80 GB y al mismo tiempo mantener casi el 95% de precisión en la evaluación de "aguja en el pajar".
Video-XL también tiene amplias perspectivas de aplicación. Además de poder comprender vídeos largos en general, también es capaz de realizar tareas específicas como resumen de películas, detección de anomalías de vigilancia y reconocimiento de ubicación de anuncios.
Esto significa que ya no tendrá que soportar largas tramas cuando vea películas en el futuro. Puede usar Video-XL directamente para generar un resumen optimizado, ahorrando tiempo y esfuerzo, o puede usarlo para monitorear imágenes de vigilancia e identificar automáticamente eventos anormales. , que es mucho más eficiente que el seguimiento manual.
Dirección del proyecto: https://github.com/VectorSpaceLab/Video-XL
Documento: https://arxiv.org/pdf/2409.14485
Video-XL ha logrado avances importantes en el campo de la comprensión de videos ultralargos. Su combinación perfecta de eficiencia y precisión proporciona una nueva solución para el procesamiento de videos largos. Tiene amplias perspectivas de aplicación en el futuro y vale la pena esperarlo.