La formación de modelos grandes requiere mucho tiempo y mano de obra. Cómo mejorar la eficiencia y reducir el consumo de energía se ha convertido en una cuestión clave en el campo de la IA. AdamW, como optimizador predeterminado para el entrenamiento previo de Transformer, gradualmente no puede hacer frente a modelos cada vez más grandes. El editor de Downcodes lo llevará a conocer un nuevo optimizador desarrollado por un equipo chino: C-AdamW. Con su estrategia "cautelosa", reduce en gran medida el consumo de energía al tiempo que garantiza la velocidad y la estabilidad del entrenamiento, y aporta grandes beneficios al entrenamiento de modelos grandes. . para revolucionar el cambio.
En el mundo de la IA, trabajar duro para lograr milagros parece ser la regla de oro. Cuanto más grande es el modelo, más datos y mayor es la potencia informática, más cerca parece estar del Santo Grial de la inteligencia. Sin embargo, detrás de este rápido desarrollo también hay enormes presiones sobre los costos y el consumo de energía.
Para hacer que el entrenamiento de IA sea más eficiente, los científicos han estado buscando optimizadores más potentes, como un entrenador, para guiar los parámetros del modelo para optimizar continuamente y, en última instancia, alcanzar el mejor estado. AdamW, como optimizador predeterminado para el preentrenamiento de Transformer, ha sido el punto de referencia de la industria durante muchos años. Sin embargo, ante la creciente escala del modelo, AdamW también comenzó a parecer incapaz de hacer frente a sus capacidades.
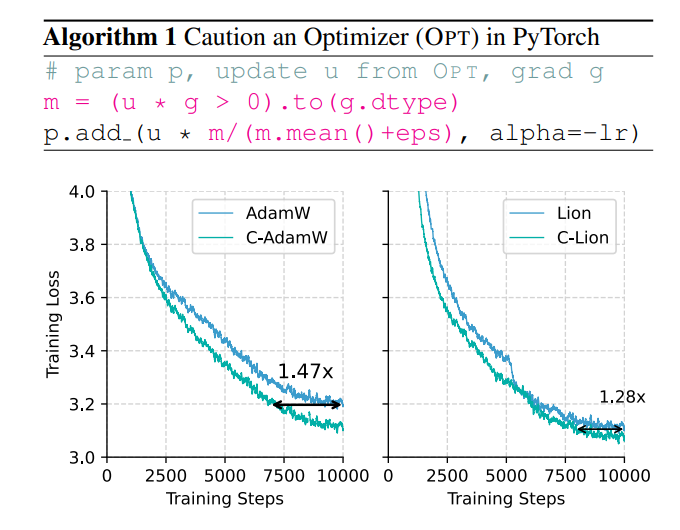
¿No hay alguna manera de aumentar la velocidad de entrenamiento y al mismo tiempo reducir el consumo de energía? ¡No te preocupes, un equipo totalmente chino está aquí con su arma secreta C-AdamW!
El nombre completo de C-AdamW es Cautious AdamW, y su nombre chino es Cautious AdamW. ¿No suena muy budista? Sí, la idea central de C-AdamW es pensar dos veces antes de actuar.

Imagine que los parámetros del modelo son como un grupo de niños enérgicos que siempre quieren correr. AdamW es como un maestro dedicado, que intenta guiarlos en la dirección correcta. Pero a veces los niños se emocionan demasiado y corren en la dirección equivocada, perdiendo tiempo y energía.
En este momento, C-AdamW es como un anciano sabio con un par de ojos penetrantes, capaz de identificar con precisión si la dirección de actualización es correcta. Si la dirección es incorrecta, C-AdamW detendrá decisivamente para evitar que el modelo siga por el camino equivocado.
Esta estrategia cautelosa garantiza que cada actualización pueda reducir efectivamente la función de pérdida, acelerando así la convergencia del modelo. ¡Los resultados experimentales muestran que C-AdamW aumenta la velocidad de entrenamiento a 1,47 veces en el preentrenamiento de Llama y MAE!
Más importante aún, C-AdamW casi no requiere sobrecarga computacional adicional y se puede implementar con una simple modificación de una línea del código existente. ¡Esto significa que los desarrolladores pueden aplicar fácilmente C-AdamW a varios modelos de entrenamiento y disfrutar de la velocidad y la pasión!
Lo bueno de C-AdamW es que conserva la función hamiltoniana de Adam y no destruye la garantía de convergencia según el análisis de Lyapunov. Esto significa que C-AdamW no sólo es más rápido, sino que también garantiza su estabilidad y no habrá problemas como caídas de entrenamiento.
Por supuesto, ser budista no significa que no seas emprendedor. El equipo de investigación afirmó que continuarán explorando funciones ϕ más ricas y aplicarán máscaras en el espacio de características en lugar del espacio de parámetros para mejorar aún más el rendimiento de C-AdamW.
¡Es previsible que C-AdamW se convierta en el nuevo favorito en el campo del aprendizaje profundo, trayendo cambios revolucionarios al entrenamiento de modelos grandes!
Dirección del artículo: https://arxiv.org/abs/2411.16085
GitHub:
https://github.com/kyleliang919/C-Optim
La aparición de C-AdamW proporciona nuevas ideas para resolver los problemas de eficiencia del entrenamiento de modelos grandes y consumo de energía. Su alta eficiencia, estabilidad y características fáciles de usar lo hacen muy prometedor para su aplicación. Se espera que C-AdamW pueda aplicarse en más campos en el futuro y promover el desarrollo continuo de la tecnología de IA. El editor de Downcodes seguirá prestando atención a los avances tecnológicos relevantes, ¡así que estad atentos!