El editor de Downcodes se enteró de que la Universidad de Pekín y otros equipos de investigación científica han lanzado LLaVA-o1, un modelo histórico de código abierto multimodal. El modelo superó a competidores como Gemini, GPT-4o-mini y Llama en múltiples pruebas comparativas, y su mecanismo de razonamiento de "pensamiento lento" le permitió realizar un razonamiento más complejo, comparable al GPT-o1. El código abierto de LLaVA-o1 aportará nueva vitalidad a la investigación y aplicación en el campo de la IA multimodal.
Recientemente, la Universidad de Pekín y otros equipos de investigación científica anunciaron el lanzamiento de un modelo multimodal de código abierto llamado LLaVA-o1, que se dice que es el primer modelo de lenguaje visual capaz de razonamiento espontáneo y sistemático, comparable a GPT-o1.
El modelo funciona bien en seis exigentes pruebas multimodales, y su versión de parámetros 11B supera a otros competidores como Gemini-1.5-pro, GPT-4o-mini y Llama-3.2-90B-Vision-Instruct.
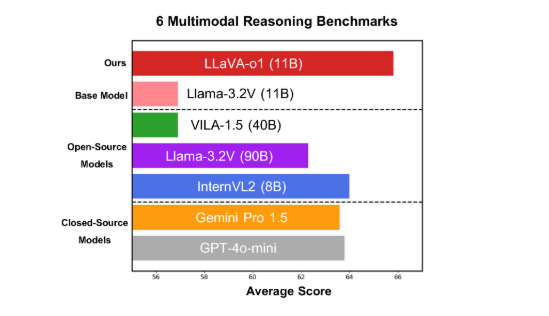
LLaVA-o1 se basa en el modelo Llama-3.2-Vision y adopta un mecanismo de razonamiento de "pensamiento lento", que puede realizar de forma independiente procesos de razonamiento más complejos, superando el método tradicional de indicación de cadena de pensamiento.
En el punto de referencia de inferencia multimodal, LLaVA-o1 superó a su modelo base en un 8,9%. El modelo es único porque su proceso de razonamiento se divide en cuatro etapas: resumen, explicación visual, razonamiento lógico y generación de conclusiones. En los modelos tradicionales, el proceso de razonamiento suele ser relativamente simple y puede conducir fácilmente a respuestas incorrectas, mientras que LLaVA-o1 garantiza resultados más precisos a través de un razonamiento estructurado de varios pasos.
Por ejemplo, al resolver el problema "¿Cuántos objetos quedan después de restar todas las pequeñas bolas brillantes y los objetos morados?", LLaVA-o1 primero resumirá el problema, luego extraerá información de la imagen y luego realizará un razonamiento paso a paso. y finalmente dar Respuesta. Este enfoque por etapas mejora las capacidades de razonamiento sistemático del modelo, haciéndolo más eficiente en el manejo de problemas complejos.

Vale la pena mencionar que LLaVA-o1 introduce un método de búsqueda de haz a nivel de etapa en el proceso de inferencia. Este enfoque permite que el modelo genere múltiples respuestas candidatas en cada etapa de inferencia y seleccione la mejor respuesta para pasar a la siguiente etapa de inferencia, mejorando así significativamente la calidad general de la inferencia. Con ajustes supervisados y datos de entrenamiento razonables, LLaVA-o1 funciona bien en comparación con modelos más grandes o de código cerrado.
Los resultados de la investigación del equipo de la Universidad de Pekín no sólo promueven el desarrollo de IA multimodal, sino que también proporcionan nuevas ideas y métodos para futuros modelos de comprensión del lenguaje visual. El equipo afirmó que el código, los pesos previos al entrenamiento y los conjuntos de datos de LLaVA-o1 serán completamente de código abierto y esperan que más investigadores y desarrolladores exploren y apliquen conjuntamente este modelo innovador.
Documento: https://arxiv.org/abs/2411.10440
GitHub: https://github.com/PKU-YuanGroup/LLaVA-o1
El código abierto de LLaVA-o1 sin duda promoverá el desarrollo tecnológico y la innovación de aplicaciones en el campo de la IA multimodal. Su eficiente mecanismo de inferencia y su excelente rendimiento lo convierten en una referencia importante para futuras investigaciones sobre modelos de lenguaje visual y merecen atención y anticipación. Esperamos que más desarrolladores participen y promuevan conjuntamente el progreso de la tecnología de inteligencia artificial.