¿Tiene curiosidad acerca de la tecnología detrás de productos de inteligencia artificial como ChatGPT y Wenxinyiyan? Todos ellos se basan en modelos de lenguaje grande (LLM). El editor de Downcodes te llevará a comprender el principio operativo de LLM de una manera simple y fácil de entender. Incluso si solo tienes un nivel de matemáticas de segundo grado, ¡puedes entenderlo fácilmente! Comenzaremos con los conceptos básicos de las redes neuronales y explicaremos gradualmente el entrenamiento de modelos, las técnicas avanzadas y las tecnologías centrales como GPT y la arquitectura Transformer, para que tenga una comprensión clara de LLM.
¿Has oído hablar de IA avanzada como ChatGPT y Wen Xinyiyan? La tecnología central detrás de ellos es el "modelo de lenguaje grande" (LLM). ¿Le resulta complicado y difícil de entender? No se preocupe, incluso si solo tiene un nivel de matemáticas de segundo grado, podrá comprender fácilmente el principio operativo de LLM después de leer este artículo.
Redes neuronales: la magia de los números
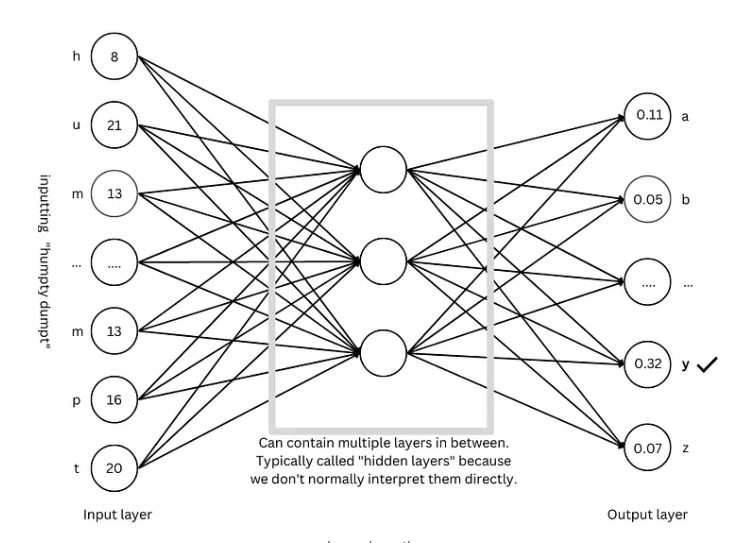
Primero, necesitamos saber que una red neuronal es como una supercomputadora: solo puede procesar números. Tanto la entrada como la salida deben ser números. Entonces, ¿cómo hacemos que comprenda el texto?
¡El secreto está en convertir palabras en números! Por ejemplo, podemos representar cada letra con un número, como a=1, b=2, etc. De esta forma, la red neuronal puede "leer" el texto.
Entrenando el modelo: Deje que la red “aprenda” el idioma
Con el texto digital, el siguiente paso es entrenar el modelo y dejar que la red neuronal "aprenda" las reglas del lenguaje.
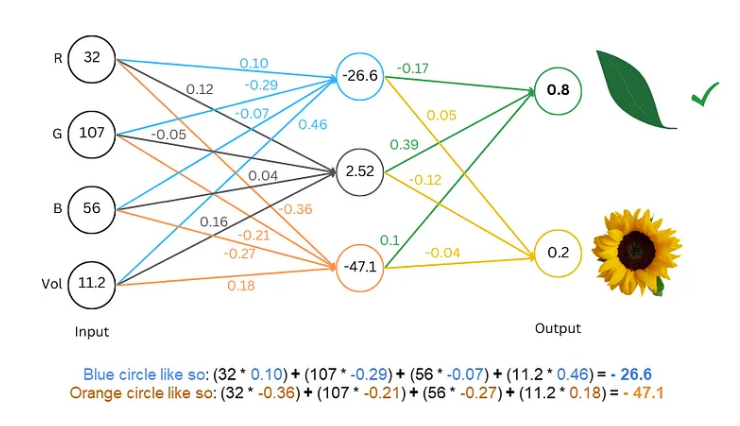
El proceso de formación es como jugar a un juego de adivinanzas. Le mostramos a la red algún texto, como "Humpty Dumpty", y le pedimos que adivine cuál es la siguiente letra. Si adivina correctamente, le damos una recompensa; si adivina mal, le damos una penalización. Al adivinar y ajustar constantemente, la red puede predecir la siguiente letra con mayor precisión y, eventualmente, producir oraciones completas como "Humpty Dumpty se sentó en una pared".
Técnicas avanzadas: hacer que el modelo sea más "inteligente"
Para hacer el modelo más "inteligente", los investigadores han inventado muchas técnicas avanzadas, como:
Incrustación de palabras: en lugar de usar números simples para representar letras, usamos un conjunto de números (vectores) para representar cada palabra, que puede describir más completamente el significado de la palabra.
Segmentador de subpalabras: divida palabras en unidades más pequeñas (subpalabras), como dividir "gatos" en "gato" y "s", lo que puede reducir el vocabulario y mejorar la eficiencia.
Mecanismo de autoatención: cuando el modelo predice la siguiente palabra, ajustará el peso de la predicción en función de todas las palabras en el contexto, tal como entendemos el significado de la palabra según el contexto cuando leemos.
Conexión residual: para evitar las dificultades de entrenamiento causadas por demasiadas capas de red, los investigadores inventaron la conexión residual para hacer que la red sea más fácil de aprender.
Mecanismo de atención de múltiples cabezas: al ejecutar múltiples mecanismos de atención en paralelo, el modelo puede comprender el contexto desde diferentes perspectivas y mejorar la precisión de las predicciones.
Codificación posicional: para que el modelo comprenda el orden de las palabras, los investigadores agregarán información posicional a las incrustaciones de palabras, tal como prestamos atención al orden de las palabras cuando leemos.
Arquitectura GPT: el "modelo" para modelos de lenguaje a gran escala
La arquitectura GPT es una de las arquitecturas de modelos de lenguaje a gran escala más populares en la actualidad. Es como un "plano" que guía el diseño y el entrenamiento del modelo. La arquitectura GPT combina inteligentemente las técnicas avanzadas mencionadas anteriormente para permitir que el modelo aprenda y genere lenguaje de manera eficiente.
Arquitectura transformadora: la “revolución” de los modelos de lenguaje
La arquitectura Transformer es un gran avance en el campo de los modelos de lenguaje en los últimos años. No solo mejora la precisión de la predicción, sino que también reduce la dificultad del entrenamiento, sentando las bases para el desarrollo de modelos de lenguaje a gran escala. La arquitectura GPT también evolucionó basándose en la arquitectura Transformer.
Referencia: https://towardsdatascience.com/understanding-llms-from-scratch-using-middle-school-math-e602d27ec876
Espero que la explicación del editor de Downcodes pueda ayudarlo a comprender los principios operativos de los modelos de lenguaje grandes. Por supuesto, la tecnología LLM aún se está desarrollando. Este artículo es solo la punta del iceberg. ¡Cada vez hay más contenido en profundidad que requiere que continúes aprendiendo y explorando!