El editor de Downcodes se enteró de que Meta lanzó recientemente un nuevo comando de diálogo de múltiples turnos en varios idiomas después de la prueba comparativa de evaluación de habilidades Multi-IF. El punto de referencia cubre ocho idiomas y contiene 4501 tareas de diálogo de tres rondas, con el objetivo de evaluar de manera más integral los grandes. Rendimiento de modelos de lenguaje (LLM) en aplicaciones prácticas. A diferencia de los estándares de evaluación existentes que se centran principalmente en el diálogo de un solo turno y tareas en un solo idioma, Multi-IF se enfoca en examinar la capacidad del modelo en escenarios complejos de múltiples turnos y múltiples idiomas, proporcionando una dirección más clara para la mejora de LLM.
Meta lanzó recientemente una nueva prueba de referencia llamada Multi-IF, que está diseñada para evaluar la capacidad de seguir instrucciones de modelos de lenguaje grandes (LLM) en conversaciones de varios turnos y entornos multilingües. Este punto de referencia cubre ocho idiomas y contiene 4501 tareas de diálogo de tres turnos, centrándose en el rendimiento de los modelos actuales en escenarios complejos de múltiples turnos y múltiples idiomas.
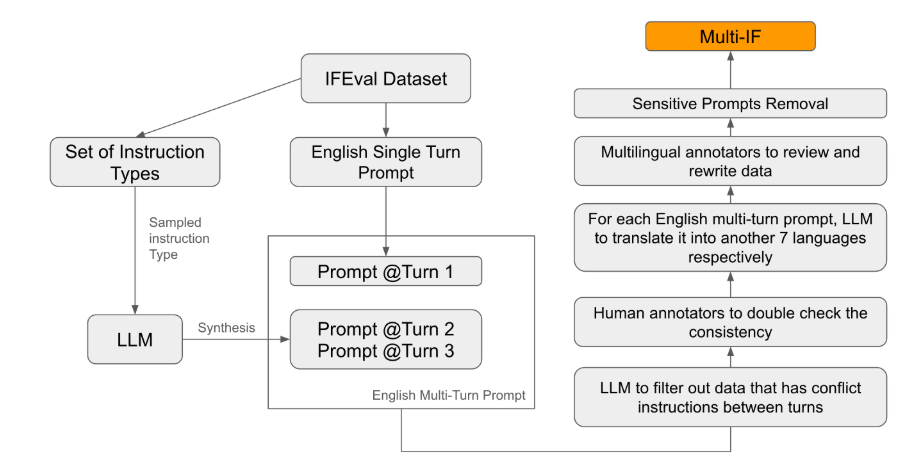
Entre los estándares de evaluación existentes, la mayoría se centra en el diálogo de un solo turno y las tareas en un solo idioma, que son difíciles de reflejar completamente el desempeño del modelo en aplicaciones prácticas. El lanzamiento de Multi-IF tiene como objetivo llenar este vacío. El equipo de investigación generó escenarios de diálogo complejos extendiendo una única ronda de instrucciones a múltiples rondas de instrucciones, y se aseguró de que cada ronda de instrucciones fuera lógicamente coherente y progresiva. Además, el conjunto de datos también logra soporte en varios idiomas a través de pasos como la traducción automática y la revisión manual.
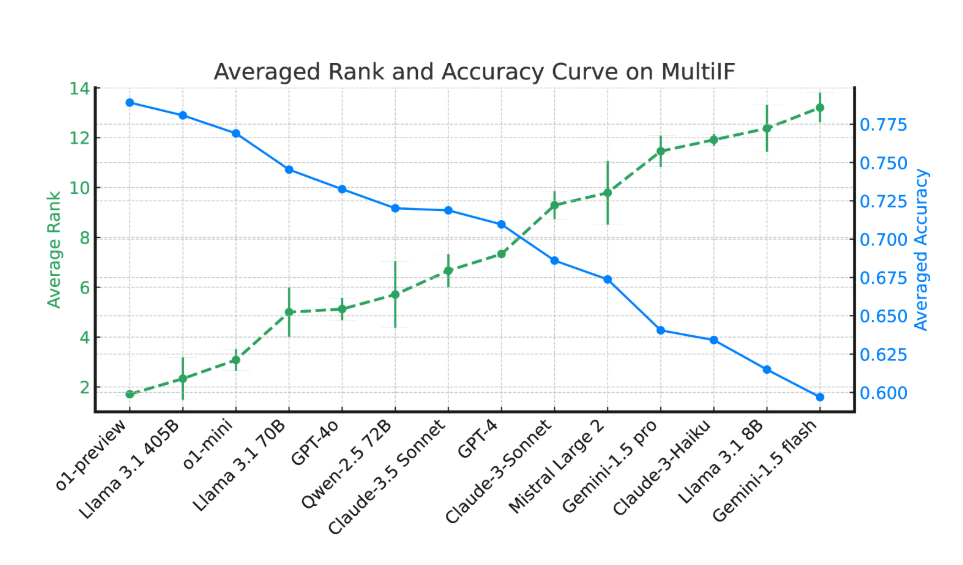
Los resultados experimentales muestran que el rendimiento de la mayoría de los LLM cae significativamente durante múltiples rondas de diálogo. Tomando como ejemplo el modelo de vista previa de o1, su precisión promedio en la primera ronda fue del 87,7%, pero cayó al 70,7% en la tercera ronda. Especialmente en idiomas con escrituras no latinas, como hindi, ruso y chino, el rendimiento del modelo es generalmente inferior al del inglés, lo que muestra limitaciones en tareas multilingües.
En la evaluación de 14 modelos de lenguaje de vanguardia, o1-preview y Llama3.1405B obtuvieron los mejores resultados, con tasas de precisión promedio del 78,9 % y 78,1 % en tres rondas de instrucciones, respectivamente. Sin embargo, a lo largo de múltiples rondas de diálogo, todos los modelos mostraron una disminución general en su capacidad para seguir instrucciones, lo que refleja los desafíos que enfrentan los modelos en tareas complejas. El equipo de investigación también introdujo la "tasa de olvido de instrucciones" (IFR) para cuantificar el fenómeno de olvido de instrucciones del modelo en múltiples rondas de diálogo. Los resultados muestran que los modelos de alto rendimiento funcionan relativamente bien en este sentido.
El lanzamiento de Multi-IF proporciona a los investigadores un punto de referencia desafiante y promueve el desarrollo de LLM en globalización y aplicaciones multilingües. El lanzamiento de este punto de referencia no solo revela las deficiencias de los modelos actuales en tareas de múltiples rondas y múltiples idiomas, sino que también proporciona una dirección clara para futuras mejoras.
Documento: https://arxiv.org/html/2410.15553v2
El lanzamiento de la prueba comparativa Multi-IF proporciona una referencia importante para la investigación de modelos de lenguaje grandes en diálogos de múltiples turnos y procesamiento de múltiples idiomas, y también señala el camino para futuras mejoras del modelo. Se espera que en el futuro surjan LLM cada vez más potentes para afrontar mejor los desafíos de tareas complejas de múltiples rondas y en varios idiomas.