El equipo Emu3 del Instituto de Investigación Zhiyuan ha lanzado el revolucionario modelo multimodal Emu3, que subvierte la arquitectura tradicional del modelo multimodal, entrena basándose únicamente en la predicción del siguiente token y logra rendimiento SOTA en tareas de generación y percepción. El equipo de Emu3 tokeniza inteligentemente imágenes, texto y videos en espacios discretos y entrena un único modelo Transformer en secuencias multimodales mixtas, logrando la unificación de tareas multimodales sin depender de arquitecturas de difusión o combinación, lo que proporciona múltiples El campo modal trae nuevos avances.
El equipo Emu3 del Instituto de Investigación Zhiyuan ha lanzado un nuevo modelo multimodal Emu3. Este modelo se entrena únicamente en función de la predicción del siguiente token, subvirtiendo el modelo de difusión tradicional y la arquitectura del modelo combinado, y logra resultados tanto en tareas de generación como de estado de percepción. Rendimiento de última generación.
La predicción del próximo token se ha considerado durante mucho tiempo un camino prometedor hacia la inteligencia artificial general (AGI), pero ha tenido un desempeño deficiente en tareas multimodales. Actualmente, el campo multimodal todavía está dominado por modelos de difusión (como la Difusión Estable) y modelos combinados (como la combinación de CLIP y LLM). El equipo de Emu3 tokeniza imágenes, texto y videos en espacios discretos y entrena un único modelo Transformer desde cero en secuencias multimodales mixtas, unificando así tareas multimodales sin depender de arquitecturas de difusión o combinacionales.
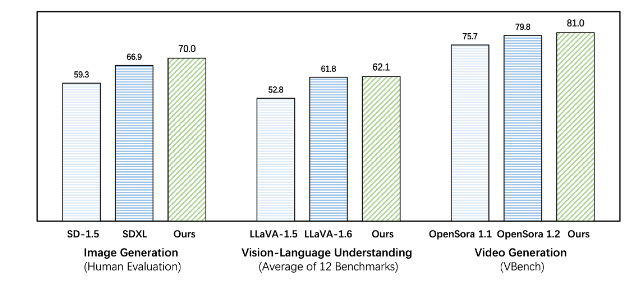
Emu3 supera a los modelos existentes de tareas específicas tanto en tareas de generación como de percepción, superando incluso a modelos emblemáticos como SDXL y LLaVA-1.6. Emu3 también puede generar vídeos de alta fidelidad prediciendo el siguiente token en una secuencia de vídeo. A diferencia de Sora, que utiliza un modelo de difusión de video para generar videos a partir de ruido, Emu3 genera videos de manera causal al predecir el siguiente token en la secuencia de video. El modelo puede simular ciertos aspectos de entornos, personas y animales del mundo real y predecir lo que sucederá a continuación dado el contexto del video.
Emu3 simplifica el diseño de modelos multimodales complejos y se centra en los tokens, desbloqueando un enorme potencial de escalamiento durante el entrenamiento y la inferencia. Los resultados de la investigación muestran que la predicción del próximo token es una forma eficaz de desarrollar inteligencia multimodal general más allá del lenguaje. Para respaldar una mayor investigación en esta área, el equipo de Emu3 ha abierto tecnologías y modelos clave, incluido un potente tokenizador visual que puede convertir vídeos e imágenes en tokens discretos, que no había estado disponible públicamente antes.
El éxito de Emu3 señala la dirección para el desarrollo futuro de modelos multimodales y trae nuevas esperanzas para la realización de AGI.
Dirección del proyecto: https://github.com/baaivision/Emu3
El editor de Downcodes resume: La aparición del modelo Emu3 marca un nuevo hito en el campo multimodal. Su arquitectura simple y su potente rendimiento brindan nuevas ideas y direcciones para futuras investigaciones de AGI. La estrategia de código abierto también promueve el desarrollo conjunto de la academia y la industria. ¡Vale la pena esperar más avances en el futuro!