GPT-4V, este artefacto conocido como "mirar imágenes y hablar", ha sido criticado por su falta de comprensión de las interfaces gráficas. Es como una persona “ciega a la pantalla” que a menudo hace clic en los botones equivocados, lo cual es exasperante. Sin embargo, se espera que el modelo OmniParser lanzado por Microsoft resuelva completamente este problema. OmniParser es como un "traductor de pantalla", que convierte capturas de pantalla al lenguaje estructurado fácil de entender de GPT-4V, lo que hace que la "vista" de GPT-4V sea más nítida. El editor de Downcodes lo llevará a comprender en profundidad este modelo mágico, verá cómo ayuda al GPT-4V a superar el defecto de la "ceguera ocular" y la asombrosa tecnología detrás de él.
¿Todavía recuerdas el GPT-4V, un artefacto conocido como "mirar imágenes y hablar"? Puede comprender el contenido de las imágenes y realizar tareas basadas en ellas. ¡Es una bendición para los perezosos! debilidad: ¡su vista no es muy buena !
Imagine que le pide a GPT-4V que haga clic en un botón, pero hace clic por todas partes como una "pantalla ciega".
Hoy les presentaré un artefacto que puede hacer que GPT-4V se vea mejor: OmniParser. ¡Este es un nuevo modelo lanzado por Microsoft, cuyo objetivo es resolver el problema de la interacción automática de las interfaces gráficas de usuario (GUI).
¿Qué hace OmniParser?
En pocas palabras, OmniParser es un "traductor de pantalla" que puede analizar capturas de pantalla en un "lenguaje estructurado" que GPT-4V puede entender. OmniParser combina el modelo de detección de iconos interactivos optimizado, el modelo de descripción de iconos optimizado y la salida del módulo OCR.

Esta combinación produce una representación estructurada similar a DOM de la interfaz de usuario, así como capturas de pantalla que cubren los cuadros delimitadores de elementos potencialmente interactuables. Los investigadores primero crearon un conjunto de datos de detección de íconos interactivos utilizando páginas web populares y conjuntos de datos de descripción de íconos. Estos conjuntos de datos se utilizan para ajustar modelos especializados: un modelo de detección para analizar áreas interactuables en la pantalla y un modelo de descripción para extraer la semántica funcional de los elementos detectados.
Específicamente, OmniParser:
Identifique todos los íconos y botones interactivos en la pantalla, márquelos con cuadros y asigne a cada cuadro una identificación única.
Utilice texto para describir la función de cada icono, como "Configuración" y "Minimizar". Reconocer texto en la pantalla y extraerlo.
De esta manera, GPT-4V puede saber claramente qué hay en la pantalla y qué hace cada cosa. Simplemente dígale el ID del botón que desea hacer clic.
¿Qué tan maravilloso es OmniParser?
Los investigadores utilizaron varias pruebas para probar OmniParser y descubrieron que realmente puede hacer que GPT-4V sea "mejor".
En la prueba ScreenSpot, OmniParser mejoró enormemente la precisión de GPT-4V, superando incluso a algunos modelos especialmente entrenados para interfaces gráficas. Por ejemplo, en el conjunto de datos de ScreenSpot, OmniParser mejora la precisión en un 73 %, superando a los modelos que dependen del análisis HTML subyacente. En particular, la incorporación de la semántica local de los elementos de la interfaz de usuario resultó en una mejora significativa en la precisión de la predicción: los íconos de GPT-4V se etiquetaron correctamente del 70,5% al 93,8% cuando se usó la salida de OmniParser.
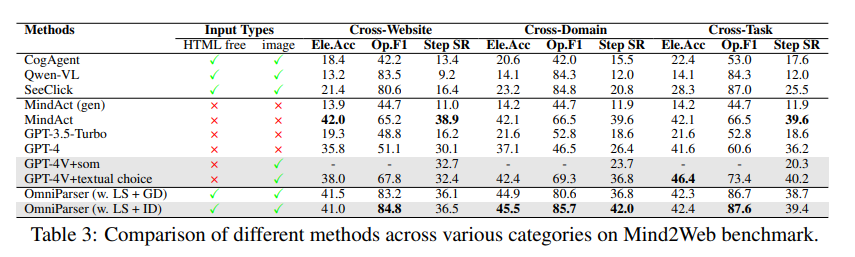
En la prueba Mind2Web, OmniParser mejoró el rendimiento de GPT-4V en tareas de navegación web y su precisión incluso superó a GPT-4V que utiliza asistencia de información HTML.
En la prueba AITW, OmniParser mejoró significativamente el rendimiento de GPT-4V en tareas de navegación de teléfonos móviles.
¿Cuáles son las deficiencias de OmniParser?
Aunque OmniParser es muy potente, también tiene algunos defectos menores, como por ejemplo:
Es fácil confundirse ante íconos o texto repetidos , y se necesitan descripciones más detalladas para distinguirlos.
A veces, el marco no se dibuja con la suficiente precisión , lo que hace que GPT-4V haga clic en la posición incorrecta.
En ocasiones, la interpretación de los iconos es errónea y requiere contexto para una descripción más precisa.
Sin embargo, los investigadores están trabajando arduamente para mejorar OmniParser y creen que será cada vez más poderoso y eventualmente se convertirá en el mejor socio de GPT-4V.
Experiencia modelo: https://huggingface.co/microsoft/OmniParser
Entrada en papel: https://arxiv.org/pdf/2408.00203
Introducción oficial: https://www.microsoft.com/en-us/research/articles/omniparser-for-pure-vision-based-gui-agent/
Destacar:
✨OmniParser puede ayudar a GPT-4V a comprender mejor el contenido de la pantalla y realizar tareas con mayor precisión.
OmniParser obtuvo buenos resultados en varias pruebas, lo que demuestra su eficacia.
?️OmniParser todavía tiene algunas áreas de mejora, pero hay esperanza en el futuro.
Considerándolo todo, OmniParser aporta mejoras revolucionarias a la interacción de GPT-4V con las interfaces gráficas de usuario. Aunque todavía existen algunas deficiencias, su potencial es enorme y vale la pena esperar con ansias su desarrollo futuro. El editor de Downcodes cree que con el avance continuo de la tecnología, OmniParser se convertirá en una estrella brillante en el campo de la inteligencia artificial.