En los últimos años, la inteligencia artificial ha logrado avances significativos en diversos campos, pero su capacidad de razonamiento matemático siempre ha sido un cuello de botella. Hoy, la aparición de un nuevo punto de referencia llamado FrontierMath proporciona un nuevo criterio para evaluar las capacidades matemáticas de la IA. Lleva las capacidades de razonamiento matemático de la IA a límites sin precedentes y plantea graves desafíos a los modelos de IA existentes. El editor de Downcodes lo llevará a comprender en profundidad FrontierMath y ver cómo subvierte nuestra comprensión de las capacidades matemáticas de la IA.
En el vasto universo de la inteligencia artificial, las matemáticas alguna vez fueron consideradas como el último bastión de la inteligencia artificial. Hoy ha surgido una nueva prueba de referencia llamada FrontierMath, que lleva las capacidades de razonamiento matemático de la IA a límites sin precedentes.
Epoch AI se ha unido a más de 60 de los mejores cerebros del mundo de las matemáticas para crear conjuntamente este campo de desafío de IA que puede denominarse Olimpíada de Matemáticas. Esta no es sólo una prueba técnica, sino también la prueba definitiva de la sabiduría matemática de la inteligencia artificial.
Imagine un laboratorio lleno de los mejores matemáticos del mundo, que han creado cientos de acertijos matemáticos que exceden la imaginación de la gente común. Estos problemas abarcan los campos matemáticos más avanzados, como la teoría de números, el análisis real, la geometría algebraica y la teoría de categorías, y son de una complejidad asombrosa. Incluso un genio de las matemáticas con una medalla de oro en la Olimpiada Internacional de Matemáticas necesita horas o incluso días para resolver un problema.
Sorprendentemente, los actuales modelos de IA de última generación tuvieron un rendimiento decepcionante en este punto de referencia: ningún modelo fue capaz de resolver más del 2% de los problemas. Este resultado fue como una llamada de atención y abofeteó a la IA.
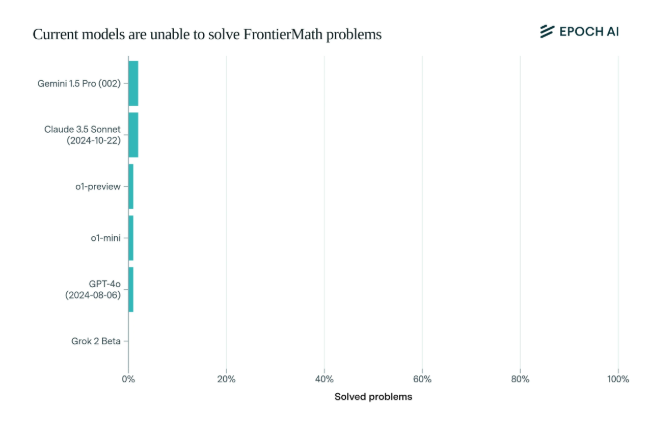
Lo que hace que FrontierMath sea único es su riguroso mecanismo de evaluación. La IA ha superado los puntos de referencia de pruebas matemáticas tradicionales, como MATH y GSM8K, y este nuevo punto de referencia utiliza preguntas nuevas e inéditas y un sistema de verificación automatizado para evitar eficazmente la contaminación de datos y probar verdaderamente las capacidades de razonamiento matemático de la IA.
Los modelos emblemáticos de las principales empresas de inteligencia artificial, como OpenAI, Anthropic y Google DeepMind, que han atraído mucha atención, fueron anulados colectivamente en esta prueba. Esto refleja una profunda filosofía técnica: para las computadoras, los problemas matemáticos aparentemente complejos pueden ser fáciles, pero las tareas que los humanos encuentran simples pueden dejar a la IA indefensa.
Como dijo Andrej Karpathy, esto confirma la paradoja de Moravec: la dificultad de las tareas inteligentes entre humanos y máquinas es a menudo contraintuitiva. Esta prueba de referencia no es sólo un examen riguroso de las capacidades de la IA, sino también un catalizador para la evolución de la IA a dimensiones superiores.
Para la comunidad matemática y los investigadores de IA, FrontierMath es como un Monte Everest invicto. No sólo pone a prueba conocimientos y habilidades, sino que también pone a prueba la perspicacia y el pensamiento creativo. En el futuro, quien pueda tomar la iniciativa para escalar este pico de inteligencia quedará registrado en la historia del desarrollo de la inteligencia artificial.
La aparición de la prueba de referencia FrontierMath no solo es una prueba severa del nivel de tecnología de IA existente, sino que también señala la dirección para el desarrollo futuro de la IA. Indica que la IA todavía tiene un largo camino por recorrer en el campo del razonamiento matemático. también estimula la investigación. Los investigadores continúan explorando e innovando para superar los obstáculos de las tecnologías existentes.