Hoy en día, con una interacción persona-computadora cada vez más frecuente, lograr una experiencia de conversación fluida y natural sigue siendo un desafío. El editor de Downcodes les presentará hoy una tecnología innovadora: Moshi, un sistema de diálogo de voz full-duplex desarrollado por Kyutai Labs. Su compromiso es crear una conversación entre humanos y máquinas más natural y fluida, haciendo que la comunicación con las máquinas sea tan fácil como hablar con amigos. La principal innovación de Moshi radica en su método exclusivo de generación de voz a voz y su tecnología avanzada que puede procesar múltiples transmisiones de audio simultáneamente. Echemos un vistazo más de cerca a los muchos aspectos destacados de Moshi.
En esta era digital, nuestras conversaciones con las máquinas se han convertido en parte de nuestra vida diaria. Sin embargo, estos diálogos a menudo carecen de naturalidad y fluidez, lo que los hace sentir un poco menos humanos. Sin embargo, eso puede estar a punto de cambiar. Moshi, un sistema de diálogo de voz full-duplex desarrollado por Kyutai Labs, está marcando el comienzo de una nueva era de diálogo entre humanos y computadoras más natural y fluido.
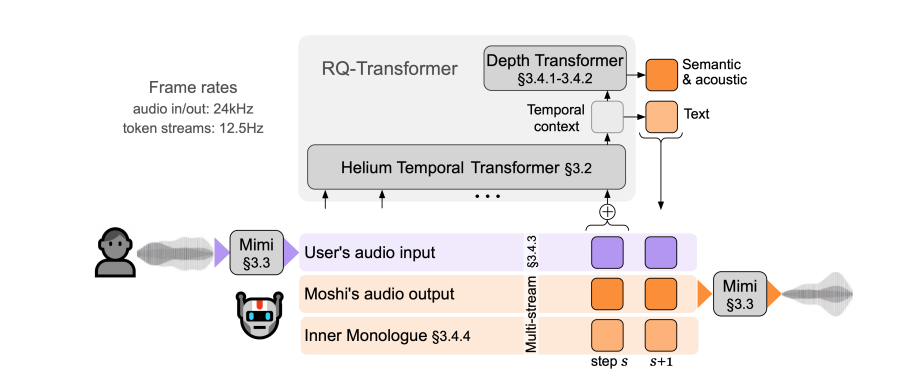
Moshi es un modelo de diálogo basado en voz y texto. Su principal innovación radica en tratar el diálogo como un proceso de generación de voz a voz. Este método resuelve inteligentemente muchos problemas existentes en los sistemas tradicionales de diálogo por voz, como retrasos, pérdida de información y limitaciones a la hora de tomar turnos. Moshi es único porque puede escuchar y hablar al mismo tiempo, como nosotros los humanos, y puede manejar superposiciones, interrupciones e interjecciones en las conversaciones con facilidad.
La poderosa funcionalidad de Moshi surge de tres tecnologías centrales. El primero es el modelo de lenguaje de texto Helium, que es el cerebro de Moshi. Tiene 7 mil millones de parámetros y poderosas capacidades de generación y comprensión del lenguaje mediante el aprendizaje masivo de datos en inglés. El siguiente es el Mimi Neural Audio Codec, que actúa como la boca y los oídos de Moshi, convirtiendo señales de voz en unidades discretas que el modelo puede entender. Finalmente, el modelo de lenguaje de audio de transmisión múltiple es la innovación de Moshi, que le permite procesar múltiples transmisiones de audio simultáneamente, lo que permite la comprensión simultánea de las voces de varios hablantes.
Moshi también tiene una función única de monólogo interior. Antes de generar voz, predice tokens de texto alineados en el tiempo y sincronizados con tokens de audio. Esto no solo mejora la calidad lingüística del habla generada, sino que también proporciona reconocimiento de voz en streaming y servicios de texto a voz, mejorando aún más sus capacidades conversacionales.
En varias pruebas de rendimiento, Moshi mostró un rendimiento excelente. Ya sea comprensión de texto, inteligibilidad del habla, calidad de audio o preguntas y respuestas habladas, Moshi ha alcanzado el nivel líder entre los modelos de voz y texto existentes. Esto significa que estamos un paso más cerca de lograr un diálogo entre humanos y computadoras verdaderamente natural y fluido.
Sin embargo, con el desarrollo de la tecnología de inteligencia artificial, los problemas de seguridad se han vuelto cada vez más prominentes. Vale la pena señalar que el equipo de desarrollo de Moshi tuvo esto en cuenta desde el principio. Toman varias medidas para garantizar la seguridad del sistema, incluido evitar la generación de contenido dañino, proteger la privacidad del usuario y garantizar una coherencia sólida. Moshi es capaz de identificar y negarse a responder preguntas inapropiadas manteniendo la coherencia de su propia voz y sin imitar la voz del usuario, lo que proporciona a los usuarios una seguridad adicional.
La llegada de Moshi no es sólo un gran avance en la tecnología, sino que también presagia una importante innovación en la forma de interacción entre humanos y computadoras. Nos muestra las infinitas posibilidades de los futuros sistemas de diálogo y nos permite ver la brillante perspectiva de un diálogo natural, fluido y humano entre humanos y máquinas. A medida que esta tecnología continúa desarrollándose y mejorando, es posible que pronto podamos lograr una comunicación verdaderamente libre de barreras y de alta calidad con las máquinas, permitiendo que escenas de películas de ciencia ficción se reproduzcan en la vida real.
Dirección del modelo: https://huggingface.co/kyutai/moshiko-pytorch-bf16
Dirección del artículo: https://kyutai.org/Moshi.pdf
La aparición de Moshi señala el camino para la futura interacción entre humanos y computadoras, y su experiencia de conversación fluida y natural es emocionante. Se cree que con el avance continuo de la tecnología, la comunicación entre humanos y máquinas será cada vez más conveniente y natural, logrando eventualmente una comunicación verdaderamente sin barreras. ¡Esperemos y veremos!