Informes del editor de Downcodes: Equipos de investigación de la Universidad Jiao Tong de Shanghai, la Universidad de Cambridge y el Instituto de Investigación de Automóviles Geely lanzaron recientemente un nuevo sistema de conversión de texto a voz (TTS) llamado F5-TTS. El sistema utiliza un método libre de autorregresión, combinado con adaptación de flujo y transformador de difusión (DiT), que simplifica efectivamente el complejo proceso del modelo TTS tradicional y logra avances significativos tanto en la calidad de la síntesis como en la velocidad de inferencia. En comparación con los modelos TTS tradicionales, F5-TTS tiene un buen rendimiento en términos de velocidad de procesamiento y robustez, aportando nuevas posibilidades a la tecnología de síntesis de voz.
Recientemente, un equipo de investigación de la Universidad Jiao Tong de Shanghai, la Universidad de Cambridge y el Instituto de Investigación del Automóvil Geely lanzaron un nuevo sistema de conversión de texto a voz (TTS) llamado F5-TTS. Lo especial de este sistema es que utiliza un método libre de autorregresión que combina la adaptación de flujo con un transformador de difusión (DiT), simplificando con éxito los pasos complejos del modelo TTS tradicional.

Como todos sabemos, los modelos TTS tradicionales a menudo requieren un modelado de duración complejo, alineación de fonemas y codificación de texto especializada, lo que aumenta la complejidad del proceso de síntesis. En particular, los modelos anteriores como E2TTS a menudo enfrentan problemas como una convergencia lenta y una alineación inexacta de texto y voz, lo que dificulta su aplicación eficiente en escenarios del mundo real. La aparición de F5-TTS es precisamente para resolver estos desafíos.
El principio de funcionamiento de F5-TTS es simple. Primero, el texto de entrada se procesa a través de la arquitectura ConvNeXt para facilitar su alineación con la voz. Luego, la secuencia de caracteres rellenados se introduce en el modelo junto con una versión ruidosa del discurso de entrada.
El entrenamiento del sistema se basa en el transformador de difusión (DiT), que asigna de manera efectiva una distribución inicial simple a la distribución de datos mediante la coincidencia de flujo. Además, F5-TTS también introduce de manera innovadora la estrategia Sway Sampling durante la inferencia, que puede priorizar los primeros pasos del flujo en la fase de inferencia, mejorando así la alineación entre el habla generada y el texto de entrada.
Según los resultados de la investigación, F5-TTS supera a muchos sistemas TTS actuales tanto en calidad de síntesis como en velocidad de inferencia. En el conjunto de datos LibriSpeech-PC, el modelo logró una tasa de error de palabras (WER) de 2,42 y un factor de tiempo real (RTF) de 0,15 en el momento de la inferencia, lo que fue significativamente mejor que el modelo de difusión anterior E2TTS, que tuvo un mejor rendimiento en el procesamiento. velocidad y hay deficiencias en la robustez.
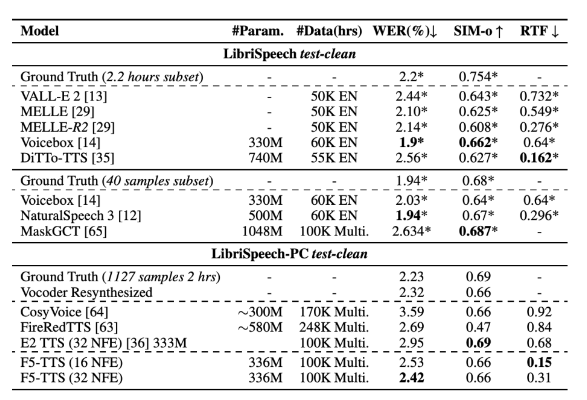
Al mismo tiempo, la estrategia Sway Sampling mejora significativamente la naturalidad y la comprensibilidad del habla generada, lo que permite que el modelo logre una generación fluida y expresiva sin entrenamiento.
F5-TTS mejora la solidez de la alineación y la calidad de la síntesis al simplificar el proceso y eliminar la necesidad de predicción de duración, alineación de fonemas y codificación de texto explícita. Además, los investigadores también enfatizaron las consideraciones éticas y propusieron la necesidad de establecer sistemas de detección y marcas de agua para evitar que se abuse del modelo.
Entrada del proyecto: https://github.com/SWivid/F5-TTS
Destacar:
F5-TTS es un nuevo tipo de sistema de conversión de texto a voz autorregresivo que simplifica la complejidad del modelo TTS tradicional.
El sistema utiliza la arquitectura ConvNeXt y DiT para mejorar la alineación del texto y la voz y mejorar significativamente la calidad de la síntesis.
? Los investigadores enfatizaron la necesidad de prestar atención a las cuestiones éticas y sugirieron la introducción de marcas de agua y mecanismos de detección para prevenir posibles abusos.
La aparición del sistema F5-TTS ha supuesto nuevos avances en la tecnología de conversión de texto a voz, y se espera que su rendimiento eficiente y sus procesos simplificados se utilicen ampliamente en muchos campos. Sin embargo, las cuestiones éticas también requieren atención, y la investigación posterior debería dedicarse a establecer un mecanismo regulatorio sólido para garantizar el desarrollo responsable de la tecnología.