El editor de Downcodes se enteró de que científicos de Meta, la Universidad de California, Berkeley y la Universidad de Nueva York desarrollaron conjuntamente una nueva tecnología llamada "Optimización de preferencias de pensamiento" (TPO), con el objetivo de mejorar el rendimiento de modelos de lenguaje grandes (LLM). Esta tecnología mejora la capacidad de "pensamiento" de la IA al permitir que el modelo genere una serie de pasos de pensamiento antes de responder una pregunta y utilizar el modelo de evaluación para optimizar la calidad de la respuesta final, lo que le permite desempeñarse mejor en diversas tareas. A diferencia de la tecnología tradicional de "pensamiento en cadena", TPO tiene una gama más amplia de aplicaciones, mostrando especialmente ventajas significativas en escritura creativa, razonamiento de sentido común, etc.
Recientemente, científicos de Meta, la Universidad de California, Berkeley y la Universidad de Nueva York colaboraron para desarrollar una nueva tecnología llamada Optimización de Preferencias de Pensamiento (TPO). El objetivo de esta tecnología es mejorar el rendimiento de los modelos de lenguaje grandes (LLM) al realizar diversas tareas, permitiendo a la IA considerar sus respuestas con más atención antes de responder.
Los investigadores dicen que el pensamiento debería tener una amplia utilidad. Por ejemplo, en tareas de escritura creativa, la IA puede utilizar procesos de pensamiento internos para planificar la estructura general y el desarrollo del personaje. Este método es significativamente diferente de la tecnología de indicación de "Cadena de Pensamiento" (CoT) anterior. Este último se utiliza principalmente en tareas matemáticas y lógicas, mientras que TPO tiene una gama más amplia de aplicaciones. Los investigadores mencionaron el nuevo modelo o1 de OpenAI y creen que el proceso de pensamiento también es útil para una gama más amplia de tareas.
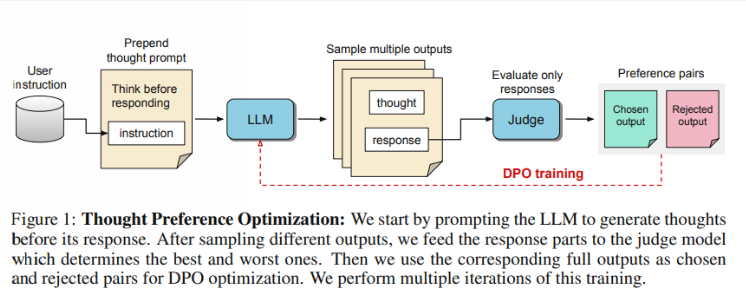
Entonces, ¿cómo funciona TPO? Primero, el modelo genera una serie de pasos de pensamiento antes de responder una pregunta. A continuación, crea múltiples resultados, que luego son evaluados mediante un modelo de evaluación solo en función de la respuesta final, no de los pasos de pensamiento en sí. Finalmente, el modelo se entrena mediante la optimización de preferencias de estos resultados de evaluación. Los investigadores esperan que se pueda mejorar la calidad de las respuestas mejorando el proceso de pensamiento, de modo que el modelo pueda adquirir capacidades de razonamiento más efectivas en el aprendizaje implícito.
En las pruebas, el modelo Llama38B que utiliza TPO obtuvo mejores resultados en una instrucción general siguiendo un punto de referencia que una versión sin inferencia explícita. En los benchmarks AlpacaEval y Arena-Hard, las tasas de ganancia de TPO alcanzaron el 52,5% y el 37,3% respectivamente. Aún más emocionante es que TPO también está logrando avances en áreas que normalmente no requieren un pensamiento explícito, como el sentido común, el marketing y la salud.
Sin embargo, el equipo de investigación observó que la configuración actual no es adecuada para problemas matemáticos, ya que TPO en realidad funciona peor que el modelo base en estas tareas. Esto sugiere que puede ser necesario un enfoque diferente para tareas altamente especializadas. Las investigaciones futuras pueden centrarse en aspectos como el control de la duración de los procesos de pensamiento y el impacto del pensamiento en modelos más amplios.
Destacar:
El equipo de investigación lanzó la "Optimización de preferencias de pensamiento" (TPO), cuyo objetivo es mejorar la capacidad de pensamiento de la IA en la ejecución de tareas.
? TPO utiliza modelos de evaluación para optimizar la calidad de las respuestas al permitir que el modelo genere pasos de pensamiento antes de responder.
Las pruebas han demostrado que las OPC se desempeñan bien en áreas como conocimiento general y marketing, pero obtienen malos resultados en tareas de matemáticas.
Con todo, la tecnología TPO proporciona una nueva dirección para la mejora de modelos de lenguaje grandes, y vale la pena esperar su potencial para mejorar las capacidades de pensamiento de la IA. Sin embargo, esta tecnología también tiene limitaciones y futuras investigaciones deben mejorar y ampliar aún más su alcance de aplicación. El editor de Downcodes seguirá prestando atención a los últimos desarrollos en este campo y brindará informes más interesantes a los lectores.