OpenAI ha lanzado un nuevo y llamativo modelo gpt-4o-audio-preview, que ha logrado avances significativos en el campo de la generación y análisis del habla, brindando a los usuarios una experiencia de interacción de voz más natural e inteligente. El editor de Downcodes lo llevará a comprender en profundidad las funciones principales, los escenarios de aplicación y las estrategias de precios de este modelo, y analizará su impacto potencial en diversas industrias.
OpenAI una vez más lidera la tendencia de la tecnología de inteligencia artificial y lanza un nuevo modelo de vista previa de audio gpt-4o. Este modelo no sólo demuestra capacidades asombrosas en la generación y análisis del habla, sino que también abre nuevas posibilidades para la interacción persona-computadora. Echemos un vistazo más de cerca a las características de este modelo innovador y sus posibles aplicaciones.
Las funciones principales de gpt-4o-audio-preview incluyen tres aspectos principales: primero, puede generar respuestas de voz naturales y fluidas basadas en texto, brindando un sólido soporte para aplicaciones como asistentes de voz y servicio al cliente virtual. En segundo lugar, el modelo tiene la capacidad de analizar la emoción, la entonación y el tono de la entrada de audio, lo que tiene amplias perspectivas de aplicación en los campos de la informática afectiva y el análisis de la experiencia del usuario. Finalmente, admite la interacción de voz a voz, donde el audio se puede utilizar como entrada y salida, sentando las bases para una gama completa de sistemas de interacción de voz.
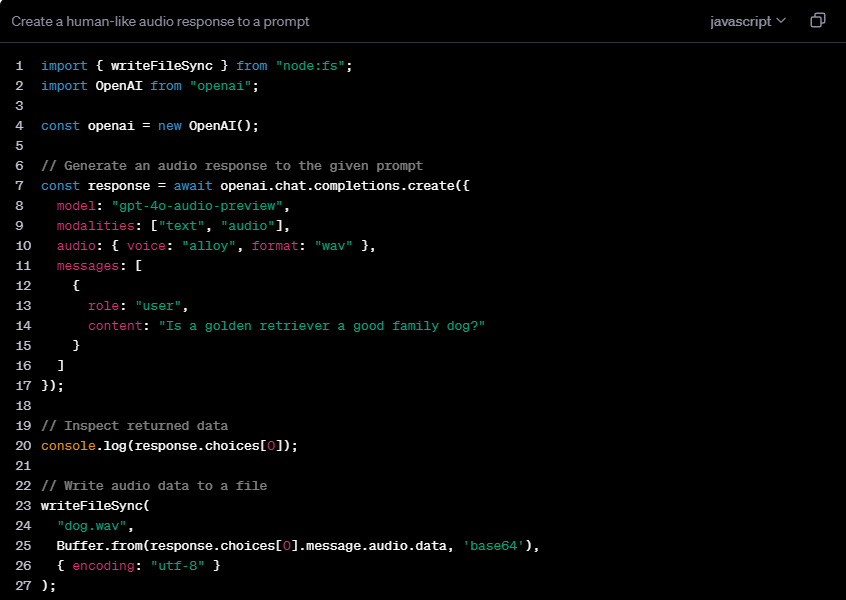
En comparación con la API en tiempo real existente de OpenAI, gpt-4o-audio-preview se centra más en los detalles del procesamiento de voz. Destaca en la generación del habla, el análisis de sentimientos y la interacción del habla, con un enfoque particular en el procesamiento de características sutiles como la entonación y la emoción. Por el contrario, Realtime API se centra más en el procesamiento de datos en tiempo real y es adecuada para escenarios que requieren retroalimentación inmediata, como conversión de voz a texto en tiempo real o traducción en tiempo real y otras aplicaciones continuamente interactivas.
La flexibilidad de gpt-4o-audio-preview se refleja en su soporte para múltiples combinaciones de modos. Los usuarios pueden seleccionar la entrada de texto para generar salida de texto y audio, o utilizar la entrada de audio para obtener salida de texto y voz. Además, también admite la conversión de audio a texto y modos de entrada mixtos, lo que brinda a los desarrolladores opciones completas.
En términos de precios, OpenAI adopta un modelo de facturación basado en tokens. El precio de la entrada de texto es relativamente bajo, alrededor de 5 dólares por millón de tokens. La producción de texto es ligeramente superior, alrededor de 15 dólares por millón de tokens. El costo del procesamiento de audio es relativamente alto: la entrada cuesta $100 por millón de tokens (aproximadamente $0,06 por minuto), mientras que la salida de audio alcanza los $200 por millón de tokens (aproximadamente $0,24 por minuto). Esta estrategia de precios refleja la complejidad y los requisitos de recursos informáticos del procesamiento de audio.
Sin duda, el lanzamiento de gpt-4o-audio-preview tendrá un impacto transformador en múltiples industrias. En el campo del servicio al cliente, puede proporcionar una experiencia de interacción de voz más natural y emocional. En el sector educativo, esta tecnología se puede utilizar para desarrollar asistentes inteligentes de aprendizaje de idiomas para ayudar a los estudiantes a mejorar su pronunciación y entonación. En la industria del entretenimiento, se espera que impulse una síntesis de voz más realista y una interacción de personajes virtuales. Además, en términos de tecnología de asistencia, gpt-4o-audio-preview puede proporcionar servicios de conversión de voz a texto más precisos para personas con discapacidad auditiva o descripciones de voz más ricas para personas con discapacidad visual.
Detalles: https://platform.openai.com/docs/guides/audio/quickstart
Con todo, la aparición del modelo gpt-4o-audio-preview marca una nueva etapa en la tecnología de inteligencia artificial de voz. Sus poderosas funciones y amplias perspectivas de aplicación traerán cambios revolucionarios a los futuros métodos de interacción persona-computadora. El editor de Downcodes espera ver más aplicaciones innovadoras basadas en este modelo.