El editor de Downcodes se enteró de que la Academia Alibaba Damo y la Universidad Renmin de China abrieron conjuntamente un modelo de procesamiento de documentos llamado mPLUG-DocOwl1.5. El modelo puede comprender el contenido del documento sin reconocimiento OCR y funciona bien en múltiples pruebas comparativas. Su núcleo radica en el método de "aprendizaje de estructura unificada", que mejora la comprensión estructural del modelo de lenguaje grande multimodal (MLLM) de imágenes de texto enriquecido. . El modelo ha publicado código, modelos y conjuntos de datos en GitHub, lo que proporciona recursos valiosos para la investigación en campos relacionados.
La Academia Alibaba Damo y la Universidad Renmin de China abrieron recientemente de forma conjunta un modelo de procesamiento de documentos llamado mPLUG-DocOwl1.5. Este modelo se centra en la comprensión del contenido del documento sin reconocimiento OCR y ha logrado resultados en múltiples pruebas comparativas de comprensión visual de documentos.
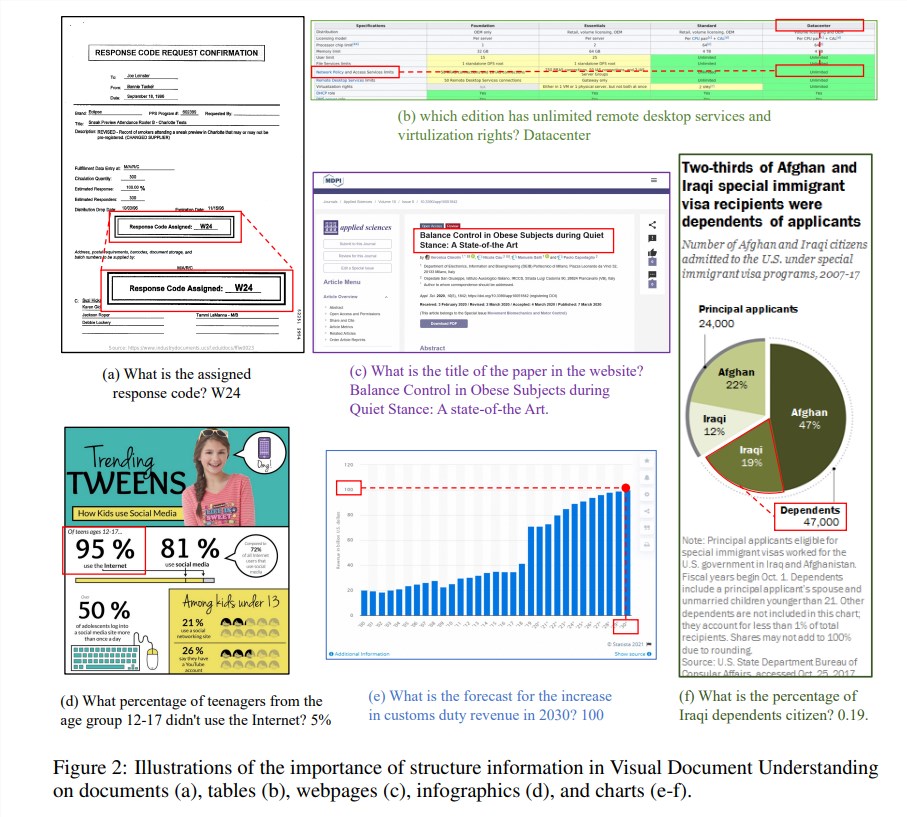
La información estructural es crucial para comprender la semántica de imágenes ricas en texto, como documentos, tablas y gráficos. Aunque los modelos multimodales de lenguaje grande (MLLM) existentes tienen capacidades de reconocimiento de texto, carecen de la capacidad de comprender la estructura general de las imágenes de documentos de texto enriquecido. Para resolver este problema, mPLUG-DocOwl1.5 enfatiza la importancia de la información estructural en la comprensión de documentos visuales y propone un "aprendizaje de estructura unificada" para mejorar el rendimiento de MLLM.
El "aprendizaje de estructura unificada" del modelo cubre cinco áreas: documentos, páginas web, tablas, gráficos e imágenes naturales, incluidas tareas de análisis con reconocimiento de estructura y tareas de posicionamiento de texto de granularidad múltiple. Para codificar mejor la información estructural, los investigadores diseñaron un módulo de conversión de imagen a texto simple y efectivo, H-Reducer, que no solo preserva la información del diseño, sino que también reduce la longitud de las características visuales al fusionar parches de imágenes adyacentes horizontalmente mediante convolución. modelos de lenguaje grandes para comprender imágenes de alta resolución de manera más eficiente.
Además, para respaldar el aprendizaje de estructuras, el equipo de investigación creó DocStruct4M, un conjunto de capacitación integral que contiene 4 millones de muestras basadas en conjuntos de datos disponibles públicamente, que contiene secuencias de texto con reconocimiento de estructuras y pares de cuadros delimitadores de texto de granularidad múltiple. Para estimular aún más las capacidades de razonamiento de MLLM en el campo de los documentos, también construyeron un conjunto de datos de ajuste de razonamiento DocReason25K que contiene 25.000 muestras de alta calidad.
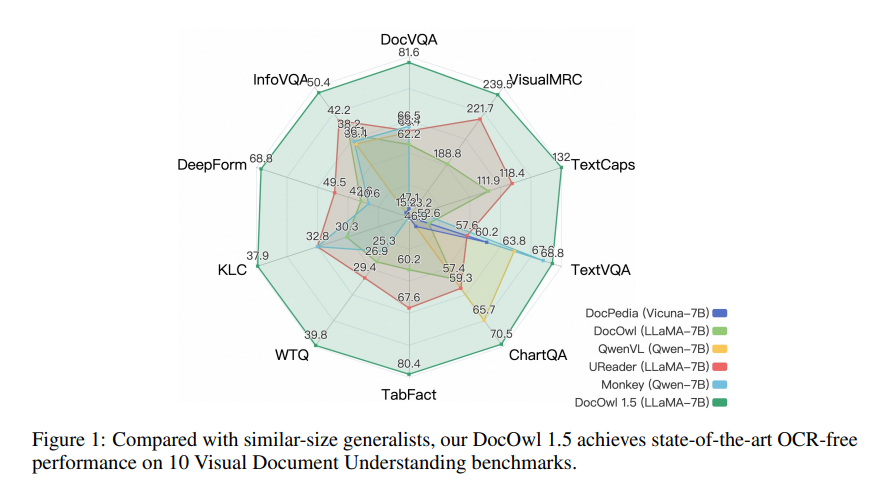
mPLUG-DocOwl1.5 adopta un marco de capacitación de dos etapas, que primero realiza un aprendizaje de estructura unificada y luego realiza un ajuste fino de múltiples tareas en múltiples tareas posteriores. A través de este método de capacitación, mPLUG-DocOwl1.5 logró un rendimiento de vanguardia en 10 puntos de referencia de comprensión de documentos visuales, mejorando el rendimiento SOTA de 7B LLM en más de 10 puntos porcentuales en 5 puntos de referencia.
Actualmente, el código, el modelo y el conjunto de datos de mPLUG-DocOwl1.5 se han publicado públicamente en GitHub.
Dirección del proyecto: https://github.com/X-PLUG/mPLUG-DocOwl/tree/main/DocOwl1.5
Dirección del artículo: https://arxiv.org/pdf/2403.12895
El código abierto de mPLUG-DocOwl1.5 ofrece nuevas posibilidades para la investigación y aplicación en el campo de la comprensión visual de documentos. Su rendimiento eficiente y sus métodos de acceso convenientes merecen la atención y el uso de los desarrolladores. Se espera que este modelo pueda utilizarse en escenarios más prácticos en el futuro.