¡El editor de Downcodes le llevará a conocer los últimos resultados de las investigaciones del Instituto Federal Suizo de Tecnología en Lausana (EPFL)! Este estudio proporciona una comparación en profundidad de dos métodos principales de entrenamiento adaptativo para modelos de lenguaje grandes (LLM): aprendizaje contextual (ICL) y ajuste fino de instrucciones (IFT), y utiliza el punto de referencia MT-Bench para evaluar la capacidad del modelo para seguir instrucciones. Los resultados de la investigación muestran que los dos métodos tienen sus propios méritos en diferentes escenarios, proporcionando una referencia valiosa para la selección de métodos de formación LLM.
Un estudio reciente de la Ecole Polytechnique Fédérale de Lausanne (EPFL) en Suiza comparó dos métodos convencionales de entrenamiento adaptativo para modelos de lenguaje grandes (LLM): aprendizaje contextual (ICL) y ajuste de instrucción (IFT). Los investigadores utilizaron el punto de referencia MT-Bench para evaluar la capacidad de un modelo para seguir instrucciones y descubrieron que ambos métodos funcionaban mejor y peor en determinadas circunstancias.
Las investigaciones han descubierto que cuando el número de muestras de entrenamiento disponibles es pequeño (por ejemplo, no más de 50), los efectos de ICL e IFT son muy similares. Esto sugiere que ICL puede ser una alternativa a IFT cuando los datos son limitados.
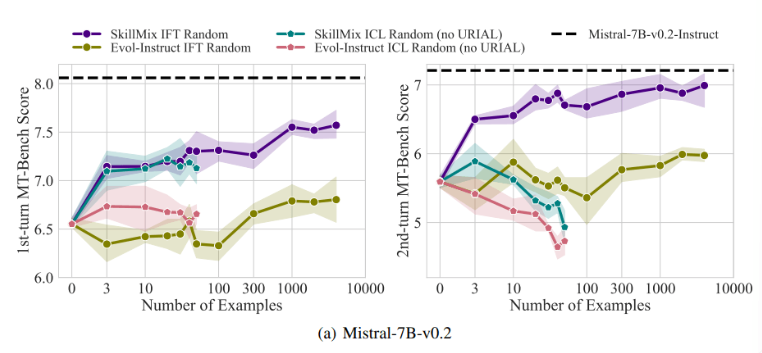
Sin embargo, a medida que aumenta la complejidad de la tarea, como en escenarios de diálogo de múltiples turnos, las ventajas de IFT se vuelven evidentes. Los investigadores creen que el modelo ICL tiende a sobreajustarse al estilo de una sola muestra, lo que resulta en un rendimiento deficiente al manejar conversaciones complejas, o incluso peor que el modelo base.
El estudio también examinó el método URIAL, que utiliza sólo tres muestras e instrucciones para seguir reglas para entrenar un modelo de lenguaje base. Si bien la URIAL ha logrado ciertos resultados, aún existe una brecha respecto al modelo entrenado por el IFT. Los investigadores de la EPFL mejoraron el rendimiento de URIAL mejorando la estrategia de selección de muestras, acercándolo a los modelos de ajuste fino. Esto resalta la importancia de datos de entrenamiento de alta calidad para ICL, IFT y entrenamiento de modelos básicos.
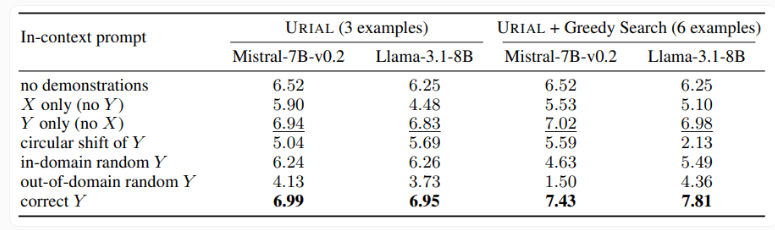
Además, el estudio también encontró que los parámetros de decodificación tienen un impacto significativo en el rendimiento del modelo. Estos parámetros determinan cómo el modelo genera texto y son críticos tanto para el LLM básico como para los modelos entrenados con URIAL.
Los investigadores señalan que incluso el modelo base puede seguir instrucciones hasta cierto punto si se proporcionan los parámetros de decodificación adecuados.
La importancia de este estudio es que revela que el aprendizaje contextual puede ajustar de manera rápida y eficiente los modelos de lenguaje, especialmente cuando las muestras de entrenamiento son limitadas. Pero para tareas complejas como conversaciones de varios turnos, el ajuste de comandos sigue siendo una mejor opción.
A medida que aumenta el tamaño del conjunto de datos, el rendimiento de IFT seguirá mejorando, mientras que el rendimiento de ICL se estabilizará después de alcanzar un cierto número de muestras. Los investigadores enfatizan que la elección entre ICL e IFT depende de una variedad de factores, como los recursos disponibles, el volumen de datos y los requisitos de aplicación específicos. Cualquiera que sea el método que elijas, los datos de entrenamiento de alta calidad son cruciales.
En definitiva, este estudio de la EPFL proporciona nuevos conocimientos sobre la selección de métodos de formación para modelos lingüísticos de gran tamaño y señala el camino para futuras direcciones de investigación. Elegir ICL o IFT requiere sopesar los pros y los contras en función de la situación específica, y los datos de alta calidad son siempre la clave. Esperamos que esta investigación pueda ayudar a todos a comprender y aplicar mejor modelos de lenguaje grandes.