¡El editor de Downcodes lo llevará a conocer Emu3, el último modelo mundial multimodal lanzado por el Instituto de Investigación Zhiyuan! Emu3 se basa en su capacidad única de "predicción del próximo token" para lograr capacidades innovadoras de comprensión y generación en tres modalidades: texto, imagen y video. No solo puede generar imágenes de alta calidad y videos fluidos y naturales, sino que también realiza una comprensión precisa de las imágenes y una predicción de videos. Su rendimiento supera al de muchos modelos de código abierto conocidos. La naturaleza de código abierto de Emu3 también inyecta nueva vitalidad al desarrollo de la IA multimodal. Exploremos la innovación tecnológica y el potencial futuro que hay detrás.
El Instituto de Investigación Zhiyuan lanzó oficialmente su modelo mundial multimodal Emu3 de nueva generación. Lo más destacado de este modelo es que puede predecir el siguiente token en tres modos diferentes: texto, imagen y video.

En términos de generación de imágenes, Emu3 puede generar imágenes de alta calidad basadas en la predicción de tokens visuales. Esto significa que los usuarios pueden esperar resoluciones flexibles y una variedad de estilos.

En términos de generación de video, Emu3 funciona de una manera completamente nueva. A diferencia de otros modelos que generan videos a través de ruido, Emu3 genera videos directamente mediante predicción secuencial. Este avance tecnológico hace que la generación de videos sea más fluida y natural.

En tareas como generación de imágenes, generación de videos y comprensión del lenguaje visual, el rendimiento de Emu3 supera al de muchos modelos de código abierto conocidos, como SDXL, LLaVA y OpenSora. Detrás hay un potente tokenizador visual que puede convertir vídeos e imágenes en tokens discretos. Este diseño proporciona nuevas ideas para el procesamiento unificado de texto, imágenes y vídeos.
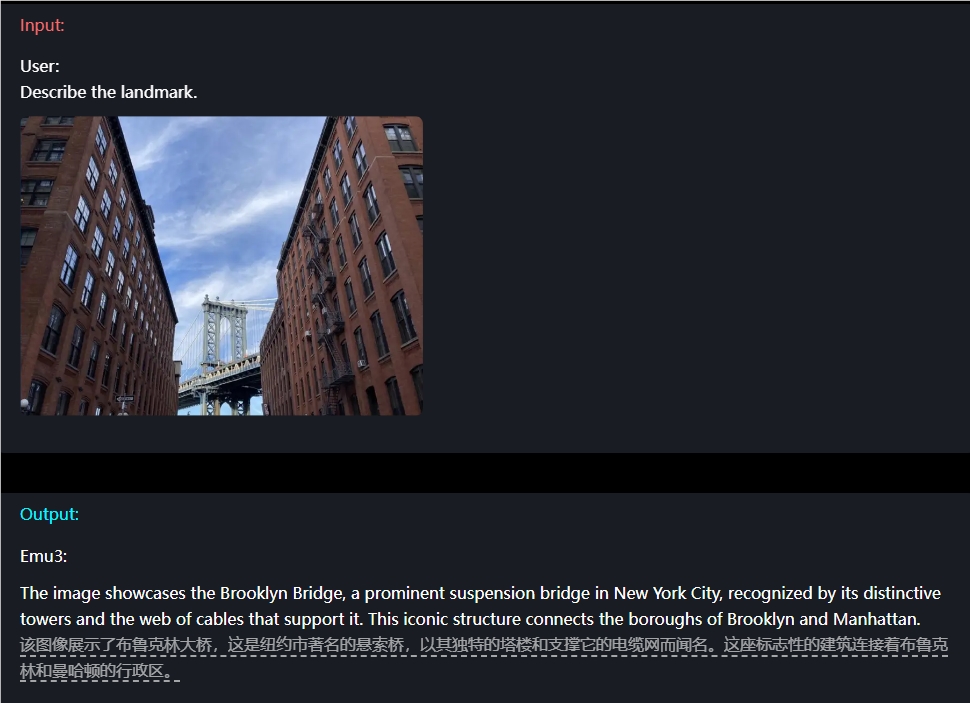
Por ejemplo, en términos de comprensión de imágenes, los usuarios solo necesitan ingresar una pregunta y Emu3 puede describir con precisión el contenido de la imagen.
Emu3 también tiene capacidades de predicción de video. Cuando se le presenta un vídeo, Emu3 puede predecir lo que sucederá a continuación en función del contenido existente. Esto le permite demostrar sólidas capacidades en la simulación de entornos y comportamientos humanos y animales, lo que permite a los usuarios experimentar una experiencia interactiva más realista.

Además, la flexibilidad de diseño de Emu3 es refrescante. Se puede optimizar directamente con las preferencias humanas para que el contenido generado esté más acorde con las expectativas del usuario. Además, Emu3, como modelo de código abierto, ha generado acalorados debates en la comunidad técnica. Mucha gente cree que este logro cambiará por completo el patrón de desarrollo de la IA multimodal.
URL del proyecto: https://emu.baai.ac.cn/about
Documento: https://arxiv.org/pdf/2409.18869
Destacar:
Emu3 logra la comprensión y generación multimodal de texto, imágenes y videos mediante la predicción del siguiente token.
En múltiples tareas, el rendimiento de Emu3 superó al de muchos modelos de código abierto conocidos, lo que demuestra sus poderosas capacidades.
El diseño flexible y las características de código abierto de Emu3 brindan a los desarrolladores nuevas oportunidades y se espera que promuevan la innovación y el desarrollo de la IA multimodal.
La aparición de Emu3 marca un nuevo hito en el campo de la IA multimodal. Su potente rendimiento, diseño flexible y características de código abierto sin duda tendrán un profundo impacto en el desarrollo futuro de la IA. ¡Esperamos que Emu3 se utilice en más campos y brinde más comodidades y sorpresas a la humanidad!