El editor de Downcodes se enteró de que el Instituto de Investigación de Inteligencia Artificial Zhiyuan de Beijing ha unido fuerzas con varias universidades para lanzar un gran modelo para la comprensión de videos ultralargos llamado Video-XL. El modelo funciona bien en el procesamiento de vídeos largos de más de diez minutos, logra posiciones de liderazgo en múltiples puntos de referencia y demuestra sólidas capacidades de generalización y eficiencia de procesamiento. Video-XL utiliza modelos de lenguaje para comprimir secuencias visuales largas y logra casi un 95% de precisión en tareas como "encontrar una aguja en un pajar". Solo necesita una tarjeta gráfica con 80 G de memoria de video para procesar 2048 cuadros de entrada. El código abierto de este modelo promoverá la cooperación y el desarrollo de la comunidad global de investigación de comprensión de videos multimodales.
El Instituto de Investigación de Inteligencia Artificial Zhiyuan de Beijing ha unido fuerzas con universidades como la Universidad Jiao Tong de Shanghai, la Universidad Renmin de China, la Universidad de Pekín y la Universidad de Correos y Telecomunicaciones de Beijing para lanzar un gran modelo de comprensión de video ultralargo llamado Video-XL. Este modelo es una demostración importante de las capacidades centrales de los grandes modelos multimodales y un paso clave hacia la inteligencia artificial general (AGI). En comparación con los modelos grandes multimodales existentes, Video-XL muestra un mejor rendimiento y eficiencia al procesar vídeos largos de más de 10 minutos.

Video-XL utiliza las capacidades nativas de los modelos de lenguaje (LLM) para comprimir secuencias visuales largas, conserva la capacidad de comprender videos cortos y muestra excelentes capacidades de generalización en la comprensión de videos largos. Este modelo ocupa el primer lugar en múltiples tareas en múltiples puntos de referencia de comprensión de videos largos convencionales. Video-XL logra un buen equilibrio entre eficiencia y rendimiento. Solo necesita una tarjeta gráfica con memoria de video de 80G para procesar una entrada de 2048 cuadros, muestrear videos de una hora y lograr casi el 95% en la tarea de "aguja en el pajar" de video. % exactitud.
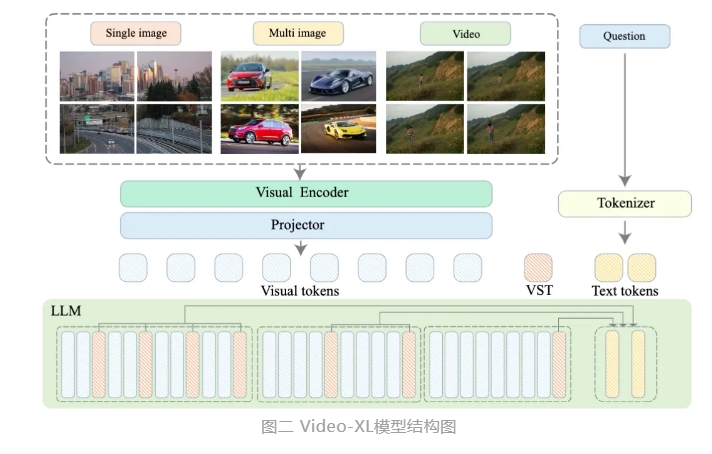
Se espera que Video-XL muestre un amplio valor de aplicación en escenarios de aplicaciones como resumen de películas, detección de anomalías de video y detección de ubicación de anuncios, y se convierta en un poderoso asistente para la comprensión de videos largos. El lanzamiento de este modelo marca un paso importante en la eficiencia y precisión de la tecnología de comprensión de videos largos y proporciona un sólido soporte técnico para el procesamiento y análisis automatizados de contenido de videos largos en el futuro.
Actualmente, el código modelo de Video-XL ha sido de código abierto para promover la cooperación y el intercambio de tecnología en la comunidad global de investigación de comprensión de video multimodal.
Título del artículo: Video-XL: modelo de lenguaje de visión extralarga para la comprensión de vídeos a escala horaria
Enlace del artículo: https://arxiv.org/abs/2409.14485
Enlace del modelo: https://huggingface.co/sy1998/Video_XL
Enlace del proyecto: https://github.com/VectorSpaceLab/Video-XL
El código abierto de Video-XL brinda nuevas posibilidades para la investigación y aplicación en el campo de la comprensión de videos largos. Su eficiencia y precisión promoverán un mayor desarrollo de tecnologías relacionadas y brindarán soporte técnico para más escenarios de aplicación en el futuro. Esperamos ver más aplicaciones innovadoras basadas en Video-XL en el futuro.