El editor de Downcodes le presentará una investigación más reciente de la Universidad Técnica de Darmstadt en Alemania. Este estudio utilizó el problema de Bongard como herramienta de prueba para evaluar el rendimiento del actual modelo de imagen de IA de última generación en tareas simples de razonamiento visual. Los resultados de la investigación son sorprendentes, incluso la precisión de los mejores modelos multimodales como GPT-4o es mucho menor de lo esperado, lo que provoca una profunda reflexión sobre los estándares de evaluación de la capacidad visual de la IA existentes.
La última investigación de la Universidad Técnica de Darmstadt (Alemania) revela un fenómeno que invita a la reflexión: incluso los modelos de imágenes de IA más avanzados pueden cometer errores importantes cuando se enfrentan a tareas simples de razonamiento visual. Los resultados de esta investigación plantean nuevas ideas sobre los estándares de evaluación de la capacidad visual de la IA.
El equipo de investigación utilizó el problema de Bongard diseñado por el científico ruso Michail Bongard como herramienta de prueba. Este tipo de rompecabezas visual consta de 12 imágenes simples divididas en dos grupos y requiere identificar las reglas que distinguen a los dos grupos. Esta tarea de razonamiento abstracto no es difícil para la mayoría de las personas, pero el rendimiento del modelo de IA fue sorprendente.
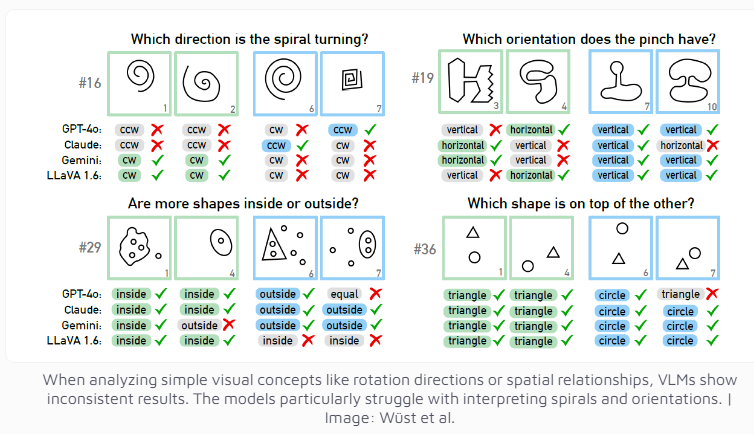
Incluso el modelo multimodal GPT-4o, actualmente considerado el más avanzado, resolvió con éxito sólo 21 de 100 acertijos visuales. El rendimiento de otros modelos de IA conocidos como Claude, Gemini y LLaVA es aún menos satisfactorio. Estos modelos muestran dificultades significativas para identificar conceptos visuales básicos como líneas verticales y horizontales, o para juzgar la dirección de una espiral.
Los investigadores descubrieron que incluso cuando se ofrecían múltiples opciones, el rendimiento del modelo de IA mejoraba sólo ligeramente. Sólo bajo estrictas restricciones en el número de respuestas posibles, GPT-4 y Claude mejoraron sus tasas de éxito a 68 y 69 acertijos respectivamente. Mediante un análisis en profundidad de cuatro casos específicos, el equipo de investigación descubrió que los sistemas de IA a veces tienen problemas en el nivel básico de percepción visual antes de llegar a la etapa de pensamiento y razonamiento, pero las razones específicas aún son difíciles de determinar.
Esta investigación también suscita una reflexión sobre los criterios de evaluación de los sistemas de IA. El equipo de investigación señaló: ¿Por qué los modelos de lenguaje visual funcionan bien en los puntos de referencia establecidos pero tienen problemas con el aparentemente simple problema de Bongard? ¿Qué tan significativos son estos puntos de referencia para evaluar las capacidades de razonamiento del mundo real? Es posible que sea necesario rediseñarlo para medir con mayor precisión las capacidades de razonamiento visual de la IA.
Esta investigación no sólo demuestra las limitaciones de la tecnología de IA actual, sino que también señala el camino para el desarrollo futuro de las capacidades visuales de la IA. Nos recuerda que, si bien celebramos el rápido progreso de la IA, también debemos darnos cuenta claramente de que todavía hay margen de mejora en las capacidades cognitivas básicas de la IA.
Esta investigación muestra claramente que los modelos de IA todavía tienen mucho margen de mejora en el razonamiento visual, y que en el futuro se necesitan métodos de evaluación más eficaces y avances tecnológicos para mejorar las capacidades cognitivas de la IA. El editor de Downcodes seguirá prestando atención al progreso de vanguardia en el campo de la IA y le brindará informes más interesantes.